Spark Streaming 在数据接收与导入方面需要满足有以下三个特点:
- 兼容众多输入源,包括HDFS, Flume, Kafka, Twitter and ZeroMQ。还可以自定义数据源
- 要能为每个 batch 的 RDD 提供相应的输入数据
- 为适应 7*24h 不间断运行,要有接收数据挂掉的容错机制
有容乃大,兼容众多数据源
在文章DStreamGraph 与 DStream DAG中,我们提到
InputDStream是所有 input streams(数据输入流) 的虚基类。该类提供了 start() 和 stop()方法供 streaming 系统来开始和停止接收数据。那些只需要在 driver 端接收数据并转成 RDD 的 input streams 可以直接继承 InputDStream,例如 FileInputDStream是 InputDStream 的子类,它监控一个 HDFS 目录并将新文件转成RDDs。而那些需要在 workers 上运行receiver 来接收数据的 Input DStream,需要继承 ReceiverInputDStream,比如 KafkaReceiver
只需在 driver 端接收数据的 input stream 一般比较简单且在生产环境中使用的比较少,本文不作分析,只分析继承了 ReceiverInputDStream 的 input stream 是如何导入数据的。
ReceiverInputDStream有一个def getReceiver(): Receiver[T]方法,每个继承了ReceiverInputDStream的 input stream 都必须实现这个方法。该方法用来获取将要分发到各个 worker 节点上用来接收数据的 receiver(接收器)。不同的 ReceiverInputDStream 子类都有它们对应的不同的 receiver,如KafkaInputDStream对应KafkaReceiver,FlumeInputDStream对应FlumeReceiver,TwitterInputDStream对应TwitterReceiver,如果你要实现自己的数据源,也需要定义相应的 receiver。
继承 ReceiverInputDStream 并定义相应的 receiver,就是 Spark Streaming 能兼容众多数据源的原因。
为每个 batch 的 RDD 提供输入数据
在 StreamingContext 中,有一个重要的组件叫做 ReceiverTracker,它是 Spark Streaming 作业调度器 JobScheduler 的成员,负责启动、管理各个 receiver 及管理各个 receiver 接收到的数据。
确定 receiver 要分发到哪些 executors 上执行
创建 ReceiverTracker 实例
我们来看 StreamingContext#start() 方法部分调用实现,如下:

可以看到,StreamingContext#start() 会调用 JobScheduler#start() 方法,在 JobScheduler#start() 中,会创建一个新的 ReceiverTracker 实例 receiverTracker,并调用其 start() 方法。
ReceiverTracker#start()
继续跟进 ReceiverTracker#start(),如下图,它主要做了两件事:
- 初始化一个 endpoint: ReceiverTrackerEndpoint,用来接收和处理来自 ReceiverTracker 和 receivers 发送的消息
- 调用 launchReceivers 来自将各个 receivers 分发到 executors 上

ReceiverTracker#launchReceivers()
继续跟进 launchReceivers,它也主要干了两件事:
- 获取 DStreamGraph.inputStreams 中继承了 ReceiverInputDStream 的 input streams 的 receivers。也就是数据接收器
- 给消息接收处理器 endpoint 发送 StartAllReceivers(receivers)消息。直接返回,不等待消息被处理

处理StartAllReceivers消息
endpoint 在接收到消息后,会先判断消息类型,对不同的消息做不同处理。对于StartAllReceivers消息,处理流程如下:
- 计算每个 receiver 要分发的目的 executors。遵循两条原则:
- 将 receiver 分布的尽量均匀
- 如果 receiver 的preferredLocation本身不均匀,以preferredLocation为准
- 遍历每个 receiver,根据第1步中得到的目的 executors 调用 startReceiver 方法

到这里,已经确定了每个 receiver 要分发到哪些 executors 上
启动 receivers
接上,通过 ReceiverTracker#startReceiver(receiver: Receiver[_], scheduledExecutors: Seq[String]) 来启动 receivers,我们来看具体流程:
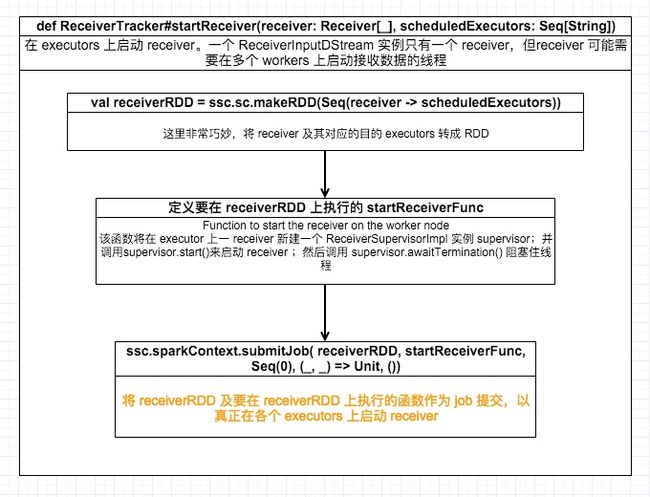
如上流程图所述,分发和启动 receiver 的方式不可谓不精彩。其中,startReceiverFunc 函数主要实现如下:
val supervisor = new ReceiverSupervisorImpl(
receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)
supervisor.start()
supervisor.awaitTermination()
supervisor.start() 中会调用 receiver#onStart 后立即返回。receiver#onStart 一般自行新建线程或线程池来接收数据,比如在 KafkaReceiver 中,就新建了线程池,在线程池中接收 topics 的数据。
supervisor.start() 返回后,由 supervisor.awaitTermination() 阻塞住线程,以让这个 task 一直不退出,从而可以源源不断接收数据。
数据流转

上图为 receiver 接收到的数据的流转过程,让我们来逐一分析
Step1: Receiver -> ReceiverSupervisor
这一步中,Receiver 将接收到的数据源源不断地传给 ReceiverSupervisor。Receiver 调用其 store(...) 方法,store 方法中继续调用 supervisor.pushSingle 或 supervisor.pushArrayBuffer 等方法来传递数据。Receiver#store 有多重形式, ReceiverSupervisor 也有 pushSingle、pushArrayBuffer、pushIterator、pushBytes 方法与不同的 store 对应。
- pushSingle: 对应单条小数据
- pushArrayBuffer: 对应数组形式的数据
- pushIterator: 对应 iterator 形式数据
- pushBytes: 对应 ByteBuffer 形式的块数据
对于细小的数据,存储时需要 BlockGenerator 聚集多条数据成一块,然后再成块存储;反之就不用聚集,直接成块存储。当然,存储操作并不在 Step1 中执行,只为说明之后不同的操作逻辑。
Step2.1: ReceiverSupervisor -> BlockManager -> disk/memory
在这一步中,主要将从 receiver 收到的数据以 block(数据块)的形式存储
存储 block 的是receivedBlockHandler: ReceivedBlockHandler,根据参数spark.streaming.receiver.writeAheadLog.enable配置的不同,默认为 false,receivedBlockHandler对象对应的类也不同,如下:
private val receivedBlockHandler: ReceivedBlockHandler = {
if (WriteAheadLogUtils.enableReceiverLog(env.conf)) {
//< 先写 WAL,再存储到 executor 的内存或硬盘
new WriteAheadLogBasedBlockHandler(env.blockManager, receiver.streamId,
receiver.storageLevel, env.conf, hadoopConf, checkpointDirOption.get)
} else {
//< 直接存到 executor 的内存或硬盘
new BlockManagerBasedBlockHandler(env.blockManager, receiver.storageLevel)
}
}
启动 WAL 的好处就是在application 挂掉之后,可以恢复数据。
//< 调用 receivedBlockHandler.storeBlock 方法存储 block,并得到一个 blockStoreResult
val blockStoreResult = receivedBlockHandler.storeBlock(blockId, receivedBlock)
//< 使用blockStoreResult初始化一个ReceivedBlockInfo实例
val blockInfo = ReceivedBlockInfo(streamId, numRecords, metadataOption, blockStoreResult)
//< 发送消息通知 ReceiverTracker 新增并存储了 block
trackerEndpoint.askWithRetry[Boolean](AddBlock(blockInfo))
不管是 WriteAheadLogBasedBlockHandler 还是 BlockManagerBasedBlockHandler 最终都是通过 BlockManager 将 block 数据存储 execuor 内存或磁盘或还有 WAL 方式存入。
这里需要说明的是 streamId,每个 InputDStream 都有它自己唯一的 id,即 streamId,blockInfo包含 streamId 是为了区分block 是哪个 InputDStream 的数据。之后为 batch 分配 blocks 时,需要知道每个 InputDStream 都有哪些未分配的 blocks。
Step2.2: ReceiverSupervisor -> ReceiverTracker
将 block 存储之后,获得 block 描述信息 blockInfo: ReceivedBlockInfo,这里面包含:streamId、数据位置、数据条数、数据 size 等信息。
之后,封装以 block 作为参数的 AddBlock(blockInfo) 消息并发送给 ReceiverTracker 以通知其有新增 block 数据块。
Step3: ReceiverTracker -> ReceivedBlockTracker
ReceiverTracker 收到 ReceiverSupervisor 发来的 AddBlock(blockInfo) 消息后,直接调用以下代码将 block 信息传给 ReceivedBlockTracker:
private def addBlock(receivedBlockInfo: ReceivedBlockInfo): Boolean = {
receivedBlockTracker.addBlock(receivedBlockInfo)
}
receivedBlockTracker.addBlock中,如果启用了 WAL,会将新增的 block 信息以 WAL 方式保存。
无论 WAL 是否启用,都会将新增的 block 信息保存到 streamIdToUnallocatedBlockQueues: mutable.HashMap[Int, ReceivedBlockQueue]中,该变量 key 为 InputDStream 的唯一 id,value 为已存储未分配的 block 信息。之后为 batch 分配blocks,会访问该结构来获取每个 InputDStream 对应的未消费的 blocks。
总结
至此,本文描述了:
- streaming application 如何兼容众多数据源
- receivers 是如何分发并启动的
- receiver 接收到的数据是如何流转的
欢迎关注我的微信公众号:FunnyBigData
