一.JXLS简介
在很多涉及到某种报表功能的Java程序中都需要生成Excel表格。目前通过Java来操作.xls文件最完整的类库是Apache POI类库,但是当需要创建多种自定义的复杂Excel报表的时候就会出现问题,这些Excel报表一般都带有多种格式和可扩展功能,在这种情况下,你就不得不写一大堆Java代码来创建报表的规则集(workbook),规则集一般包含所有要求的格式,公式,其他特定的设置和正确的Java对象集的数据出口。这些代码一般都是难以调试,任务也常常变得容易出错并且耗时。
另外一个问题是有很多Excel组件都没有提供的API。幸运的是POI API读取Excel文件,可以保持它原有的格式,然后根据需要进行修改。很明显,用一些Excel编辑工具来创建所有格式正确的报告模板然后指定真实的数据应该放置的地方,会容易很多。JXLS是实现这种方法并且只用几行代码就能创建极其复杂的Excel报表。你只需要用特定的标记来创建一个带有所有要求的格式,公式,宏等规则的.xls模板文件来指定数据放置的位置然后再写几行代码来调用JXLS引擎来传递.xls模板和导出的数据作为参数。
除了生成Excel报表功能,JXLS还提供了jxls-reader模块,jxls-reader模块会很有用,如果你需要解析一个预定义格式的Excel文件并在其中插入数据的话。jxls-reader允许你用一个简单的XML文件描述解析规则,读取Excel文件和你的各种JAVA对象(population of yourJava objects)的所有其他工作都会自动完成。
二.JXLS安装
为了使用JXLS引擎,你必须把jxls-core.jar添加到项目的classpath,如果计划使用JXLS来读取.xls文件,那么你必须还要把jxls-reader.jar加入到项目的classpath中。
如果你用Maven来构建你的应用程序,你可以在你的pom.xml文件中配置指定要求的JXLS模块的依赖,让它们可以从Maven仓库下载。
下面的Apache类库也要求添加到项目的classpath中
●POI 3.6 or higher
●Commons BeanUtils
●Commons Collections
●Commons JEXL
●Commons Logging
●Commons Digester
注意:当前JXLS版本可能无法正常地与较早的POI库版本工作,因此,如果你必须要使用较早版本的POI(prior3.2)使用较老版本的JXLS就行了
三.JXLS参考
1.简介
这部分描述在.xls模板文件的中的对象属性访问语法,如果想让JXLS引擎进行正确的处理.xls模板文件就必须使用规定的语法。
接下来的部分假设我们有两个相互依赖的JAVA beans,类型分别为Department和Employee,在代码中像这样被传递到XLSTransformer中:
Departmentdepartment;
...//initialization
Map beans =new HashMap();
beans.put("department",department);
XLSTransformertransformer = new XLSTransformer();
transformer.transformXLS(xlsTemplateFileName,beans, outputFileName);
- 属性访问
2.1.基本属性访问
使用下面的语句来访问Excel单元格中简单的bean属性:
${department.name}
在上面这个语句中,JXLS引擎会通过关键字department在当前bean映射下搜索这个bean,然后会尝试获取这个bean的name属性的值并把它放到相应的Excel单元格中。
同理,我们可以访问更加复杂的属性,例如,要输出这个department中的属性chief中的name属性的值,我们可以用:
${department.chief.name}
访问任何深度的对象属性都是可以的。例如
${bean.bean1.bean2.bean3.bean4.bean5.bean6.bean7.bean8.bean9.beanX.property1}
2.2多个属性在一个单元格中
在一个单元格,我们可以连接几个属性。例如:
Employee:${employee.name} - ${employee.age} years
这样,我们得到的输出是:
Employee: John -35 years
其中${employee.name}的值是John,同理${employee.age}的值是35.
3.使用标签
JXLS允许在模板中使用预定义的XML标签来控制XLS转换行为。
3.1 jx:forEach标签
标签的典型用法如下:
${department.name}| ${department.chief}
jx标签可以相互嵌套使用
如果你把jx:forEach标签的开始标签和结束标签放在同一行的话,JXLS会在同一行上重复在jx:forEach标签的开始标签和结束标签之间的Excel单元格。
目前,如果你想要用jx:forEach标签重复Excel的行,那么你必须把jx:forEach标签的开始标签和结束标签放在不同的行,把要重复的行包含在中间,jx:forEach标签所在行的所有单元格都会被忽略。
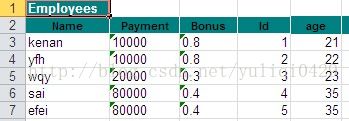
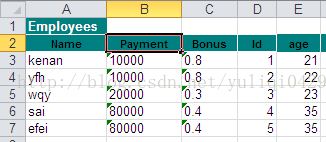
以下是一个实例的截图:
3.1.2 forEach标签的数据分组
jx:forEach标签可以通过一个底层bean的属性对数据集合的分组,这可以通过jx:forEach标签的groupBy and groupOrder属性完成,groupBy用于指定一个属性进行分组,groupOrder用于指定各个分组排列顺序。例如:
Age: ${group.item.age}
${employee.name} |${employee.payment} |${employee.bonus}
在这个例子中,我们把employees按age属性分组,当遇到groupBy属性的时候,JXLS内部执行分组并且放置名为group的新的bean到上下文中,这个新的bean是很简单-它包含两个属性:item属性和items属性,item属性是分组中当前处理的bean;items属性
代表这个分组中所有bean的集合。
正如你看到的,在这个例子中我们首先使用下列语句显示一些关于当前分组age属性的信息
Age:${group.item.age}
之后,我们使用内部标签来实现迭代并显示所有分组中的记录
${employee.name}| ${employee.payment} | ${employee.bonus}
默认情况下,如果没有groupOrder属性组的顺序将被按“原先”的顺序保留,以便这些分组的排列顺序跟原先的集合中一样,如果你需要按升序或是降序排列排列这些分组,那么你可以将groupOrder属性相应地设置为ASC或DESC
在使用groupBy属性的情况下,jx:forEach标签的var属性将被忽略
3.1.3forEach标签的筛选功能
你可以用jx:forEach标签的‘select’属性来选择把哪些记录包含在循环中,例如,如果我们想只包含工资高于 2000元的员工,我们可以使用下面的语句:
${employee.name}| ${employee.payment} | ${employee.bonus}
3.14 forEach标签的varStatus 属性
jx:forEach标签支持varStatus属性,varStatus属性用来定义一个循环状态的名字,在每一次迭代中,循环状态对象会被传递到bean上下文。循环状态对象是LoopStatus类的一个实例,LoopStatus类有一个单一(静态)的'index'属性用来确定当前记录在集合中的索引值(索引值从0开始)。
${status.index}|${employee.name}|${employee.payment}|${employee.bonus}
3.2 jx:if标签
典型的标签的用法如下:
Chief Name: ${department.chief.name}
jx:if标签可以基于某些条件来排除某些行或是某些列,如果你把jx:if标签的开始标签和结束标签放在同一行的话,JXLS会根据test的条件来处理或删除包含在标签提内的列;如果你把jx:if标签的开始标签和结束标签放在不同行的话,JXLS会根据test的条件来处理或删除包含在标签提内的行。
3.3 jx:outline标签
标签可以将特定的行组成一组。例如:
图3模板 ![Uploading 4_255623.png . . .]
标记有一个可选的布尔类型的属性“detail”声明结果初始化的状态-它们应该展开显示还是折叠显示,默认值是false即分组的行会被折叠显示(隐藏)
3.4 jx:out标签
标签的用法如下:
图.6 模板文件
ession" />
- 执行SQL查询
在许多企业级应用中,Excel报表起着非常重要的作用,现在JXLS可以直接吧SQL查询语句直接写入.xls模板文件中,这样在模板进行转换的时候,SQL语句会被执行,所有的查询结果都会正确地填入Excel报表中。
要执行SQL查询,并在Excel文件中显示查询结果,你必须在模板进行转换之前把一个特殊的bean写入bean上下文,这个特殊的bean要实现ReportManager接口。目前这个接口只有一个方法:
public Listexec(String sql) throws SQLException
这个方法的参数是一个SQL查询语句,执行结果,返回一个list(list的泛型是bean)
JXLS对这个接口提供了一个默认的实现,叫做ReportManagerImpl,ReportManagerImpl使用owSetDynaClass来把ResultSet对象封装到对象集合中,下面是这个类的用法:
Connection conn =...// get database connection in some way
Map beans = newHashMap();
ReportManager rm =new ReportManagerImpl( conn, beans );
beans.put("rm",rm);
InputStream is =new BufferedInputStream(new FileInputStream("reportTemplate.xls"));
XLSTransformertransformer = new XLSTransformer();
HSSFWorkbookresultWorkbook = transformer.transformXLS(is, beans);
ReportManagerImpl构造函数将数据库连接对象和bean的map作为参数传递给XLSTransformer,然后把ReportManager对象放到bean上下文中使用“rm”作为key。这意味着,我们可以执行任何SQL查询语句通过把它作为参数传递给rm.exec()方法,例如:
${rm.exec("SELECTname, age FROM employee")}
通常情况下,这个语句和jx:forEach标签结合起来使用来遍历bean的集合(ResultSet)并把它显示在Excel文件中,例如:
${employee.name}| ${employee.age} | ${employee.payment}
可以使用jx:forEach标签的groupBy属性来实现按某些列的值进行分组查询。
以下是一个实例:
. . .//主要代码
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
conn=DriverManager.getConnection(url,"gaps32", "gaps32");
Map beans = new HashMap();
ReportManager rm = new ReportManagerImpl( conn, beans );
beans.put("rm", rm);
XLSTransformer transformer = new XLSTransformer();
transformer.transformXLS(report, beans,reportDest );
conn.close();
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
} catch (SQLException e2){
e2.printStackTrace();
}//. . .
4.2 依赖查询
如果使用jdbc的数据库驱动话,你可以给ReportManagerImpl传递任何SQL语句,你可以把在一个查询中使用另一个查询的结果,你可以把一个查询的结果放到bean上下文中,当在依赖查询需要使用这个结果的时候就可以使用了。依赖查询(子查询)典型的用法可以用在两个jx:forEach标签,当其中一个标签嵌套在令一个标签里面的时候,下面是一个简单的例子:
Department:${dep.name}
Name |Payment | Bonus | Total
${employee.empname}|${employee.payment}|${employee.bonus}|$[B23*(1+C23)]
在这里我们把第一次查询到的department信息放到上下文中以dep作为key,然后在内部的jx:forEach标签中使用
你要可以从上面的语句中了解到如何在SQL查询语句中使用单引号。
4.4 JDBC结果集
虽然JXLS没有为JDBC查询结果集设计的数据出口,但是查询结果集可以使用Commons BeanUtils的动态类很容易进行输出,XLSTransformer有两种方法可以导出结果集中的数据,第一种使用org.apache.commons.beanutils.RowSetDynaClass,第二种是基于类net.sf.jxls.report.ResultSetCollection。
4.4.1基于RowSet的输出
当你构建一个org.apache.commons.beanutils.RowSetDynaClass类的实例的时候,底层数据被复制到内存中的动态bean集合中,这个集合就代表结果,所以你可以马上关闭结果集,通常当你处理实际数据之前,结果集就已经关闭了,这种方法的缺点就是你必须消耗一定的性能和内存来复制这些结果数据。
使用这种方法首先你必须构建一个新的RowSetDynaClass的实例,并把结果集传递给它。
ResultSetresultSet = ...
RowSetDynaClassrowSet = new RowSetDynaClass(resultSet, false);
第二个构造函数的参数表示属性名称在动态bean的结果集中不应该小写。在你初始化RowSetDynaClass的实例之后,你可以调用它的getRows()方法来获得动态bean的结果集,并用通常的方法输出。
Map beans = newHashMap();
beans.put("employee", rowSet.getRows() );
XLSTransformertransformer = new XLSTransformer();
transformer.transformXLS(templateFileName, beans, destFileName);
下面是一个实例:
…//
Statement stmt = conn.createStatement();
String query = "SELECT * FROM SAI";
rs = stmt.executeQuery(query);
Map beans = newHashMap();
RowSetDynaClass rsc = new RowSetDynaClass(rs,false);
beans.put("employee", rsc.getRows());
XLSTransformer transformer = new XLSTransformer();
transformer.transformXLS(report, beans,reportDest );
conn.close();//…
4.4.2 结果集输出
如果你不想在内存中加载所有的结果集数据,并同意在处理数据的时候一直保持数据库连接不断开的话,你可以使用net.sf.jxls.report.ResultSetCollection类,这个类以ResultSet(结果集)为参数并实现了Collection接口来操作底层数据,反过来ResultSetCollection使用org.apache.commons.beanutils.ResultSetDynaClass来返回检索到的数据作为动态对象。
下面是net.sf.jxls.report.ResultSetCollection 类的使用:
ResultSetCollectionrsc = new ResultSetCollection(resultSet, false);
beans.put("employee", rsc );
第二个构造函数的参数,表明属性名称在处理之前不应该小写。
下面是一个实例:
Class.forName("oracle.jdbc.driver.OracleDriver");
conn=DriverManager.getConnection(url,"gaps32", "gaps32");
Statement stmt=conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,ResultSet.CONCUR_READ_ONLY);
String query = "SELECT NAME, AGE, PAYMENT, BONUS, IDFROM SAI";
rs = stmt.executeQuery(query);
Map beans = newHashMap();
ResultSetCollection rsc = new ResultSetCollection(rs,false);
beans.put( "employee", rsc );
XLSTransformer transformer = new XLSTransformer();
transformer.transformXLS(report, beans,reportDest );
注:不能使用Statement stmt=conn.createStatement();不然会出现异常(对只转发结果集的无效操作: last "的异常)应该使用Statement stmt=conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,ResultSet.CONCUR_READ_ONLY);
分析:异常出现于移动结果集的指针时,原因是在生成statement对象的时候提供的参数不同无参数的那个方法使用的是默认参数,statement执行后得到的结果集类型为 ResultSet.TYPE_FORWARD_ONLY.这种类型的结果集只能通过rs.next();方法逐条读取,使用其他方法就会报异常. 如果想执行一些复杂的移动结果集指针的操作就要使用其他参数了
4.5 在报表中插入图表
List staff = newArrayList();
staff.add(new Employee("Derek", 35, 3000, 0.30));
staff.add(new Employee("Elsa", 28, 1500, 0.15));
staff.add(new Employee("Oleg", 32, 2300, 0.25));
staff.add(new Employee("Neil", 34, 2500, 0.00));
staff.add(new Employee("Maria", 34, 1700, 0.15));
staff.add(new Employee("John", 35, 2800, 0.20));
staff.add(new Employee("Leonid", 29, 1700, 0.20));
Map beans = newHashMap();
beans.put("employee", staff);
XLSTransformer transformer =new XLSTransformer();
transformer.markAsFixedSizeCollection("employee");
transformer.transformXLS(templateFileName, beans,destFileName);
源码文件和普通的文件一样。
在Excel模板中插入图表,在工具栏选插入-----图表,然后选择图表的类型,有柱状图,饼状图等等,插入后,选中图表右击选择“选择数据”然后对图表中的数据进行设置,(横轴和水平轴)插入图表有一个缺陷,图表中的数据条数要固定,而且要预先设置好,不能在运行的时候确定,然后如果数据量太大的话,显示会很拥挤。
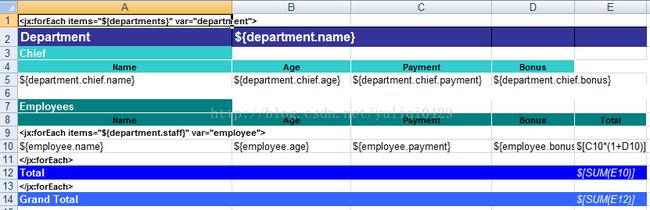

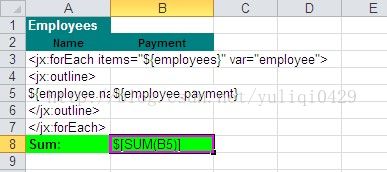

 图.6 模板文件
图.6 模板文件