搜索技术
SOLR和LUCENE关系
Solr是基于Lucene做的,Lucene是一套信息检索工具包,但并不包含搜索引擎系统,它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此在使用Lucene时你仍需要关注搜索引擎系统,例如数据获取、解析、分词等方面的东西,所以必须要先了解LUCENE,再了解SOLR。而Solr的目标是打造一款搜索引擎系统,因此它更接近于我们认识到的搜索引擎系统,它是一个搜索引擎服务,通过各种API可以让你的应用使用搜索服务,而不需要将搜索逻辑耦合在应用中。而且Solr可以根据配置文件定义数据解析的方式,更像是一个搜索框架,它也支持主从、热换库等操作。还添加了飘红、facet等搜索引擎常见功能的支持。Lucene更像是一个SDK。 有完整的API族以及对应的实现。你可以利用这些在自己的应用里实现高级查询(基于倒排索引技术的),Lucene对单机或者桌面应用很实用很方便。但是Lucene,需要开发者自己维护索引文件,在多机环境中备份同步索引文件很是麻烦。于是,就有了Solr。Solr是一个有HTTP接口的基于Lucene的查询服务器,封装了很多Lucene细节。
Lucene想要实现一套完整的搜索引擎流程架构,不是不可以,只是要花费很长的时间和代价,因此公司一般都会采用SOLR来进行搜索服务的建立。
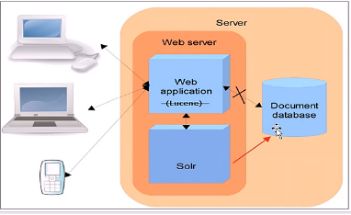
在结构上SOLR和Lucene有很大的区别,Lucene是把代码集成在web应用中,然后通过代码去调用索引库进行查询,而Solr是有自己的服务,由web应用去solr服务中请求,再由solr服务去索引库中进行查询
SOLR介绍
安装
1、安装前准备
~JDK版本:必须是1.8以上的jdk版本,并进行环境变量的配置
~JDK版本:必须是1.8以上的jdk版本,并进行环境变量的配置
~TOMCAT优化:加大内存和连接数
~还需要配置server.xml

~操作系统优化:/etc/sysctl.conf文件增加(linux操作系统才需要,文本演示window操作系统)
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 5
2、本地安装
SOLR下载:http://lucene.apache.org/solr/
1)在tomcat目录下建立solrhome目录,并在solrhome目录下创建一个core目录(实例),并在core目录下创建data目录(服务数据和日志的存放);
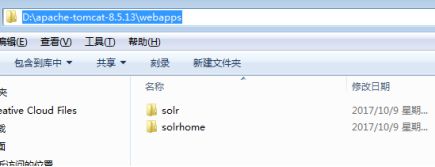
2) 复制solr/server/solr/*所有文件到tomcat/solrhome目录,用到创建solr的core时使用
复制到:
3)拷贝solrhome/configsets/basic_configs下的的conf文件夹到core文件夹下。
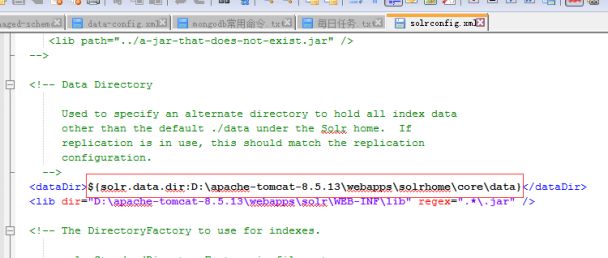
4)修改core/conf/solrconfig.xml文件:
5)、拷贝下载文件夹中的webapp下的工程到TOMCAT的webapp下
复制到
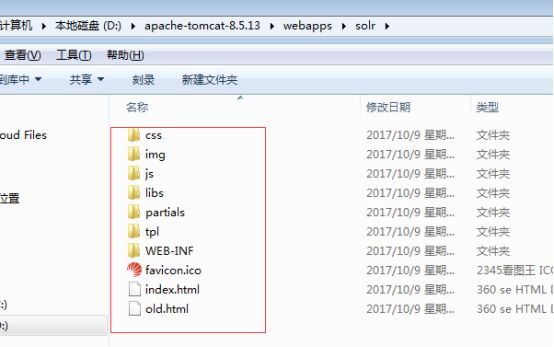
6)、拷贝下载文件夹中solr压缩包中server\lib\ext中的jar全部复制到Tomcat\ webapps\solr\WEB-INF\lib目录中
7)、拷贝下载文件夹中solr压缩包中server\lib\metrics*中的jar全部复制到Tomcat\ webapps\solr\WEB-INF\lib目录中
8)、拷贝下载文件夹中solr压缩包中dist\dataimporthandler*中的jar全部复制到Tomcat\ webapps\solr\WEB-INF\lib目录中
9)、在Tomcat的\ webapps\solr\WEB-INF\下建立classes目录,并将solr/server/resources/log4j.properties文件复制其中;
10)、编辑webapps/solr/WEB-INF/下的web.xml文件:
配置solr下core路径,找到如下内容,并去掉注释

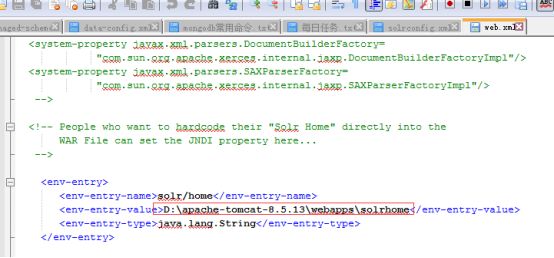
注释标签以及标签下的内容
11)、修改/core/conf/managed-schema添加两种域类型(123行左右):

12)、在D:\apache-tomcat-8.5.13\webapps\solrhome\core路径下创建core.properties文件,里面配置solr环境

启动管理后台:启动tomcat后,访问http://localhost: 8080/solr/index.html
通过core Admin来进行core的添加,同时查看添加的core内容。
solr控制台

分词器
准分词器对中文分词不太好用,一般建议用IKAnalyzer,该分词器对中文的支持应该是目前最好的,拷贝IKAnalyzer.jar文件到solr/WEB-INF/lib下,将IKAnalyzer.cfg.xml、ext_stopword.dic、mydict.dic拷贝到solr/WEB-INF/classes下.
在core/conf/managed-schema文件中添加:

添加完成后,就可以进solr admin里面试试选择text_ik,看看效果,如果测试效果没有问题,那么就可以对managed-schema文件中,需要用到该分词的域进行修改或者添加了
重启solr后进入控制台可以看见solr分词器,里面多了IK分词器选项,如下所示
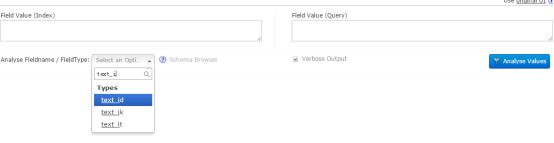
选择IK分词器进行分词操作,如下所示

外部数据导入
1)、如果导入的数据为mysql数据库的表数据,那么还需要导入mysql的jar包到solr项目下的lib中:

2)、在solrconfig.xml文件中加入:
3)、修改solrhome/core/conf/solrconfig.xml文件,找到requestHandler标签,在其结束标签后面添加一组新的标签:

4)、在solrhome/core/conf/目录下创建上述配置内容中的data-config.xml文件,文件内容如下:
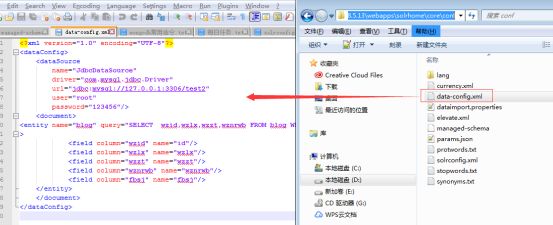
上面的配置中可以看到从数据库中对应映射了一张表名为blog的表,其中deltaQuery是增量索引,原理是从数据库中根据deltaQuery指定的SQL语句查询出所有需要增量导入的数据的wzid号。然后根据deltaImportQuery指定的SQL语句返回所有这些wzid的数据,即为这次增量导入所要处理的数据。核心思想是:通过内置量“${dih.delta.id}”和“${dataimporter.last_index_time}”来记录本次要索引的wzid和最近一次索引的时间,同时映射了4个字段。
5)、那么我们这个时候就需要对managed-schema文件再次进行修改,把上述标签中的name属性,映射到新的field中,如下:
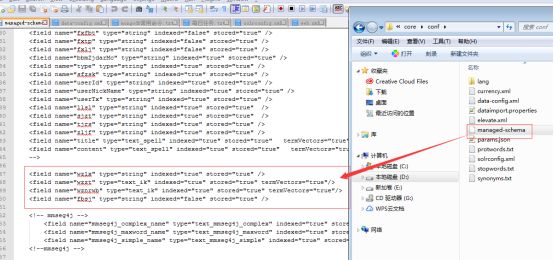
修改
重启solr后,进入到导入数据的界面
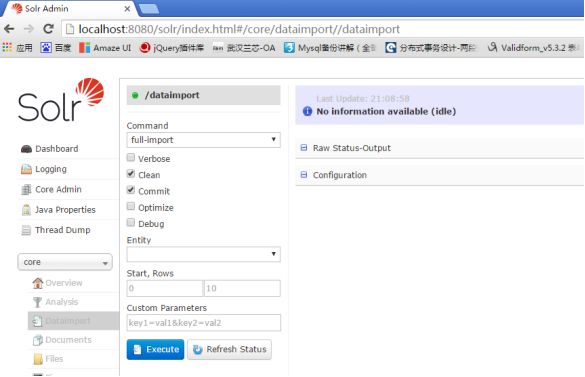
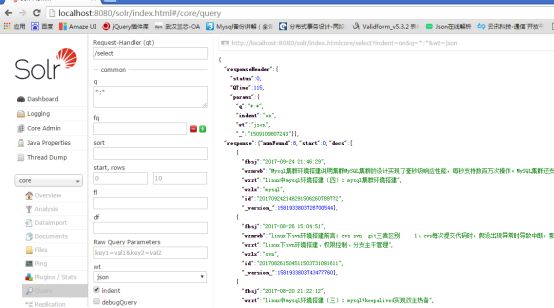
此界面的功能不在此介绍了,点击执行按钮,导入完数据后,可以在查询页面看到数据存在了,如下所示:
2)、通过java代码导入数据
实际上大部分的需求都是需要结合代码进行导入数据,比较不可能每次导入数据的时候都需要人工手动去solr控制台界面中进行操作,所以我们要定时去导入数据。
首先需要有一个javaBea和solr中的约束文件中新增的属性一 一对应,如下为javabean
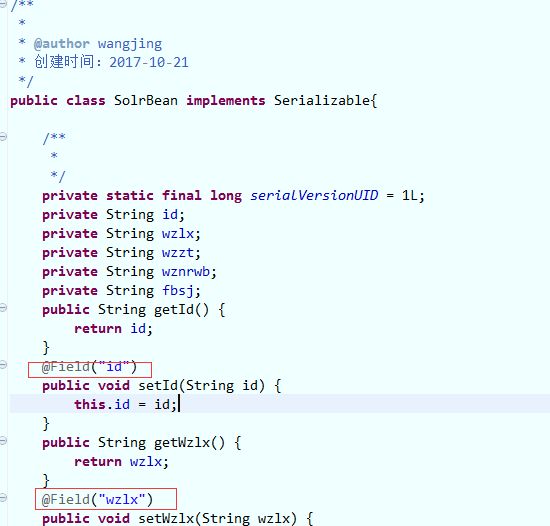
注意,每个字段的set方法中需要加入solr的字段对应注解,所以我们需要在项目中导入solr相关的jar包
然后通过定时器去导入对应数据到solr中,此处用到的是spring4.0新特性进行演示,原理都差不多,所以只需要能实现定时器任务即可
创建了全局配置文件,类似于application.xml文件,开启了定时器任务支持等注解

最后在对应的定时任务类中完成任务
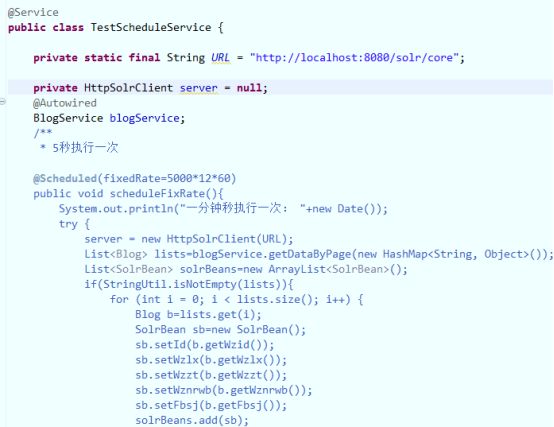
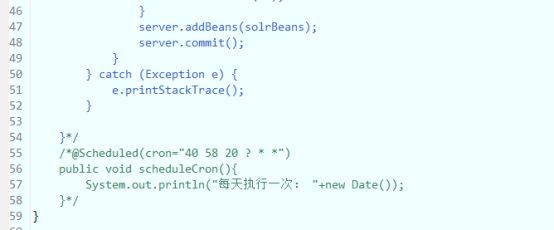
直接启动web项目定时器即可执行
solr控制台查询界面介绍




Solr结合Web项目实现高亮查询
需求:在项目中需要根据关键字搜索出对应的文章的标题和内容。
前提:基于刚才已经导入的数据。
Java代码如下:


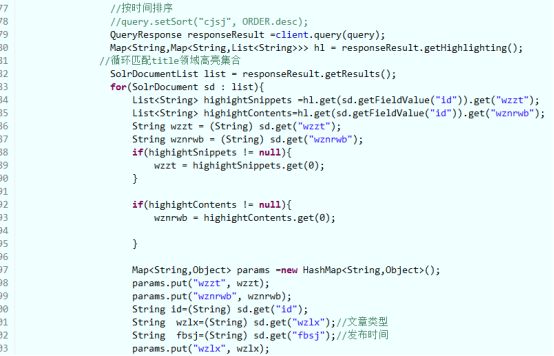

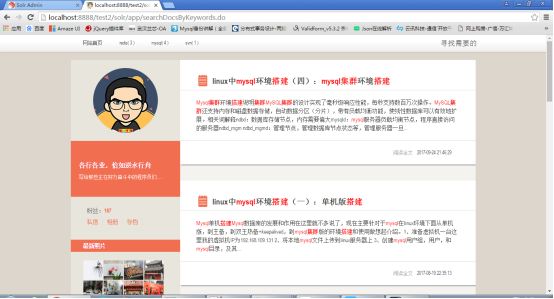
项目运行后,如下所示,会展示所有的文章帖子:
点击搜索,输入“mysql集群 环境”
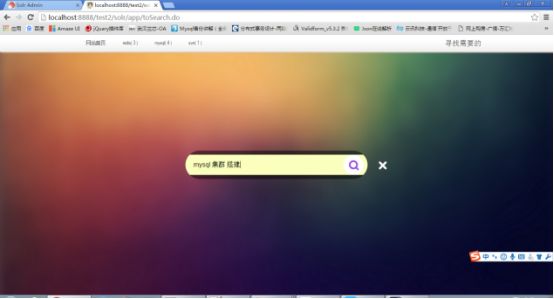
结果: