1 实战环境
使用Spark-Shell进行练习,Spark-Shell就是一种特殊的SparkSubmit,所以如果你想要使用Spark-Submit的话就需要使用IDE开发打成jar上传到节点上运行
2 数据格式
格式如下:barCode@item@value@standardValue@upperLimit@lowerLimit
01055HAXMTXG10100001@[email protected]@[email protected]@1.55
01055HAXMTXG10100001@[email protected]@[email protected]@0.8
01055HAXMTXG10100001@[email protected]@[email protected]@0.8
01055HAXMTXG10100001@[email protected]@[email protected]@0.8
01055HAXMTXG10100001@[email protected]@[email protected]@0.8
01055HAXMTXG10100001@[email protected]@[email protected]@1.65
01055HAXMTXG10100001@[email protected]@[email protected]@1.55
3 说明
在正式的开发中是需要自己创建val spark = SparkSession.builder().appName(“”).getOrCreate();但在Spark-Shell环境中已经为我们创建好sparkContext和sparkSession,所以我们直接使用即可
4 代码实战
barCode里面包含了很多信息01055/HAX/MTX/G101/000001对应地区工厂编号/车型/核心模块名称/生产日期/序列号,所以从HDFS上获得数据之后需要对数据进行解析转换成我们想要的数据格式,所有编写了以下代码来进行解析,如下:
// 01055 HAX MTX G101 00001
val month = Array("01","02","03","04","05","06","07","08","09","10","11","12")
def change(str:String) ={
var month1 = ""
if ("A".equals(str)) {
month1 = month(9)
} else if ("B".equals(str)){
month1 = month(10)
} else if("C".equals(str)){
month1 = month(11)
}
month1
}
def parseDate(str:String) = {
val year = if("H".equals(str.substring(0,1))) "2016" else "2015"
val monthStr = str.substring(1,2)
val month1 = if(monthStr >= "A") change(monthStr) else month(monthStr.toInt-1)
val date = year+"-"+month1+"-"+str.substring(2,4)
date
}
def parseBarCode(barCode:String) = {
val array = new Array[String](5)
val region = barCode.substring(0,5)
val carType = barCode.substring(5,8)
val keyPart = barCode.substring(8,11)
val date = parseDate(barCode.substring(11,15))
array(0) = region
array(1) = carType
array(2) = keyPart
array(3) = date
array(4) = barCode.substring(15,20)
array
}
case class Data(region:String,carType:String,keyPart:String,date:String,number:String,item:String,value:Float,standard:Float,upperLimit:Float,lowerLimit:Float)
def parse(str:String) = {
val array = str.split("@")
if(array.length<6){
throw new Exception("参数不够")
}
val barCode = array(0)
val region = barCode.substring(0,5)
val carType = barCode.substring(5,8)
val keyPart = barCode.substring(8,11)
val date = parseDate(barCode.substring(11,15))
val number = barCode.substring(15,20)
val item = array(1)
val value = array(2).toFloat
val standard = array(3).toFloat
val upperLimit = array(4).toFloat
val lowerLimit = array(5).toFloat
Data(region,carType,keyPart,date,number,item,value,standard,upperLimit,lowerLimit)
}
1)通过sparkContext读取hdfs中的数据,并转换为DataFrame
val dataRDD = sc.textFile(“/data/produce/2015/*”)
val dataDFRDD = dataRDD.map{x => parse(x)}
val dataDF = dataDFRDD.toDF
dataDF.take(10)

从上面的截图我们可以看出数据已经经过解析转换成我们想要的格式
2)创建视图,用演示sql语句
dataDF.createOrReplaceTempView("data")
val sqlRDD = spark.sql("select * from data").show
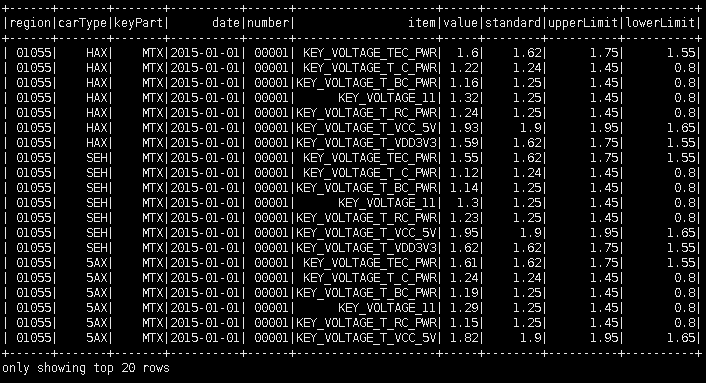
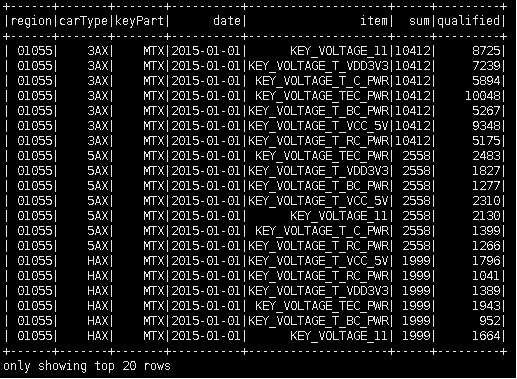
3)使用groupby 编写统计属于同一地区,同一车型,同一关键零部件,同一测试项目,同一天的测试总次数和测试合格数的sql
val result = spark.sql("select region,carType,keyPart,date,item,count(value) as sum, sum(case when abs(standard-value)<0.08 then 1 else 0 end) as qualified from data group by date,item,region,carType,keyPart order by date,carType")
result.show
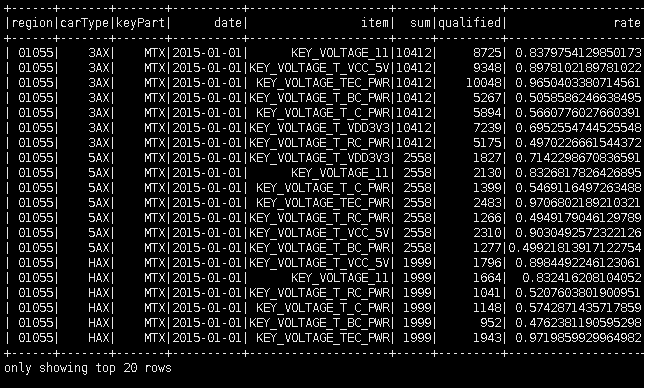
4)使用groupby 编写统计属于同一地区,同一车型,同一关键零部件,同一测试项目,同一天的测试总次数、测试合格数以及合格率的sql
val result1 = spark.sql("select tmp.region,tmp.carType,tmp.keyPart,tmp.date,tmp.item,tmp.sum,tmp.qualified,tmp.qualified/tmp.sum as rate from (select region,carType,keyPart,date,item,count(value) as sum, sum(case when abs(standard-value)<0.08 then 1 else 0 end) as qualified from data group by date,item,region,carType,keyPart order by date,carType) tmp ")
result1.show
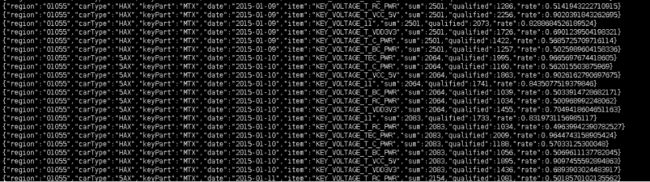
5)将数据写入到hdfs上
result1.write.json(“/data/produce/result/json/”)
使用hadoop fs –cat /data/produce/result/json/* 查看,就可以看到下面的数据
6)读取Json格式的数据
val jsonRDD = spark.read.json("/data/produce/result/json/*")
jsonRDD.take(10)
