背景介绍
在现代视觉人工智能系统中,卷积神经网络起着至关重要的作用,但现许多CNNs模型的发展方向是更大更深,这让深度网络模型难以运行在移动设备上,针对这一问题,许多工作的重点放在对现有预训练模型的修剪、压缩或使用低精度数据表示。
论文中提出的ShuffleNet是探索一个可以满足受限的条件的高效基础架构。论文的Insight是现有的先进basic架构如XceptionXception和ResNeXtResNeXt在小型网络模型中效率较低,因为大量的1×11×1卷积耗费很多计算资源,论文提出了逐点群卷积(pointwise group convolution)帮助降低计算复杂度;但是使用逐点群卷积会有幅作用,故在此基础上,论文提出通道混洗(channel shuffle)帮助信息流通。基于这两种技术,我们构建一个名为ShuffleNet的高效架构,相比于其他先进模型,对于给定的计算复杂度预算,ShuffleNet允许使用更多的特征映射通道,在小型网络上有助于编码更多信息。
论文在ImageNet和MS COCO上做了相关实验,展现出ShuffleNet设计原理的有效性和结构优越性。同时论文还探讨了在真实嵌入式设备上运行效率。
相关工作
高效模型设计: CNNs在CV任务中取得了极大的成功,在嵌入式设备上运行高质量深度神经网络需求越来越大,这也促进了对高效模型的探究。例如,与单纯的堆叠卷积层,GoogleNet增加了网络的宽度,复杂度降低很多;SqueezeNet在保持精度的同时大大减少参数和计算量;ResNet利用高效的bottleneck结构实现惊人的效果。Xception中提出深度可分卷积概括了Inception序列。MobileNet利用深度可分卷积构建的轻量级模型获得了先进的成果;ShuffleNet的工作是推广群卷积(group convolution)和深度可分卷积(depthwise separable convolution)。
模型加速: 该方向旨在保持预训练模型的精度同时加速推理过程。常见的工作有:通过修剪网络连接或减少通道数减少模型中连接冗余;量化和因式分解减少计算中冗余;不修改参数的前提下,通过FFT和其他方法优化卷积计算消耗;蒸馏将大模型的知识转化为小模型,是的小模型训练更加容易;ShuffleNet的工作专注于设计更好的模型,直接提高性能,而不是加速或转换现有模型。
方法介绍
Channel Shuffle for Group Convolutions针对群卷积的通道混洗
ShuffleNet 网络结构同样沿袭了稀疏连接的设计理念。作者通过分析 Xception 和 ResNeXt 模型,发现这两种结构通过卷积核拆分虽然计算复杂度均较原始卷积运算有所下降,然而拆分所产生的逐点卷积计算量却相当可观,成为了新的瓶颈。例如对于 ResNeXt 模型逐点卷积占据了 93.4% 的运算复杂度。可见,为了进一步提升模型的速度,就必须寻求更为高效的结构来取代逐点卷积。
受 ResNeXt 的启发,作者提出使用分组逐点卷积(group pointwise convolution)来代替原来的结构。通过将卷积运算的输入限制在每个组内,模型的计算量取得了显著的下降。然而这样做也带来了明显的问题:在多层逐点卷积堆叠时,模型的信息流被分割在各个组内,组与组之间没有信息交换(如图 1(a) 所示)。这将可能影响到模型的表示能力和识别精度。
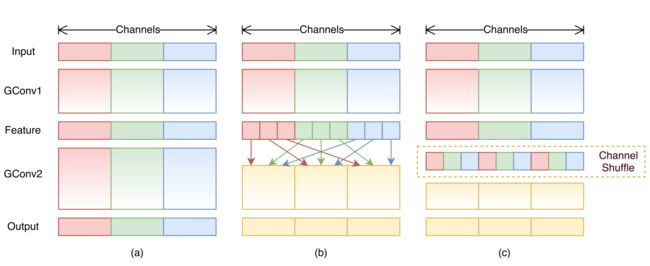
因此,在使用分组逐点卷积的同时,需要引入组间信息交换的机制。也就是说,对于第二层卷积而言,每个卷积核需要同时接收各组的特征作为输入,如图 1(b) 所示。作者指出,通过引入“通道重排”(channel shuffle,见图 1(c) )可以很方便地实现这一机制;并且由于通道重排操作是可导的,因此可以嵌在网络结构中实现端到端的学习。
ShuffleNet Unit
基于分组逐点卷积和通道重排操作,作者提出了全新的 ShuffleNet 结构单元,如图 2 所示。
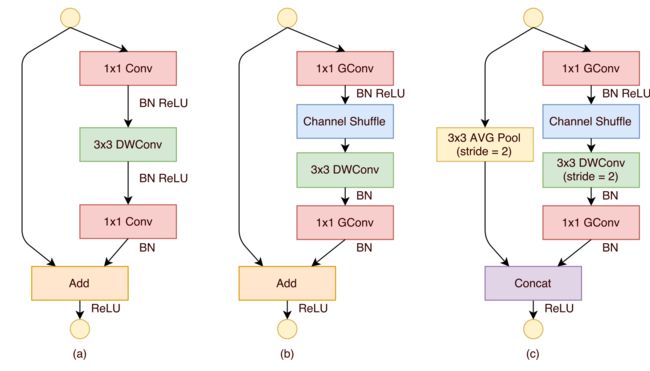
该结构继承了“残差网络”(ResNet)的设计思想,在此基础上做出了一系列改进来提升模型的效率:首先,使用逐通道卷积替换原有的 3x3 卷积,降低卷积操作抽取空间特征的复杂度,如图 2(a)所示;接着,将原先结构中前后两个 1x1 逐点卷积分组化,并在两层之间添加通道重排操作,进一步降低卷积运算的跨通道计算量。最终的结构单元如图 2(b) 所示。类似地,文中还提出了另一种结构单元(图2(c)),专门用于特征图的降采样。
借助 ShuffleNet 结构单元,作者构建了完整的 ShuffeNet 网络模型。它主要由 16 个 ShuffleNet 结构单元堆叠而成,分属网络的三个阶段,每经过一个阶段特征图的空间尺寸减半,而通道数翻倍。整个模型的总计算量约为 140 MFLOPs。通过简单地将各层通道数进行放缩,可以得到其他任意复杂度的模型。
另外可以发现,当卷积运算的分组数越多,模型的计算量就越低;这就意味着当总计算量一定时,较大的分组数可以允许较多的通道数,作者认为这将有利于网络编码更多的信息,提升模型的识别能力。
网络结构
在上面的基本单元基础上,我们提出了ShuffleNet的整体架构:
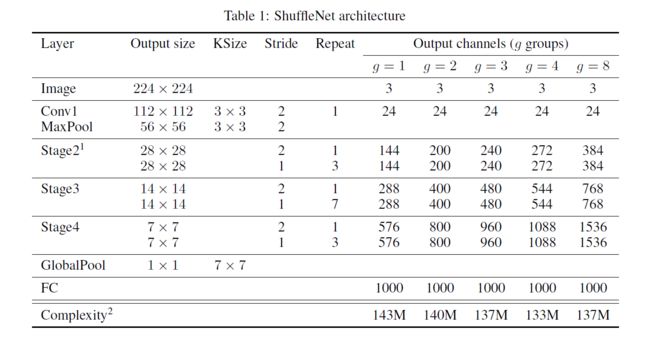
主要分为三个阶段:
每个阶段的第一个block的步长为2,下一阶段的通道翻倍
每个阶段内的除步长其他超参数保持不变
每个ShuffleNet unit的bottleneck通道数为输出的1/4(和ResNet设置一致)
实验
分组化逐点卷积
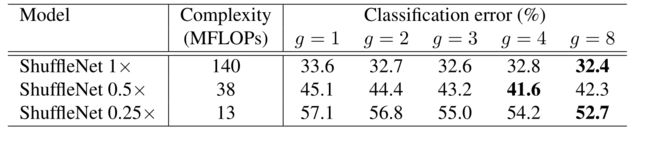
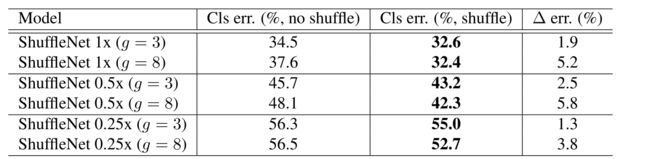
作者对于计算复杂度为 140 MFLOPs 、 40 MFLOPs、13 MFLOPs的 ShuffleNet 模型,在控制模型复杂度的同时对比了分组化逐点卷积的组数在1~8时分别对于性能的影响。从 表1 中可以看出,带有分组的(g>1)的网络的始终比不带分组(g=1)的网络的错误率低。
通道重排
通道重排的目的是使得组间信息能够互相交流。在实验中,有通道重排的网络始终优于没有通道重排的网络,错误率降低 0.9%~4.0%。尤其是在组数较大时(如g=8),前者远远优于后者。
对比其他结构单元
作者使用一样的整体网络布局,在保持计算复杂度的同时将 ShuffleNet 结构单元分别替换为 VGG-like、ResNet、Xception-like 和 ResNeXt 中的结构单元,使用完全一样训练方法。表3 中的结果显示在不同的计算复杂度下,ShuffleNet 始终大大优于其他网络。

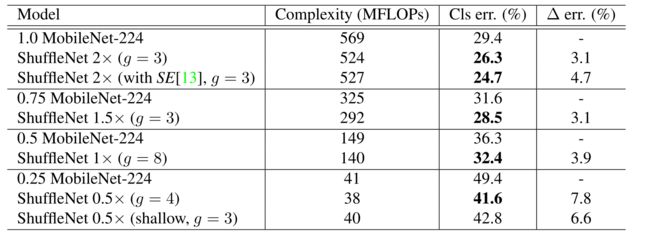
对比MobileNets和其他的一些网络结构
虽然 ShuffleNet 是为了小于 150 MFLOPs 的模型设计的,在增大到 MobileNet 的 500~600 MFLOPs 量级,依然优于 MobileNet。而在 40 MFLOPs 量级,ShuffleNet 比 MobileNet 错误率低 6.7%。
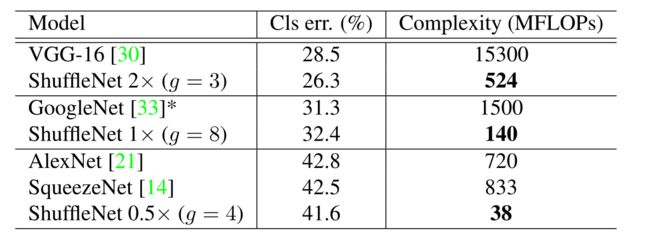
和其他一些网络结构相比,ShuffleNet 也体现出很大的优势。从表5中可以看出,ShuffleNet 0.5x 仅用 40 MFLOPs 就达到了 AlexNet 的性能,而 AlexNet 的计算复杂度达到了 720 MFLOPs,是 ShuffleNet 的 18 倍。
MS COCO物体检测
在 Faster-RCNN 框架下,和 1.0 MobileNet-224 网络复杂度可比的 ShuffleNet 2x,在 600 分辨率的图上的 mAP 达到 24.5%,而 MobileNet 为 19.8%,表明网络在检测任务上良好的泛化能力。
实际运行速度
最后作者在一款 ARM 平台上测试了网络的实际运行速度。在作者的实现里 40 MFLOPs 的 ShuffleNet 对比相似精度的 AlexNet 实际运行速度快约 13x 倍。224 x 224 输入下只需 15.2 毫秒便可完成一次推理,在 1280 x 720 的输入下也只需要 260.1 毫秒。
总结
现代卷积神经网络的绝大多数计算量集中在卷积操作上,因此高效的卷积层设计是减少网络复杂度的关键。其中,稀疏连接是提高卷积运算效率的有效途径,当前不少优秀的卷积模型均沿用了这一思路。ShuffleNet 网络结构同样沿袭了稀疏连接的设计理念,提出了组卷积和通道混洗的处理方法,并在此基础上提出了一个ShuffleNet unit,在计算资源有限的设备上,大幅降低模型计算复杂度的同时仍然保持了较高的识别精度,并在多个性能指标上均显著超过了同类方法。