可以用import string来引入系统的标准string.py, 而用from pkg import string来引入当前目录下的string.py了
from__future__importabsolute_import
精确除法
from __future__ import division
P27
以真实地显示程序代码区段之间的时序关系以及正在执行程序代码的个别线程与处理内核。
将追踪的部份传送到主机或储存至档案
列印追踪的部份以便文件化及检阅程式码
parser.add_argument("--trace_freq", type=int, default=0, help="trace execution every trace_freq steps")
P57(因为 变量共享 的需求)
在训练深度网络时,为了减少需要训练参数的个数(比如具有simase结构的LSTM模型)、或是多机多卡并行化训练大数据大模型(比如数据并行化)等情况时,往往需要并享变量。另外一方面是当一个深度学习模型变得非常复杂的时候,往往存在大量的变量和操作,如何避免这些变量名和操作名的唯一不重复,同时维护一个条例清晰的graph非常重要。因此,tensorflow中用tf.Variable(),tf.get_variable,tf.Variable_scope(),tf.name_scope()几个函数来实现。例:
import tensorflow as tf
with tf.name_scope('name_scope_x'):
var1 = tf.get_variable(name='var1', shape=[1], dtype=tf.float32)
var3 = tf.Variable(name='var2', initial_value=[2], dtype=tf.float32)
var4 = tf.Variable(name='var2', initial_value=[2], dtype=tf.float32)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(var1.name, sess.run(var1))
print(var3.name, sess.run(var3))
print(var4.name, sess.run(var4))
# 输出结果:
# var1:0 [-0.30036557] 可以看到前面不含有指定的'name_scope_x'
# name_scope_x/var2:0 [ 2.]
# name_scope_x/var2_1:0 [ 2.] 可以看到变量名自行变成了'var2_1',避免了和'var2'冲突
P69 Lab
def preprocess_lab(lab):
RGB颜色空间 基于颜色的加法混色原理,从黑色不断叠加Red,Green,Blue的颜色,最终可以得到白色光。
Lab颜色空间是由CIE(国际照明委员会)制定的一种色彩模式。自然界中任何一点色都可以在Lab空间中表达出来,它的色彩空间比RGB空间还要大。最主要的是这种模式是以数字化方式来描述人的视觉感应,由于Lab的色彩空间要 比RGB模式色彩空间大,意味着RGB以及CMYK所能描述的色彩信息在Lab空间中都能得以影射。Lab颜色空间取坐标Lab,其中L亮度;a的正数代表红色,负端代表绿色;b的正数代表黄色,负端代表蓝色。Lab颜色被设计来接近人类视觉。它致力于感知均匀性,它的L分量密切匹配人类亮度感知。因此可以被用来通过修改a和b分量的输出色阶来做精确的颜色平衡,或使用L分量来调整亮度对比。
颜色模型 (Lab) 基于人对颜色的感觉。Lab 中的数值描述正常视力的人能够看到的所有颜色。
P72 白化(待定,暂不讲)
如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛。
但在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。
# L_chan: black and white with input range [0, 100]
P96
返回一个生成具有正态分布的张量的初始化器。
initializer=tf.random_normal_initializer(0, 0.02)
P104
激活函数def lrelu(x, a):使用了近几年在DL中非常火的ReLU,但效果是否较好不得而知,可尝试使用Sigmoid、tanh,另原先的一些实验中LReLU对准确率并没有太大的影响,也可尝试经改进后可自适应地从数据中学习参数的PReLU和在一定程度上能起到正则效果的RReLU。
这一方面可做大量实验进行验证。
P116 Batch Normalization(批量标准化)
def batchnorm(input):
因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布。这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
P126 批标准化
tf.nn.batch_normalization
P134 反卷积
# [batch, in_height, in_width, in_channels], [filter_width, filter_height, out_channels, in_channels]
# => [batch, out_height, out_width, out_channels]
反卷积的矩阵操作 : C.T * A = B
P155
def rgb_to_lab(srgb):
RGB无法直接转换成LAB,需要先转换成XYZ再转换成LAB,即:RGB——XYZ——LAB。
Function [R, G, B] = Lab2RGB(L, a, b)
(1)P164 RGB转XYZ
设r,g,b为像素三个通道,
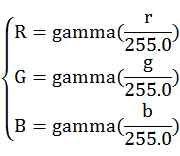
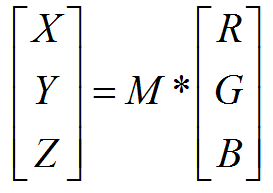
M=
0.4124,0.3576,0.1805
0.2126,0.7152,0.0722
0.0193,0.1192,0.9505
RGB(2)等同于如下公式:
X = var_R * 0.4124 + var_G * 0.3576 + var_B * 0.1805
Y = var_R * 0.2126 + var_G * 0.7152 + var_B * 0.0722
Z = var_R * 0.0193 + var_G * 0.1192 + var_B * 0.9505
本例中:
rgb_to_xyz = tf.constant([
# X Y Z
[0.412453, 0.212671, 0.019334], # R
[0.357580, 0.715160, 0.119193], # G
[0.180423, 0.072169, 0.950227], # B
])
xyz_pixels = tf.matmul(rgb_pixels, rgb_to_xyz)
(2)XYZ转LAB
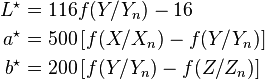
上述公式中,L ,a,b*是最终的LAB色彩空间三个通道的值。X,Y,Z是RGB转XYZ后计算出来的值
# convert to fx = f(X/Xn), fy = f(Y/Yn), fz = f(Z/Zn) (P174)
fxfyfz_to_lab = tf.constant([
# l a b
[ 0.0, 500.0, 0.0], # fx
[116.0, -500.0, 200.0], # fy
[ 0.0, 0.0, -200.0], # fz
])
lab_pixels = tf.matmul(fxfyfz_pixels, fxfyfz_to_lab) +tf.constant([-16.0, 0.0, 0.0])
P331 Generator
def create_generator(generator_inputs,generator_outputs_channels):
(1). 编码器
encoder_1: [batch, 256, 256, in_channels] => [batch, 128, 128, ngf]
P453 模型流程
(1).判别模型D的训练目的就是要尽量最大化自己的判别准确率。当这个数据被判别为来自于真实数据时,标注 1,自于生成数据时,标注 0。

# predict_real => 1
# predict_fake => 0
discrim_loss = tf.reduce_mean(-(tf.log(predict_real + EPS) + tf.log(1 - predict_fake + EPS)))