作者:Jochen Mader
原文链接:https://jaxenter.com/big-data-becomes-fast-data-130824.html
大数据(Big Data)正在悄然发生改变,Hadoop、Storm、Pig、Hive已不再是业界的宠儿,它们的热度正被一个强大的组合夺走——Fast Data和SMACK。那么问题来了:目前处理数据的做法有什么问题?Fast Data和Big Data有什么不同?什么是SMACK?
在2014年I/O大会上,Google宣布用一种全新的数据流架构取代MapReduce,这一决定引起了极大震动,毕竟在那时Hadoop仍然被视为一项“创新”技术。经过几篇启发性的博客发布以及一系列激烈的讨论,MapReduce“退休”的决定才得以平息,一些公司逐渐开始认识到,许多技术对于数据分析期限的要求对于业务来说是受限的。我们需要新技术,让big data变得更快一些。
In the beginning there was Lambda
在很长时间里,大数据领域都显得有些令人困惑,各种框架和技术设施组件交织在一起,HDFS、Ceph、ZooKeeper、HBase、Storm、Kafka、Big、Hive……这些组件,大多数都是“专化”的,仅提供部分预期功能,只有把它们组合起来,才能完成较为复杂的任务:一部分框架是立即响应式的,包括Storm、Samza、CEP引擎,以及Akka、Vert.X、Quasar等reactive框架,而另一部分框架由需要一些时间响应的框架组成,基于MapReduce,例如Pig和Hive。当这两种框架同时出现的(通常如此),便形成了一种特定的架构风格,Nathan Marz由此提出了Lambda Architecture,如下图所示:

Real Time
谈大数据,就不得不提到Real Time。Real Time本身是一个容易产生误解的词,这个术语原指系统在设定timeframe内交付结果的能力,例如breaking controllers、医疗设备、卫星的很多部分等都需要Real Time的能力,以防止重大事故的发生。汽车的制动装置需要在司机踩下刹车踏板时快速反应,否则很可能会导致交通事故。事实上,这不是一个“尽可能快的给出答案”的问题,而是“答案会在规定时间段内出来”的问题。或许,在我们描述Big Data和Fast Data应用的目标时,用“Near Time”一词会更恰当一些。
在Near Time基础上,incoming data(1)经由2层layer处理。在Batch layer中,已部署的原始数据会进行long distant runner analysis,分析结果将被提供给Serving layer(4),client可在这一层请求数据。Speed layer(3)牺牲了性能持久性解决方案,在主存储器中执行大部分任务。由于它不能同时留存所有数据,必须集中于某一个子集上,特定结果也因此可以更快速的得以确定。最后,总数据集也将传递至Serving layer,可与Batch layer处理结果相关联。进一步说,Serving layer和Speed layer存在双向关系,例如分布式计数器等特定值可以作为分布式存储器内数据结构访问,并实时保存。
Redundant logic can be problematic
在Batch layer、Speed layer、Serving layer三层上,已有很多框架取得了成功,直接导致了对于大数据的更高要求——更快、更灵活的数据分析,结果展现应该是多维的,包含秒、分钟、小时、天等。MapReduce很快就触到了它的天花板,由于它在灵活性和响应时间上的不足,越来越多的分析放在了Speed layer执行。然而这并不会减少Batch layer中的逻辑。由于在内存中进行处理受制于主存储,许多研究仍然需要分批进行。
在编程模块不兼容的情况下,需要我们多次执行大量逻辑,因而在评估相同数据源时,这种冗余可能会导致出现截然不同的结果。从这个角度来说,一个统一的、涵盖广泛分析的编程模型是极有必要的。
The Birth of Fast Data
加州大学伯克利分校AMPLab在2010年开源了Spark,并在2013年将Spark捐赠给Apache Software Foundation,自此Spark迎来了飞速发展。关于Spark的一切基本都是围绕着RDD(分布式弹性数据集了一个全新)展开:分布式、弹性、并行化数据结构。这些特性可以使许多不同模块结合使用:
• 图形处理(GraphX)
• Spark SQL,用于处理来自各种结构化数据源(Hive,JDBC,Parquet等)的数据
• 流媒体(Kafka,HDFS,Flume,ZeroMQ,Twitter)
• 基于MLib的机器学习
除了Scala,Spark还支持Python和R语言,以便数据工程师可以容易的上手。Spark可以和很多现有的数据源及API结合,这也是其迅速流行的原因之一。
结构化数据源和数据流的组合让大部分Speed layer和Batch layer组合成为单个接口成为可能。分析可以在任何resolution下执行。Spark开发人员甚至可以在非常惊人的timeframe内部署和开发Spark工作。 Spark的论据很清楚:
• 可扩展性 – 可处理数百万个数据集
• 足够快,可在near time提供结果
• 适用于任何持续时间的分析
• 统一且易理解的的编程模型来处理各种数据源
但即使Spark也有局限性,仍然需要数据传输工具及数据持续性工具。
Enter the SMACK
SMACK堆栈即将大数据不同领域的已知技术组合成为的一个强大的基础框架,是Spark、Mesos、Akka、Cassandra、Kafka的缩写。
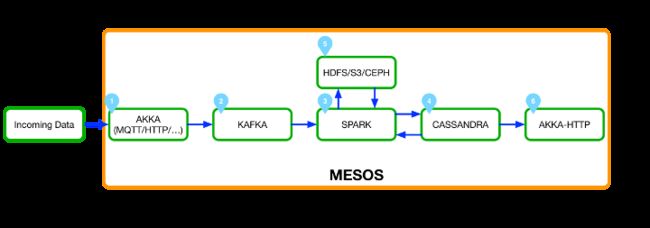
Fig 2: SMACK堆栈:Fast Data基础架构的坚实基础
Apache Mesos [2]是分布式系统的内核,代表一组机器上的抽象层。除非是在一个节点上部署应用程序,还有一个需求描述(CPU数量,所需的RAM等),传递给Mesos并分发到适当的机器。 这样,几千台机器可以很容易地被特别的使用。 Mesos是堆叠的中枢神经系统。SMACK堆栈组件均可在Mesos中使用,并且完全集成到其资源管理中。此外,商业版本的Mesosphere已经在Amazon AWS和Microsoft Azure上可用。可以在短时间内构建云数据中心。
Akka是reactive framework,几年来已发展成为分布式、弹性应用的首选框架之一。在SMACK中,Akka主要用于ingestion rang及Serving layer的access layer。
Cassandra[4]也归属于Apache,是一个分布式、弹性可扩展的数据库,可以存储大量的数据。Cassandra支持跨多个数据中心的分发及容错,被用作于SMACK堆栈中的主数据存储。
Apache Kafka[5]通常被认为是一种分布式消息传递系统 - 这在大多数情况下是正确的。 事实上,它只不过是一个分布式的提交日志。 其简单的结构允许用户在多个系统之间传输大量数据并伸缩。
它们组合在一起,构成了FAST DATA基础设施的坚实基础(图2):Akka(1)处理incoming data,如MQTT事件、点击流或二进制文件,并将其直接写入Kafka(2)中的相应topics。而数据持久允许我们决定不同结果的速度。各种Spark jobs(3)处理数据并将数据interpret为不同的resolutions:
原始数据持久性:将传入的原始数据写入S3、HDFS或Ceph的作业,并准备进行后续处理。
Speed layer:实现快速分析,结果以秒为单位。
Batch layer:long-term分析或机器学习
结果写入HDFS(5)和Cassandra(4),可用作其他作业的input。 最后,Akka作为HTTP layer来显示数据,如作为Web界面。
Automation clinches
除了技术核心部件之外,自动化是确定真正快速数据平台成功或失败的关键。而Mesos已经为此提供了许多重要的基本组件。 然而,我们将继续需要Terraform、Ansible、Kubernetes等工具和综合监控基础设施。在这一点上,应该明确我在哪里:没有DevOps,很难实现目标。 开发商和运营商之间的合作对于一个系统而言至关重要,该系统旨在弹性扩展并在数百台机器上工作。
To Scala or not
SMACK主要组件都是Scala,或者是Scala-like的——
- Akka:Scala,primary API in Scala,也可以用JAVA;
- Spark:Scala,primary in Scala,Python and R;
- Kafka:Scala,集成于Spark;
- Cassandra:Scala; 交互主要通过CQL和Spark集成进行
对于SMACK开发人员来说,Scala是绕不过去的,也是务实的选择。
Conclusion
事实上并不是说Hadoop危在旦夕,可以预见的是未来一段时间里,HDFS、YARN、ZooKeeper、Co. 仍将是大数据的重要部分。重点在于我们使用大数据技术的方式,例如Spark让现有组件在统一的编程模型中使用,当然它知识一个工具,背后伸侧过的目标是应对“Fast Data”:
低门槛
Speed layer和Batch layer之间的差异消失
简化探索性分析
更简单便捷的新任务部署
让现有基础设施变得易用
而SMACK这样的组合方式,得益于各技术的成熟度、自动化、易用性,它的灵活性是很难被击败的。
快速上手SMACK
查看[云框架]SMACK大数据架构,快速上手SMACK!