Zookeeper
是一个分布式应用程序提供高性能协调服务的工具集合。
ZooKeeper本质上是一个分布式的小文件存储系统。原本是Apache Hadoop的一个组件,现在被拆分为一个Hadoop的独立子项目,在HBase(Hadoop的另外一个被拆分出来的子项目,用于分布式环境下的超大数据量的DBMS)中也用到了ZooKeeper集群。
Hadoop,使用Zookeeper的事件处理确保整个集群只有一个NameNode,存储配置信息等.
HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕(dàng)机,存储访问控制列表等。
ZooKeeper节点Znode
ZooKeeper目录树中每一个节点对应一个Znode。每个Znode维护着一个属性结构,它包含着版本号(dataVersion),时间戳(ctime,mtime)等状态信息。ZooKeeper正是使用节点的这些特性来实现它的某些特定功能。每当Znode的数据改变时,他相应的版本号将会增加。每当客户端检索数据时,它将同时检索数据的版本号。并且如果一个客户端执行了某个节点的更新或删除操作,他也必须提供要被操作的数据版本号。如果所提供的数据版本号与实际不匹配,那么这个操作将会失败。
Znode是客户端访问ZooKeeper的主要实体,它包含以下几个特征:
(1)Watches
客户端可以在节点上设置watch(我们称之为监视器)。当节点状态发生改变时(数据的增、删、改)将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次。
(2)数据访问
ZooKeeper中的每个节点存储的数据要被原子性的操作。也就是说读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
(3)节点类型
ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
ZooKeeper的临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话结束,临时节点将被自动删除,当然可以也可以手动删除。另外,需要注意是,ZooKeeper的临时节点不允许拥有子节点。
ZooKeeper的永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
(4)顺序节点(唯一性的保证)
当创建Znode的时候,用户可以请求在ZooKeeper的路径结尾添加一个递增的计数。这个计数对于此节点的父节点来说是唯一的,它的格式为“%10d”(10位数字,没有数值的数位用0补充,例如“0000000001”)。当计数值大于232-1时,计数器将溢出。
org.apache.zookeeper.CreateMode中定义了四种节点类型,分别对应:
PERSISTENT:永久节点
EPHEMERAL:临时节点
PERSISTENT_SEQUENTIAL:永久节点、序列化
EPHEMERAL_SEQUENTIAL:临时节点、序列化
ZooKeeper数据模型
ZooKeeper拥有一个层次的命名空间,这个和分布式的文件系统非常相似。不同的是ZooKeeper命名空间中的Znode,兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分,并可以具有子znode。用户对znode具有增、删、改、查等操作(权限允许的情况下)。
znode具有原子性操作,每个znode的数据将被原子性地读写,读操作会读取与znode相关的所有数据,写操作会一次性替换所有数据。zookeeper并没有被设计为常规的数据库或者大数据存储,相反的是,它用来管理调度数据,比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都是很小的数据,通常以KB为大小单位。zooKeeper的服务器和客户端都被设计为严格检查并限制每个znode的数据大小至多1M,当时常规使用中应该远小于此值。
Zonde由路径标注,ZooKeeper中被表示成有反斜杠分割的Unicode字符串,如同Unix中的文件路径。路径必须是绝对的,因此他们必须由反斜杠来字符开头。除此以外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。ZooKeeper的数据结构,与普通的文件系统极为类似.
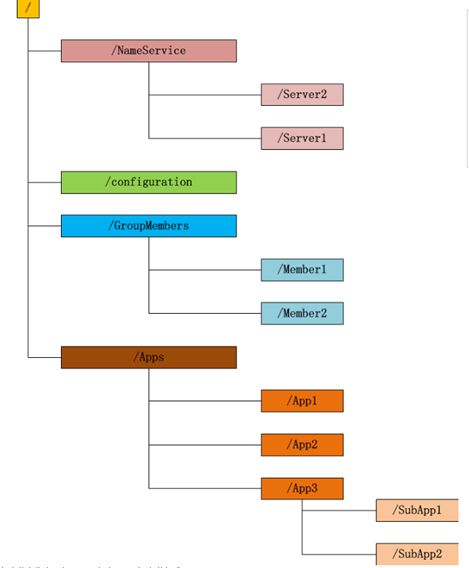
图中的每个节点称为一个znode.每个znode由3部分组成:
1.stat:此为状态信息,描述该znode的版本,权限等信息.
2.data:与该znode关联的数据.
3.children:该znode下的子节点.
ZooKeeper部署-单机模式
zoo.cfg配置
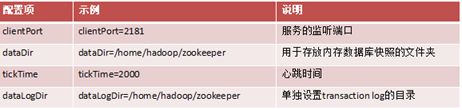
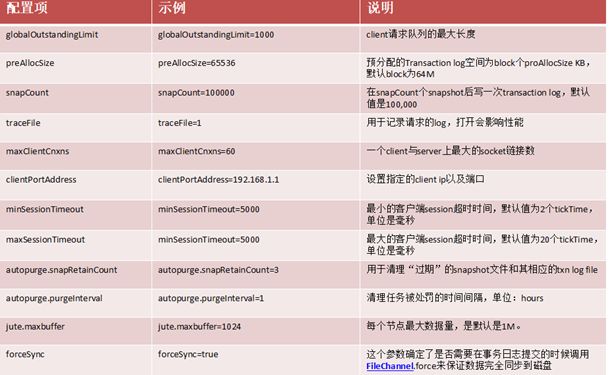
重要命令
[hadoop@centos-1 zookeeper-3.4.5-cdh4.3.0]$bin/./zkServer.sh start
JMX enabled by default
Using config:/export/home/tools/zookeeper-3.4.5-cdh4.3.0/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@centos-2 zookeeper-3.4.5-cdh4.3.0]$bin/./zkServer.sh status
JMX enabled by default
Using config: /export/home/tools/zookeeper-3.4.5-cdh4.3.0/bin/../conf/zoo.cfg
Mode: standalone
[hadoop@centos-1 zookeeper-3.4.5-cdh4.3.0]$bin/./zkServer.sh start
JMX enabled by default
Using config:/export/home/tools/zookeeper-3.4.5-cdh4.3.0/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@centos-2 zookeeper-3.4.5-cdh4.3.0]$bin/./zkServer.sh status
JMX enabled by default
Using config:/export/home/tools/zookeeper-3.4.5-cdh4.3.0/bin/../conf/zoo.cfg
Mode: leader
[hadoop@centos-2 zookeeper-3.4.5-cdh4.3.0]$bin/./zkServer.sh status
JMX enabled by default
Using config:/export/home/tools/zookeeper-3.4.5-cdh4.3.0/bin/../conf/zoo.cfg
Mode: follower
Zookeeper使用场景
分布式独占锁
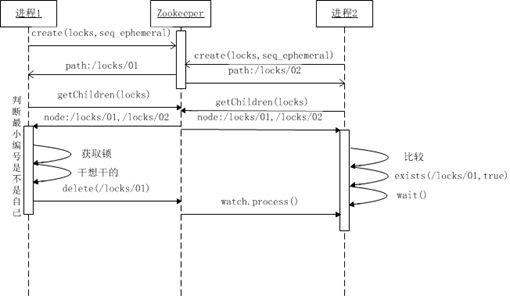
分布式读写锁
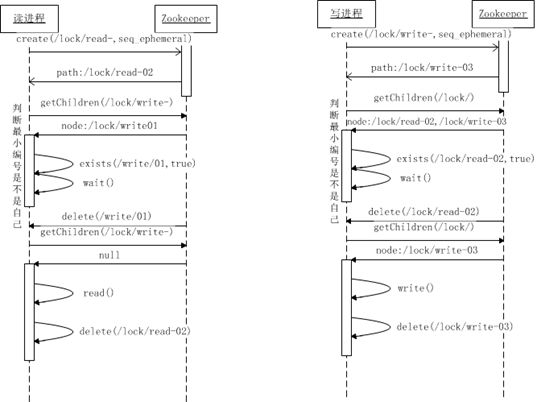
分布式队列-FIFO
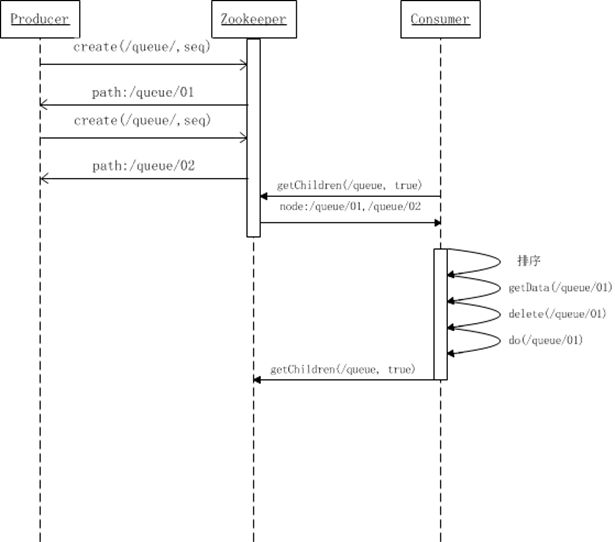
分布式队列-SyncQueue
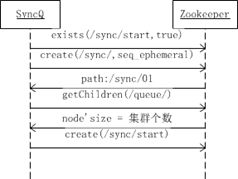
默认值递增

安装mvn
1、获取代码
#git clonehttps://github.com/DeemOpen/zkui.git
2、构建并安装程序
#cd zkui/
#yum install -y maven
#mvn clean install
3、修改配置文件
#cp config.cfg target/
#cd target/
#vim config.cfg
serverPort=9090 #指定端口
zkServer=xxxx:2181,xxxx:2181
userSet = {"users": [{ "username":"admin" , "password":"admin","role": "ADMIN" },{ "username":"appconfig" , "password":"appconfig","role": "USER" }]}
4、启动程序至后台
#nohup java -jar zkui-2.0-SNAPSHOT-jar-with-dependencies.jar &
5、用浏览器访问
http://xxxx:9090
6、Kafka
kafka是由LinkedIn开发,主要是用来处理Linkedin的大面积活跃数据流处理(activitystream).此类的数据经常用来反映网站的一些有用的信息,比如PV,页面展示给哪些用户访问,用户搜索什么关键字最多,这类信息经常被log到文件里,然后线下且周期性的去分析这些数据。现在这种用户活跃数据已经成为互联网公司重要的一部分,所以必须构建一个更轻量且更精炼的基础架构。
√活跃数据使用案列
分析一下用户行为(pageviews),以便我能设计出更好的广告位。
快速的统计用户投票,点击。
对用户的搜索关键词进行统计,分析出当前的流行趋势。
防止用户对网站进行无限制的抓取数据,以及超限制的使用API,辨别垃圾。
对网站进行全方位的实时监控,从而得到实时有效的性能数据,并且及时的发成警告。
批量的导入数据到数据仓库,对数据进行离线分析,从而得到有价值的商业信息。(0.6可以直接将数据导入Hadoop)
√活跃数据的特点
高流量的活跃数据是无法确定其大小的,因为他可能随时的变化,比如商家可能促销,节假日打折,突然又冒出一个跳楼价等等。所有的数据可能是数量级的往上递增。传统日志分析方式都是需要离线,而且操作起来比较复杂,根本无法满足实时的分析。另一方面,现有的消息队列系统只能达到近似实时的分析,因为无法消费大量的持久化在队列系统上的信息。Kafka的目标就是能够成为一个高效的队列平台,无论是处理离线的信息还是在线的信息。
Kafka集群
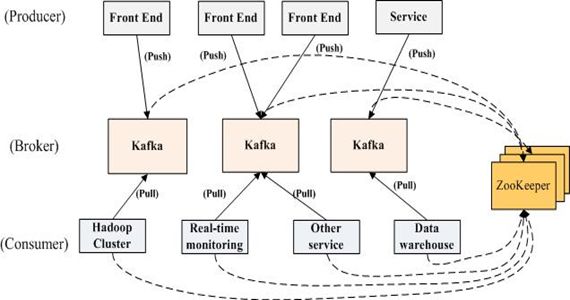
消息存储设计
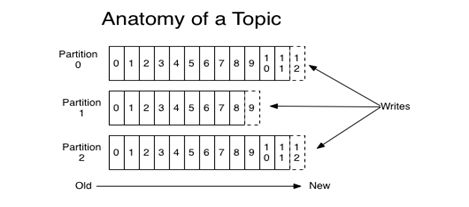
设计特点
消息保存在磁盘,O(1)时间复杂度
不使用内存?使用磁盘缓存
消费状态保存在消费客户端
可以保存足够大的未处理消息