【编者按】你会怎么选择数据库,是关系数据库、XML 数据库、资源描述框架(RDF),还是图形数据库?本文的第1部分深入而生动地探讨了各种选择。在第2部分,将深入介绍使用 Neo4j 的注意点。文章系国内 ITOM 管理平台 OneAPM 编译呈现。
过渡到 Neo4j 之后的经验和教训
下面介绍一些有关运行 Neo4j 的实用技巧:
1. 如果你是 Java 商城,请嵌入式地运行 Neo4j
Neo4j 是本地 Java 平台,我们又是 Java 商城,用 Neo4j 相当合适。嵌入 Neo4j 让我们不用再进行 REST 调用,这对于安全来说确实很重要。有关进行 REST 调用的进一步危害,请观看这段有关 REST 安全漏洞的 JavaOne 讨论。
嵌入式地运行 Neo4j 还为我们大幅降低了复杂性。我们可以直接在进程中调用 Neo4j API,从而快速了解 Cypher 语言,以便运行 Cypher 和 Java API 这两者的结合体。同时我们再也不需要托管和非托管的扩展了。
2. 摸清自己的优势
摸清自己的优势和所选择的工具的优势,这一点极为重要。用工具来做不适当的事,效果会大打折扣。
本地图形数据库在关系方面的表现确实很好;在图形中找到切入点,然后按照需要深入地研究各种关系,这在 Neo4j 中快得惊人。但如果想要在单个节点之外进行复杂的多值属性全文检索,效果就大打折扣了 —— 但我们选择图形数据库并不是为了做这个。
3. 了解查询时会发生哪些事情
了解查询时会发生哪些事情,这一点也极为重要,这能够优化 Cypher 语言。
请看下面这个非常简单的查询。我想要找到 Franklin Country 所有拥有狩猎执照的男性,并且执照上的地址需要和此人的家庭住址相匹配,以便我们确认这是同一个人。
我有一个人员节点,一个执照节点,还有一个位置节点,每个节点上都有各种不同属性:

数据库要做的第一件事就是找到切入点(可能有多个切入点),然后图形从切入点展开搜索。寻找切入点通常是个让人头痛的问题。为此要使用带有静态索引集的基于规则的规划程序,这一软件已于近期升级为基于费用。这虽然还不够完美,但无疑已经朝着正确的方向前进了一大步。
索引
索引基本上会复制数据库中的信息片段,这样有利于它迅速找到节点。在本例中,只使用信息片段来确定切入点。虽然不是必须要使用索引,但它确实能派上用场。如果要在特定的节点属性上进行检索,在节点上设置一个索引会是个好办法,即使这会占用磁盘空间。
索引分为两种:schema 和 legacy。Schema 索引是最新版,使用内部自定义的 Neo4j 内置索引,目前是默认设置。
一旦利用 Cypher 或 Java API 创建 schema 索引后,这些索引就会自动由数据库维护。例如,如果你想在每个带有“人员”标签和“性别”属性的节点上创建索引,当你创建新节点、更改节点值或删除节点时,数据库将自动对其进行更新。这时你也可以设置限定条件,比如必须存在属性或属性必须是唯一的。
Legacy 索引是 Lucene 索引,是较早的版本但尚未弃用。可以通过配置文件、Neo4j 属性文件、Java API 或 Cypher 来设置 legacy 索引。Legacy 索引使用的是 Lucene 而非 Neo4j 专有索引机制。我们在用 Neo4j 时几乎没有什么漏洞,而每次遇到的漏洞基本都和 legacy 索引有关。即使是这样,有时候这些索引也是必要的。
Apache Luke 是一款非常不错的开源工具,用户可以用它直接查看和搜索 Lucene 索引。这也帮助我们修复了 legacy 索引中的异常行为。
自动索引与手动索引
Legacy 索引有两种用法:自动索引和手动索引。我建议使用自动索引,因为它更容易维护。基本上只要设置一次(可以在配置文件中设置也可以通过 API 设置),然后设为在特定类型的节点上为特定类型的属性编写索引。自动索引还能够在必要时轻松重建索引。
但是用户无法指定是哪种类型的索引。在 Lucene 中,schema 存在不同索引类型,例如字符串、区分大小写,以及数值,这些都是物理上独立的索引。
如果你在查询 Lucene 时想要使用这些索引,必须要做的第一件事就是告诉 Lucene 要使用哪个索引。但如果进行自动索引,Neo4j 可以根据你要编写索引的第一个对象来选择使用哪个索引。例如,如果你设置的第一个索引是蓝色,Neo4j 就会明白蓝色是字符串,然后会永久性地将蓝色放在字符串索引中。
如果你能很好地控制收到的数据,这一索引方式效果会很不错。但我们的系统没有这样。我们从许多不同的来源接收数据,所以收到的“blue”(蓝色)属性可能会指年龄。但如果这一属性是最先收到的,Neo4j 就会把年龄作为基于字符串的属性而不是数值属性来编写索引,如此一来,之后就没法按照我希望的方式展开进一步比对和排列了。在这种情况下,只能手动创建索引。
使用自动索引的另一个好处是,如果目录无故损坏,很容易就能修复目录。可以暂停整个数据库,进入 Lucene 索引目录,删除此目录,重启数据库,然后 Neo4j 会为所有节点重新编写索引。但如果已经进行了手动索引,你只能返回,然后为所有节点重新编写索引。
范围查询
下面一系列幻灯片显示了范围查询:
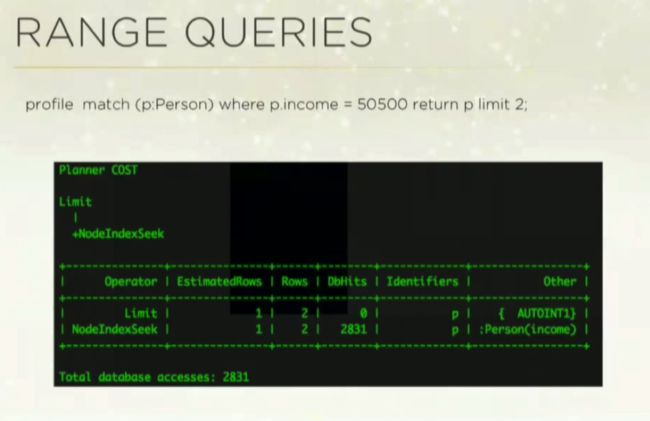
我想查询“profile”(个人信息),所以我把 PROFILE 放在查询内容的前面。我想找到收入为特定数值(50500)的所有人群并且只返回最前面的两个结果。
这段代码表明,我已经有了某人的收入索引,规划程序的限值是 2。NodeIndexSeek 用这一索引来查找数值,从一个拥有 22 万人的样本数据库中进行了大约 2800 次数据库访问。
在接下来的范围查询中,我准备查找收入低于 50500 的人:
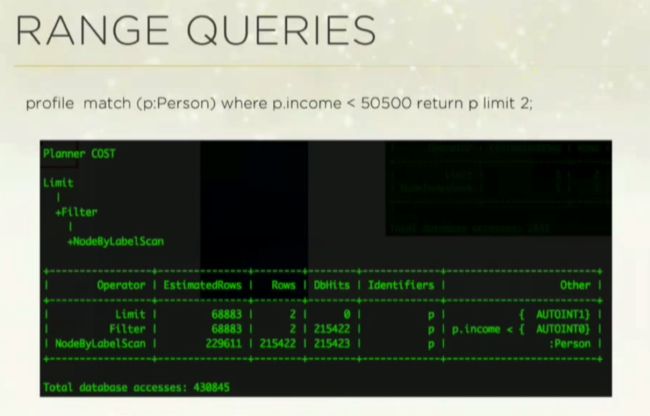
在这次的查询中,我们执行了 NodeByLabelScan,由于没有使用索引,我们进行了多达 43 万次数据库访问。在 Neo4j 第 2.3 版之前,schema 索引不支持范围,所以你必须得用 legacy 索引,然后直接查询 Lucene 索引,才能发挥作用。
第 2.3 版修复了这一问题;现在有了 NodeIndexSeekByRange,可在 schema 标签上提供范围索引:

4. 不要使用内部节点 ID
使用当前节点 ID 是个很大的诱惑,但这种做法非常不可取,这是因为在某些时刻,这种做法会导致数据库内容被删除。请阅读这篇介绍,了解更多相关内容。
Neo4j 使用增量日志。如果你删除了某个节点,最后系统会翻转节点 ID,这样你就可以重复使用这些数字。我们结合使用了节点标签和随机选择的 UUID,这样如果你的 API 始终暴露在外,就可以提供额外的安全保障。
5. 数据建模很重要
数据模型的重要程度至少和查询相当。下面的说明很有用:可以通过多重关系类型或关系上的属性来为部分关系建模。两种方法似乎同样合理,但它们的性能表现可能大相径庭。一定要了解一下 GraphAware 对这一内容的介绍。其区别在于,一方定义不同类型的 person 和 place 之间的关系……

……而另一方则表示有三种不同的属性类型:
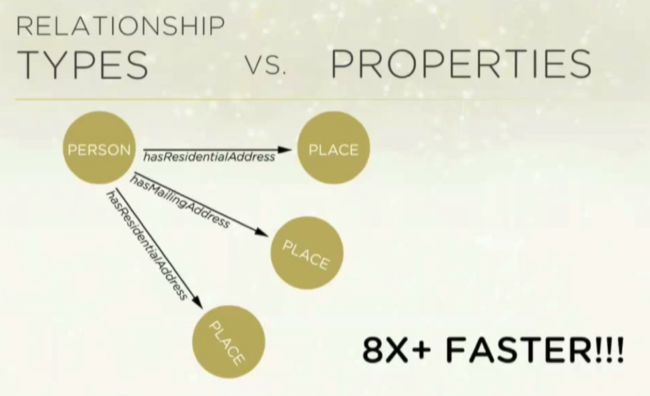
性能表现提升了八倍。上述 GraphAware 的文章深入详细地解释了这一概念。
6. 优化性能
EXPLAIN 和 PROFILE 绝对是你的良师益友。别担心 Java API,而查询规划程序还很年轻,在许多情况下都比 Cypher 要快。如果你要设定基准,一定要以温备份数据库设定基准。这样就能加载 Neo4j 的数据库缓存。
7. 一定要交流!
Neo4j 拥有强大的支持社区,包括谷歌论坛、Slack 协作频道、Stack Overflow 网站和非常出色的支持团队。
8. 在工具栏里添加下面的代码
借助下面的样板代码,可以检查数据库中的每个节点并修复所有问题。这一示例有时会抓取关系,但你也可以对节点或其他限定条件进行同样的操作。
不管怎样,它都能事务性地依次通过数据库中的所有节点。在本例中,每个事务是 90000 次操作,如果有需要,还可以批量更改整个数据库:

本文系 OneAPM 工程师整理呈现。OneAPM 能为您提供端到端的应用性能解决方案,我们支持所有常见的框架及应用服务器,助您快速发现系统瓶颈,定位异常根本原因。分钟级部署,即刻体验,性能监控从来没有如此简单。想阅读更多技术文章,请访问 OneAPM 官方技术博客。
本文转自 OneAPM 官方博客
原文地址:https://dzone.com/articles/from-good-to-graph-choosing-the-right-database