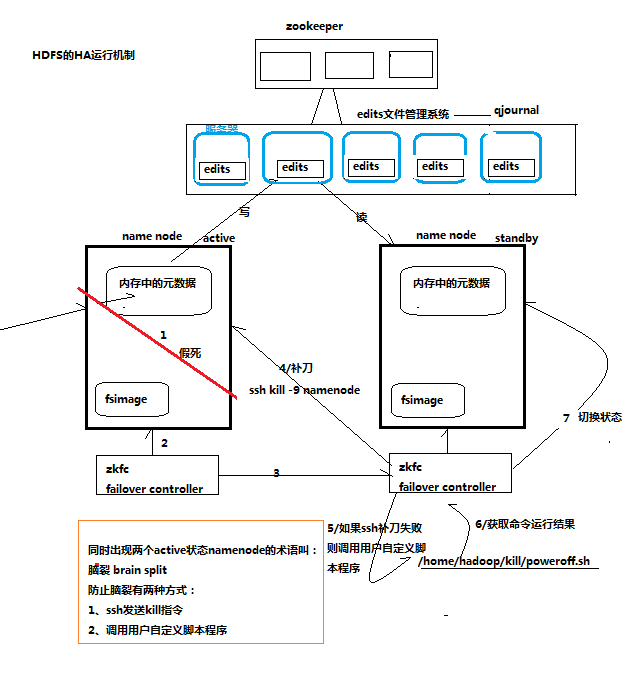
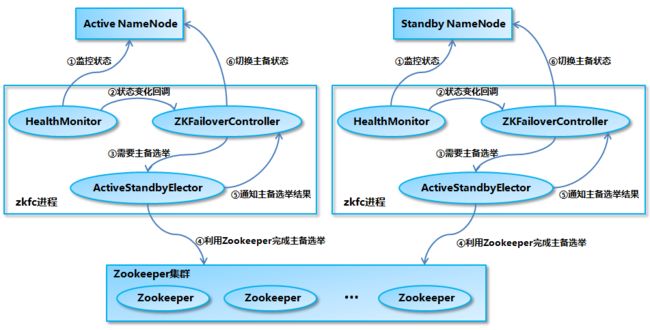
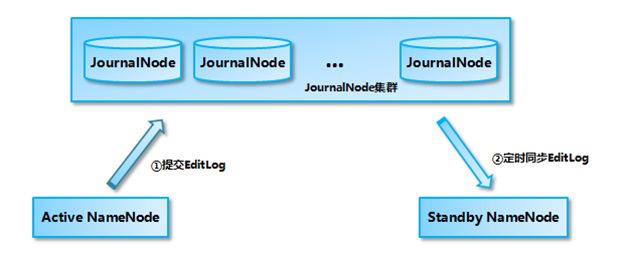
- 一般莆田鞋在哪个app买?三大app莆田鞋平台推荐给大家
美鞋之家
一般莆田鞋在哪个app买?三大app莆田鞋平台推荐给大家莆田鞋在什么app平台上买,莆田鞋在淘宝app,微商app,得物app都可以购买到,为什么在这些渠道购买莆田鞋呢?微商价格也比较实惠,档口价格有优势,实体店可以试穿,至于淘宝和微商差不多,价格优势已经透底了。微信:a40273(下单赠送精美礼品)莆田鞋在哪个app买1、微商app可以说是买莆田鞋人数最多的渠道。2、淘宝app。买莆田鞋当然少不
- 2023-08-18小皇帝的俏军师34
澜莲Alice
“奇变偶不变?”“符号看象限!”“大河向东流呐”“天上的星星参北斗。”“老乡啊!”邱璟一个箭步上前,“我们来自同一个时空。”“是的。”显然,对方没那么激动,“你也有系统吧,你应该是这个世界的主角,我是由于一些任务到来而已。”“你们来自同一个地方,太好了,小璟有说话的人了。”笑笑说道。郑重声明:文章系原创首发,文责自负。
- 克服恐惧,记住成功体验
清盟
昨天跟一个听众朋友聊到可以开发一个课程,练习胆量很多成年人的在人面前展现的胆量还不如孩子,成年人想得多了怕是怕在大家面前出丑,如果表演后获得掌声,是不会怕的这恐惧背后是怕别人会怎么看我呀?久而久之就不敢在大众年前表演了今天有个朋友说,以前自己挺喜欢唱歌的,后来渐渐不唱了我们每个人生下来,天生都有某种程度的表演天份的,久了,被埋没了最近几次街头演唱我给小朋友锻炼的名额还别说,最近两次的小朋友表现都很
- 正则表达式概述
出门撞大运
正则表达式
在编程中,处理字符串是一项常见且重要的任务。而正则表达式,作为一种强大的字符串匹配工具,能帮助我们高效地完成各种复杂的字符串处理需求。无论是数据验证、文本搜索与替换,还是日志分析等场景,正则表达式都能大显身手。今天,我们就来全面了解一下正则表达式。一、什么是正则表达式正则表达式,又称正规表示法、常规表示法(英语:RegularExpression,在代码中常简写为regex、regexp或RE),
- AJAX概述
出门撞大运
ajax前端
在现代网页开发中,我们早已习惯了无需刷新页面就能获取新数据的流畅体验——浏览电商网站时的实时库存更新、社交平台的动态加载内容、表单提交后的即时验证反馈……这些都离不开一项核心技术——AJAX。今天,我们就来深入探索AJAX的奥秘,带你全面掌握这门改变网页交互方式的关键技术。一、什么是AJAX?AJAX,全称异步JavaScript和XML(AsynchronousJavaScriptandXML)
- Servlet概述
出门撞大运
servlet
在JavaWeb开发中,Servlet是核心组件之一,负责处理客户端请求并生成响应。本文将从Servlet的基本概念出发,逐步深入其生命周期、实现方式、路径映射等关键知识点,帮助你全面掌握Servlet技术。一、Servlet概述与JavaWeb三大组件Servlet(ServerLet)是运行在Web服务器中的小型Java程序,主要作用是处理用户请求。当客户端发出请求后,由Web服务器(如Tom
- 慎终如始17:有时候思绪多,也会引发很多文字的产生。不知不觉,又是两千字,还都不在预料之中。
阿莲心理日记
我正襟危坐,感觉应该把今天发生的这个事情写下来。今天早上醒来的时候,大约是五点四十七分,算算时间,我昨晚是十点四十七分睡的觉,大概又是七个小时。但是我醒来之后的状态还不错,近几天,气温降了下来,我晚上睡觉盖的还是天丝夏被,已经算是很有凉意了。然而,我晚上的睡眠质量也还可以,这让我觉得可能是我的身体素质由于最近的跑步和泡脚得到了改善。我抬头看了看外面的天气,仿佛是没有下雨的样子。于是,我打开手机的天
- 外婆的皂角树
上官飞鸿
外婆出生的解放前一个战火纷飞的年代。外婆从小家庭贫困,日子过得非常艰难,这炼就了她艰苦朴素的性格。小时候,农村的经济非常的落后,洗衣粉还不够普及。在那个年代,每次洗衣服能用得起洗衣粉的都是有钱人,家穷苦人家经常是用不起洗衣粉的,只能拿到小河边或者水井边用皂角来洗衣服。我记得,在外婆家不远的水井旁边有一棵很大很大的皂角树。这一棵皂角树听人说已经有超过半个世纪的树龄了。皂角树高约二十米,整个树阴所能延
- 第八章———把控制感带进学校
林_2179
文章类型A起始段落:我们见过很多讨厌上学的孩子。这种讨厌事出有因,在校学生的控制感确实会随着年级升高而逐渐走低。为了帮我们的孩子管理好他们自己的学校生活,我们恐怕需要先花点时间来站在学生的角度想一想,他们在学校究竟感受如何。他们在低年级的时候还有很多自由选择的机会,但逐渐接触到了强制性的家庭作业,干什么都要排队,上个厕所都要举手打报告,并且几乎在每时每刻都要完全遵守各种各样的要求。在学校里,很难见
- 《海市蜃楼》电影观后感
红斑鱼_
今天看了一部西班牙的电影——《海市蜃楼》,讲述的是平行世界改变人生轨迹的故事。我不懂这样的剧名翻译是否准确,我一直没有明白中文的这个剧名和故事本身有什么联系,当然也有可能它只是一个剧名,并没有想过要有关联吧。这部电影讲述了,男主人公尼克看到邻居杀死了自己的妻子,被杀人者发现后仓皇而逃被汽车撞死。25年后幸福的维拉和丈夫女儿一起搬进了这栋房子,发现了一部老旧的电视和摄影机。他们通过一直住在这儿的好友
- 人生苦短,只为功名利禄?
嵗月静好
唉,古人云:人生几何?的确,人生太短了,我们必须做点有意义的事儿。现下,人们不知道怎么了,车子,房子……一切向钱看,浮躁之风,蔚然盛行。难道,映着夕阳的余晖,和爱人一起散步;周末,回家陪陪父母,一起吃个团圆饭,不好吗?
- 今天新年啦(随想)
夏不语_
窗外的烟花,电视机的晚会开幕,终于有点过年的感觉了,昨天生日,忘记写文了,转眼,也坚持了一个月,时光匆匆,自己也匆匆的走着,或者走的方向不对,或者鞋子不合脚,不过总要走下去才知道那里要改进,所以,新年,我只送给自己两个字:勇敢。勇敢的坚持住自己所想,勇敢的去链接自己要链接的人,勇敢的尝试自己不想做的事。背景梳理下上个月的成就吧,一月份好像要做的都打折了,不过也有很多意外之喜,复盘,是为了走的更远!
- async await详解_async await会阻塞吗
本文目录一、简介二、async三、await四、案例附:直接量/字面量一、简介async/await是ES20717引入的,主要是简化Promise调用操作,实现了以异步操作像同步的方式去执行,async外部是异步执行的,同步是await的作用。二、asyncasync,英文意思是异步,当函数(包括函数语句、函数表达式、Lambda表达式)前有async关键字的时候,并且该函数有返回值,函数执行成
- 《甄嬛传》解读5:新人还未入宫,皇后已布局
思思安
新人入宫,将会改变后宫局势,现有嫔妃的境况会发生哪些变化呢?解读2曾说过,宫中只有欣常在能生。但欣常在怀孕后被皇后害得小产。小产后,华妃挂起了她的绿头牌,说是要她好好休息,不让侍寝。两头狼盯着一只小白羊,欣常在是在夹缝中生存。皇上登基后的大半年,因为年羹尧宠爱华妃,因为规矩每月十五去看皇后,只有宠幸欣常在不需要理由。欣常在生了一个女儿,又二次怀孕,小产后皇上还想翻她的牌子,不和其他人比,这一段时期
- 成功日记(Day814)
狮子座的兔子姑娘
1、睡到自然醒,起床定早饭。~0.5h。2、打车去马栏广场。~0.5h。3、和妈妈视频聊天。~0.25h。4、洗澡洗衣服。~0.5h。5、和g夙微信闲唠嗑。~0.5h。6、和z鹤微信闲唠嗑。~0.5h。7、和月、蛋、j丽微信闲唠嗑。~0.25h。8、肖老师告知了一下我卫生局的回复,说等对方的局长签字呢。~0.25h。心情:尚可。
- 2021-01-02 困境怕什么 往前走才是出路
YiYiDuo
早上看《阿里铁军》。成长的初期,即便现在大如阿里巴巴,也面对了很多的困境。1因为当时还是一个不太知名的公司,招不到本科生,选择销售的标准是手脚健全能说话的就行。经历3个月的培训,培训价值观念和一些销售技巧,这是很多企业没有的。经过这种密集的培训和学习,人与人之间的联结会更深刻。2早起因为想做国际化的大公司,在美国、香港和各地开办公室,给员工开十几万美元的薪水,当时的普通员工才两三千一个月,烧了几个
- 原来,逐渐老去的70后,终将成为“疏远亲戚”的第一代人
舒山有鹿
01费孝通先生在《乡土中国》中写道:“亲属关系是根据生育和婚姻事实所发生的社会关系。从生育和婚姻所构成的网格,可以一直推出去包括无穷的人,过去的、现在的和未来的人物。”我们所遇到的家族亲戚,都是生育以及婚姻延伸出来的人物,跟我们有着密切的血缘关系。而还有一些人,比如说亲家,虽然说没有血缘关系,但也有亲戚关系。总而言之,对于你身边的亲戚,你有着怎样的感觉呢?其实,每个人对于亲戚的态度,都是不一样的。
- 香坊区副区长孙凤玲深入成高子镇检查指导创城、防疫、防汛工作
成高子镇
7月2日,香坊区副区长孙凤玲深入成高子镇检查指导我镇创城、防疫、防汛工作。成高子镇党委副书记、镇长崔建军,党委委员、副镇长梅家瑞参加检查。凤玲副区长先后来到我镇香坊区成高子镇棚改项目施工现场、哈成路、成高子大街实地督导检查创城工作。凤玲副区长强调,针对创城工作,要拿出细致的方案,明确工作任务,落实具体措施。同时,针对我镇现阶段存在的问题,凤玲副区长提出,一是管线工程结束后要及时修整路边沟,清理路边
- Vue Element-UI下拉框搜索功能
逆风g
要实现这样的功能:上代码:核心:给下拉框新增加属性filterable:filter-method=dataFilter//下拉框开启搜索功能dataFilter(val){if(val){this.showEquipments=this.equipments.filter((item=>{returnitem.equipments.includes(val)}))}else{this.showE
- 日子还要继续!
定整
听说各地又把春节假期延长,为了控制疫情,大局我们都理解,也配合。但是有一些人却不顾一切地冲出家门,去工作,命也不要了。在生死面前,其他的都是小事,但是真有一件事比生死同样重要:赚钱。因为疫情过后,大家生活还是要继续,房贷,车贷,生活费都是要支出,一分钱难倒英雄汉!“贫穷最悲哀的地方,是总觉得出什么事情,只能拿命挡,命比纸还贱。”在这个瘟疫来临之际,我们才能静下来想想,我们这么拼命,最后得到什么,我
- 边缘人物(一)
鸡肉卷熊掌包
“我们都在被爱我们的人一再塑造,只要她们稍稍坚持下去,我们就会变成她们的作品。”【……】“我想要转学。”苏简辞在椅子上正襟危坐,双手搭在并拢的膝盖上,看着木桌对面的中年男人,说。中年男人穿着居家的休闲装,倚靠在椅背,有些无奈地看着跳脱的女儿,淡淡开口:“高三了,你安分点儿行吗?”苏简辞答非所问:“这就是我的十八岁成年愿望。”“你离十八岁生日还早着呢。”男人没有被苏简辞蒙骗。苏简辞叹了口气,心想年轻
- 黑暗中的一盏灯
一页书_f02c
怎么说呢?每个人的一生之中都有一盏明灯!你追逐的、你奋斗的、你久久不能释怀的,每次当我看到这盏明灯升起的时候,长久以来的希望有了落脚点,瞬间又感觉到异常空虚,时常想,时常安慰自己不好的事情就要结束,负能量就要烟消云散,可一直就是过不去,我需要看心理医生………
- 我可爱的帽子
橘子七掰
昨天晚上突然强烈的想去把早就相中的帽子买了,但去了才发现卖没了,只好买了第二喜欢的一个帽子。我戴着这个帽子真的不好看,把我的大圆脸盘子凸显无疑,我问一个朋友:是不是很奇怪,明明戴着不好看也要买?他:没有,喜欢就好,一生能钟意的东西不多,也许短暂的。是啊,人哪,总是想把自己喜欢的东西占为己有,不管合不合适……昨天晚上12:00突然被叫了学姐……心情复杂
- Android Studio 翻译插件 ECTranslation的安装使用
颖字传说
今天在wanAndroid群里见到这个插件(有种发现新大陆的感觉^_^),于是默默的记下插件名称,然后一番搜索,在此记录下安装步骤1、在AndroidStudio窗口中ctrl+alt+s打开setting面板这步就不截图了4、点击步骤三查中目标插件的“Install”(安装)按钮,安装即可,安装完成后点击settings面板上面的apply然后点击OK,这时候会提示重启Androidstudio
- 不是天气变热了,主要是要求变高了
小凡丫丫
姐姐突然在群里抛出来一个问题:老家县城哪里有带冷气的厕所?我随即很无语地追问到:为什么到厕所找空调呢?我妈很给力地给了我一个标准答案:有空调,上厕所就不怕出汗了啊!现代人上厕所都要找空调,到底是地球变热了,还是人类的要求变高了呢?上个月,姐姐给家里客厅按了空调,我表示有点吃惊。她说她家前后没有遮挡,很热,坐都坐不住。我说:“我们又不是没住过,小时候没觉得有多热啊!”(姐姐家就是我们在老家县城读书住
- 杨幂离婚,生涯规划师你怎么看?
紫柠檬Nancy
这两天朋友圈被杨幂,刘恺威的离婚事件刷屏。作为一名生涯规划咨询师,我其实一眼就能够看透离婚背后的真相:01人职匹配模型不过在揭露真相之前,我还需要先给大家安利一个生涯规划里面的基础模型,叫做CD模型,也叫人职匹配模型。这个模型可以作为一个很好的思维框架,来帮助我们梳理清楚在这个多变的大环境下:我们的职业,婚姻,生活,交友......甚至方方面面的困惑,以期更好地掌控自己未来的幸福生活。大家先来看看
- 【雪樵闲话---日更28天】人与人交往的本质是价值交换
雪樵闲话
日更28天和朋友聊天。朋友问,人与人之间的关系就互相利用?我说,利用这个词虽然不好听,像是贬义词。我的理解是,人与人交往的本质是价值的交换。简单点说,你价值越高,越有用,被交换的频次就越高。你的利用价值越大,别人就越愿意帮你。如果你不能给别人提供价值,或你认识的人不能给你提供价值,那么这种人脉的价值就很低;人脉变现的关键在于创造价值,然后去和别人交换,就是让你的价值被利用。人脉的基础是相互利用的价
- 100天(57)||知识的边界真的很远, 它真的有边界吗?
慕子清蒸
昨天也是我试工的第1天,是一个韩国的品牌。中文名名字霹雳霸,英文名字Rapido然后发现了两个问题:第1个是WPS必须好好学起来,还有英文必须学起来。好多介绍都是英文的。还发现rapido的设计师是非常非常有名气,英文名字叫wrong,这个名字叫李长荣。它其中涉及的一个系列是根据中国的敦煌石窟,结合韩国的进口面料元素设计的几款衣服。01那个品牌,是一个工作还是一个学习的机会我并不知道我有没有设计方
- 亦然回首(上)12
如画之语
第十二章个个都是“吃货”溜冰过后的第二个周末,下了课叶川叫住林亦然。他说:“明天无论如何都要一起出去吃个饭,咱们几个新疆老乡连在一起吃顿饭都这么难,真说不过去,明天不准再说有其它什么事了,要有也必须推掉,就咱们四个人,说定了。”叶川一口气说了一长串话。到了这份儿上,林亦然也不好推脱了。“好吧”她只能答应。第二天,四个人在学校东门口见面后,沿着马路朝南走去。不远处的一家川菜馆是学生们常去的地方。据说
- 《乖顺替身藏起孕肚成首富》叶芷萌厉行渊(都市言情小说)全文在线阅读
寒风书楼
《乖顺替身藏起孕肚成首富》叶芷萌厉行渊(都市言情小说)全文在线阅读主角:叶芷萌厉行渊简介:叶芷萌当了五年替身,她藏起锋芒,装得温柔乖顺,极尽所能的满足厉行渊所有的需求,却不被珍惜。直到,厉行渊和财阀千金联姻的消息传来。乖顺替身不演了,光速甩了渣男,藏起孕肚跑路。五年后,她摇身一变,成了千亿财团的继承人,资本界人人追捧的投行之神。重逢时,找了五年,疯了五年的某人,扔掉了所有自尊和骄傲,卑微哀求:“乖
- 统一思想认识
永夜-极光
思想
1.统一思想认识的基础,才能有的放矢
原因:
总有一种描述事物的方式最贴近本质,最容易让人理解.
如何让教育更轻松,在于找到最适合学生的方式.
难点在于,如何模拟对方的思维基础选择合适的方式. &
- Joda Time使用笔记
bylijinnan
javajoda time
Joda Time的介绍可以参考这篇文章:
http://www.ibm.com/developerworks/cn/java/j-jodatime.html
工作中也常常用到Joda Time,为了避免每次使用都查API,记录一下常用的用法:
/**
* DateTime变化(增减)
*/
@Tes
- FileUtils API
eksliang
FileUtilsFileUtils API
转载请出自出处:http://eksliang.iteye.com/blog/2217374 一、概述
这是一个Java操作文件的常用库,是Apache对java的IO包的封装,这里面有两个非常核心的类FilenameUtils跟FileUtils,其中FilenameUtils是对文件名操作的封装;FileUtils是文件封装,开发中对文件的操作,几乎都可以在这个框架里面找到。 非常的好用。
- 各种新兴技术
不懂事的小屁孩
技术
1:gradle Gradle 是以 Groovy 语言为基础,面向Java应用为主。基于DSL(领域特定语言)语法的自动化构建工具。
现在构建系统常用到maven工具,现在有更容易上手的gradle,
搭建java环境:
http://www.ibm.com/developerworks/cn/opensource/os-cn-gradle/
搭建android环境:
http://m
- tomcat6的https双向认证
酷的飞上天空
tomcat6
1.生成服务器端证书
keytool -genkey -keyalg RSA -dname "cn=localhost,ou=sango,o=none,l=china,st=beijing,c=cn" -alias server -keypass password -keystore server.jks -storepass password -validity 36
- 托管虚拟桌面市场势不可挡
蓝儿唯美
用户还需要冗余的数据中心,dinCloud的高级副总裁兼首席营销官Ali Din指出。该公司转售一个MSP可以让用户登录并管理和提供服务的用于DaaS的云自动化控制台,提供服务或者MSP也可以自己来控制。
在某些情况下,MSP会在dinCloud的云服务上进行服务分层,如监控和补丁管理。
MSP的利润空间将根据其参与的程度而有所不同,Din说。
“我们有一些合作伙伴负责将我们推荐给客户作为个
- spring学习——xml文件的配置
a-john
spring
在Spring的学习中,对于其xml文件的配置是必不可少的。在Spring的多种装配Bean的方式中,采用XML配置也是最常见的。以下是一个简单的XML配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.or
- HDU 4342 History repeat itself 模拟
aijuans
模拟
来源:http://acm.hdu.edu.cn/showproblem.php?pid=4342
题意:首先让求第几个非平方数,然后求从1到该数之间的每个sqrt(i)的下取整的和。
思路:一个简单的模拟题目,但是由于数据范围大,需要用__int64。我们可以首先把平方数筛选出来,假如让求第n个非平方数的话,看n前面有多少个平方数,假设有x个,则第n个非平方数就是n+x。注意两种特殊情况,即
- java中最常用jar包的用途
asia007
java
java中最常用jar包的用途
jar包用途axis.jarSOAP引擎包commons-discovery-0.2.jar用来发现、查找和实现可插入式接口,提供一些一般类实例化、单件的生命周期管理的常用方法.jaxrpc.jarAxis运行所需要的组件包saaj.jar创建到端点的点到点连接的方法、创建并处理SOAP消息和附件的方法,以及接收和处理SOAP错误的方法. w
- ajax获取Struts框架中的json编码异常和Struts中的主控制器异常的解决办法
百合不是茶
jsjson编码返回异常
一:ajax获取自定义Struts框架中的json编码 出现以下 问题:
1,强制flush输出 json编码打印在首页
2, 不强制flush js会解析json 打印出来的是错误的jsp页面 却没有跳转到错误页面
3, ajax中的dataType的json 改为text 会
- JUnit使用的设计模式
bijian1013
java设计模式JUnit
JUnit源代码涉及使用了大量设计模式
1、模板方法模式(Template Method)
定义一个操作中的算法骨架,而将一些步骤延伸到子类中去,使得子类可以不改变一个算法的结构,即可重新定义该算法的某些特定步骤。这里需要复用的是算法的结构,也就是步骤,而步骤的实现可以在子类中完成。
- Linux常用命令(摘录)
sunjing
crondchkconfig
chkconfig --list 查看linux所有服务
chkconfig --add servicename 添加linux服务
netstat -apn | grep 8080 查看端口占用
env 查看所有环境变量
echo $JAVA_HOME 查看JAVA_HOME环境变量
安装编译器
yum install -y gcc
- 【Hadoop一】Hadoop伪集群环境搭建
bit1129
hadoop
结合网上多份文档,不断反复的修正hadoop启动和运行过程中出现的问题,终于把Hadoop2.5.2伪分布式安装起来,跑通了wordcount例子。Hadoop的安装复杂性的体现之一是,Hadoop的安装文档非常多,但是能一个文档走下来的少之又少,尤其是Hadoop不同版本的配置差异非常的大。Hadoop2.5.2于前两天发布,但是它的配置跟2.5.0,2.5.1没有分别。 &nb
- Anychart图表系列五之事件监听
白糖_
chart
创建图表事件监听非常简单:首先是通过addEventListener('监听类型',js监听方法)添加事件监听,然后在js监听方法中定义具体监听逻辑。
以钻取操作为例,当用户点击图表某一个point的时候弹出point的name和value,代码如下:
<script>
//创建AnyChart
var chart = new AnyChart();
//添加钻取操作&quo
- Web前端相关段子
braveCS
web前端
Web标准:结构、样式和行为分离
使用语义化标签
0)标签的语义:使用有良好语义的标签,能够很好地实现自我解释,方便搜索引擎理解网页结构,抓取重要内容。去样式后也会根据浏览器的默认样式很好的组织网页内容,具有很好的可读性,从而实现对特殊终端的兼容。
1)div和span是没有语义的:只是分别用作块级元素和行内元素的区域分隔符。当页面内标签无法满足设计需求时,才会适当添加div
- 编程之美-24点游戏
bylijinnan
编程之美
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Random;
import java.util.Set;
public class PointGame {
/**编程之美
- 主页面子页面传值总结
chengxuyuancsdn
总结
1、showModalDialog
returnValue是javascript中html的window对象的属性,目的是返回窗口值,当用window.showModalDialog函数打开一个IE的模式窗口时,用于返回窗口的值
主界面
var sonValue=window.showModalDialog("son.jsp");
子界面
window.retu
- [网络与经济]互联网+的含义
comsci
互联网+
互联网+后面是一个人的名字 = 网络控制系统
互联网+你的名字 = 网络个人数据库
每日提示:如果人觉得不舒服,千万不要外出到处走动,就呆在床上,玩玩手游,更不能够去开车,现在交通状况不
- oracle 创建视图 with check option
daizj
视图vieworalce
我们来看下面的例子:
create or replace view testview
as
select empno,ename from emp where ename like ‘M%’
with check option;
这里我们创建了一个视图,并使用了with check option来限制了视图。 然后我们来看一下视图包含的结果:
select * from testv
- ToastPlugin插件在cordova3.3下使用
dibov
Cordova
自己开发的Todos应用,想实现“
再按一次返回键退出程序 ”的功能,采用网上的ToastPlugins插件,发现代码或文章基本都是老版本,运行问题比较多。折腾了好久才弄好。下面吧基于cordova3.3下的ToastPlugins相关代码共享。
ToastPlugin.java
package&nbs
- C语言22个系统函数
dcj3sjt126com
cfunction
C语言系统函数一、数学函数下列函数存放在math.h头文件中Double floor(double num) 求出不大于num的最大数。Double fmod(x, y) 求整数x/y的余数。Double frexp(num, exp); double num; int *exp; 将num分为数字部分(尾数)x和 以2位的指数部分n,即num=x*2n,指数n存放在exp指向的变量中,返回x。D
- 开发一个类的流程
dcj3sjt126com
开发
本人近日根据自己的开发经验总结了一个类的开发流程。这个流程适用于单独开发的构件,并不适用于对一个项目中的系统对象开发。开发出的类可以存入私人类库,供以后复用。
以下是开发流程:
1. 明确类的功能,抽象出类的大概结构
2. 初步设想类的接口
3. 类名设计(驼峰式命名)
4. 属性设置(权限设置)
判断某些变量是否有必要作为成员属
- java 并发
shuizhaosi888
java 并发
能够写出高伸缩性的并发是一门艺术
在JAVA SE5中新增了3个包
java.util.concurrent
java.util.concurrent.atomic
java.util.concurrent.locks
在java的内存模型中,类的实例字段、静态字段和构成数组的对象元素都会被多个线程所共享,局部变量与方法参数都是线程私有的,不会被共享。
- Spring Security(11)——匿名认证
234390216
Spring SecurityROLE_ANNOYMOUS匿名
匿名认证
目录
1.1 配置
1.2 AuthenticationTrustResolver
对于匿名访问的用户,Spring Security支持为其建立一个匿名的AnonymousAuthenticat
- NODEJS项目实践0.2[ express,ajax通信...]
逐行分析JS源代码
Ajaxnodejsexpress
一、前言
通过上节学习,我们已经 ubuntu系统搭建了一个可以访问的nodejs系统,并做了nginx转发。本节原要做web端服务 及 mongodb的存取,但写着写着,web端就
- 在Struts2 的Action中怎样获取表单提交上来的多个checkbox的值
lhbthanks
javahtmlstrutscheckbox
第一种方法:获取结果String类型
在 Action 中获得的是一个 String 型数据,每一个被选中的 checkbox 的 value 被拼接在一起,每个值之间以逗号隔开(,)。
所以在 Action 中定义一个跟 checkbox 的 name 同名的属性来接收这些被选中的 checkbox 的 value 即可。
以下是实现的代码:
前台 HTML 代码:
- 003.Kafka基本概念
nweiren
hadoopkafka
Kafka基本概念:Topic、Partition、Message、Producer、Broker、Consumer。 Topic: 消息源(Message)的分类。 Partition: Topic物理上的分组,一
- Linux环境下安装JDK
roadrunners
jdklinux
1、准备工作
创建JDK的安装目录:
mkdir -p /usr/java/
下载JDK,找到适合自己系统的JDK版本进行下载:
http://www.oracle.com/technetwork/java/javase/downloads/index.html
把JDK安装包下载到/usr/java/目录,然后进行解压:
tar -zxvf jre-7
- Linux忘记root密码的解决思路
tomcat_oracle
linux
1:使用同版本的linux启动系统,chroot到忘记密码的根分区passwd改密码 2:grub启动菜单中加入init=/bin/bash进入系统,不过这时挂载的是只读分区。根据系统的分区情况进一步判断. 3: grub启动菜单中加入 single以单用户进入系统. 4:用以上方法mount到根分区把/etc/passwd中的root密码去除 例如: ro
- 跨浏览器 HTML5 postMessage 方法以及 message 事件模拟实现
xueyou
jsonpjquery框架UIhtml5
postMessage 是 HTML5 新方法,它可以实现跨域窗口之间通讯。到目前为止,只有 IE8+, Firefox 3, Opera 9, Chrome 3和 Safari 4 支持,而本篇文章主要讲述 postMessage 方法与 message 事件跨浏览器实现。postMessage 方法 JSONP 技术不一样,前者是前端擅长跨域文档数据即时通讯,后者擅长针对跨域服务端数据通讯,p