周志华老师在《机器学习》里这样评价 EM算法:EM算法是最常见的隐变量估计方法,在机器学习里有着极为广泛的用途,例如常被用来学习高斯混合模型(Gaussian mixture model,简称GMM)的参数。K均值算法就是一个典型的 EM算法。
EM算法是怎样的隐变量估计方法?
《机器学习》这样描述隐变量估计方法(见7.6):我们一直假设训练样本所有属性变量的值都已被观测到,即训练样本是完整的。但在现实应用中往往会遇到“不完整”的训练样本,例如由于西瓜的根蒂已脱落,无法看出是“卷缩”还是“硬挺”,则训练样本的“根蒂”属性变量值未知。未观测变量的学名是“隐变量”(latent variable)。EM(Expectation-Maximization)算法 [ Dempstert et al.,1977] 是常用的估计参数隐变量的利器,它是一种迭代式的方法。EM算法使用两个步骤交替计算:第一步是期望(E)步,利用当前估计的参数值来计算对数似然的期望值;第二步是最大化(M)步,寻找能使 E步产生的似然期望最大化的参数值。然后,新的到的参数值重新被用于 E步,直至收敛到局部最优解。
2008年自然杂志发表过这样一篇文章 What is the expectation maximization algorithm?(什么是EM算法,什么是EM算法 ),用投硬币的例子介绍了 EM算法,硬币是常见的物品,用来理解 EM算法可能会更容易一些。
这篇科普文基本没有什么“像样”的公式,对于受过专业训练的人而言,公式或许更有利于他们理解算法的基本原理,但对普通读者而言,太多的公式,只会吓走他们。
如下图所示,有两个硬币 A和 B,其中一个的密度不是很均匀,出现正面的概率会大一些,我们想知道这个硬币是哪一个。然后我们做了下面这个试验,随机取出一枚硬币,记下是 A硬币还是 B硬币,并连续抛10次,记录下每次抛出的结果(正面或背面),这样的试验总共做了5次,结果如下图。
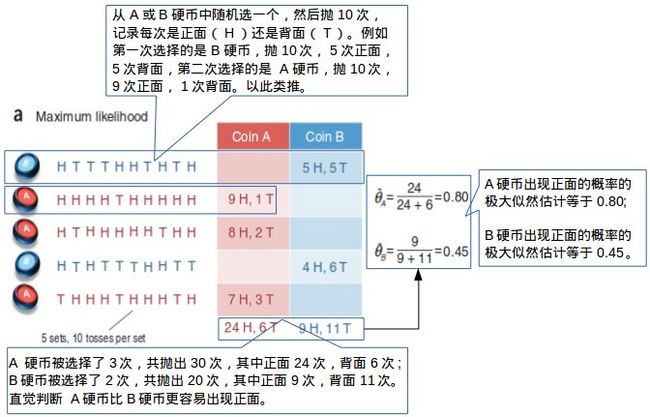
很明显,如果我们记录好每次抛的是哪一个硬币,以及出现正面或背面的结果,我们就能够用某种方法(例如极大似然估计法)估计出每个硬币出现正面的概率,这个例子中 A硬币出现正面的概率估计值是0.8,B硬币出现正面的概率估计值是0.45。通过试验和计算,我们可以判断出哪一个硬币更容易出现正面,以及相应的概率估计值。
然而,生活并不是那么如意的。如果做试验的伙计忘记了记录每次抛的是哪一个硬币,那么他就无法从记录中区分哪一些是来自 A硬币的,哪一些是来自 B硬币的,也就是说,我们没办法估计 A硬币或 B硬币出现正面的概率。
难道只能重新做试验吗?办法是有的,例如 EM算法。
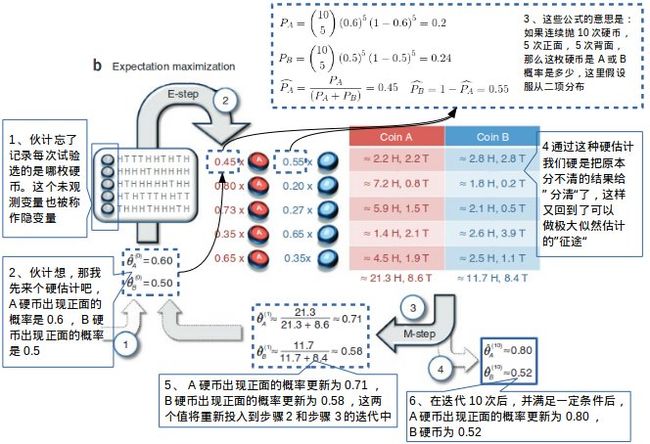
如下图所示,由于没有记录每次试验选的是哪枚硬币,这个未观测变量就是隐变量,我们只得到一堆 H(正面)或 T(背面)的记录,但是我们仍然可以通过某种方法估计出 A硬币和 B硬币在每次试验中出现的概率值。例如投硬币试验可以看作多重伯努利试验,如果我们先给出 A硬币和 B硬币出现正面概率的硬估值(更准确的说是初始值),再结合每次试验出现 H或 T的次数,通过二项分布公式,我们就可以得出 A硬币和 B硬币在每次试验中出现的概率估计值(E-Step)。通过这种办法,我们把之前因为隐变量无法分清的试验结果给“分清”了,这样我们就又回到了上图中极大似然估计的路线上,而极大似然估计方法又帮助我们更新了 A硬币和 B硬币出现正面的概率估计值(M-Step),这对值较之前的硬估值有了很大改变,但我们仍不满意这样的结果,把这对值再次投入到 E-Step 和 M-Step 中。经过多次迭代后,在满足一定条件下,输出 A硬币出现正面的概率估计值是0.80,B硬币出现正面的概率估计值是0.52,这和上图有完整数据情况下用极大似然估计方法得到的结果,已经非常接近了。
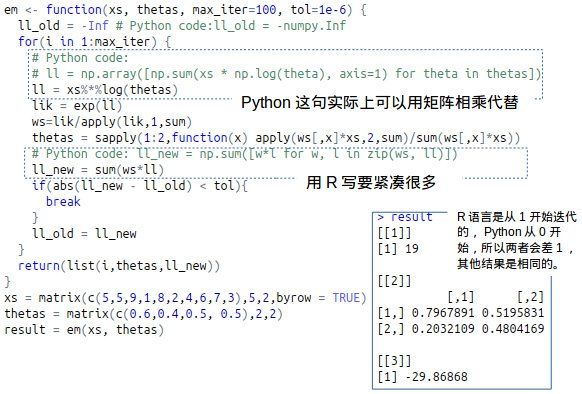
关于 EM算法的实现,参考的是杜克大学的计算统计学网站 EM算法实现。该网站提供了五种输出一致的Python脚本,我们从中选择一种比较简洁的脚本,如下图所示。

我们把这段 Python脚本改写成 R脚本,看看可不可以更加简洁一些。
Fong Chun Chan's Blog 提供了用 EM算法求高斯混合分布参数的 R脚本。其中,他用 k 均值聚类方法得到的聚类结果作为作为初始估计值(用他的话是 hard-labels),然后通过 EM算法得到最终的聚类结果(soft-labels),这种思路是极好的。我自己做得不够好的地方就是,我常常做完粗糙的 hard-labels后,就收工了,而没有去思考怎么去做更精细的 soft-labels。
简言之,如果有不完整数据出现(例如数据缺失),都可以用到 EM算法,或者是用上 EM算法的思路。思路可能更重要,因为在生产环境中,对算法性能的要求更高,我们可能更多用到的是一些“高大上”的工具,而不是自己去造工具。但当我们把各种工具连接起来的时候,对这些工具的理解就显得尤为重要了。
更重要的是,如果一个企业开发和算法有关的产品或服务,项目组内的成员对算法的理解南辕北辙,这样的产品或服务即使开发出来,也很难被客户接受。所以,在数据时代,对全员的算法方面的认知培训是必要的,算法工程师也应该尽可能的将抽象的算法转换为能为更多人所接受的知识。
写本文的初衷,是希望有一种和同事们进行沟通的媒介,或者作为一种和程序员交流的游戏,基于 Python 和 R 的 EM算法已经有了,Java 或 PHP 程序员接个龙好不好啊?
参考:
[1] 周志华 《机器学习》
[2] http://ai.stanford.edu/%7Echuongdo/papers/em_tutorial.pdf 什么是 EM算法
[3] http://people.duke.edu/%7Eccc14/sta-663/EMAlgorithm.html EM算法实现
[4] http://tinyheero.github.io/2016/01/03/gmm-em.html 用EM算法求GMM参数