缘起
最近室友都找实习。面试时,常被问到的是,一些基础的机器学习知识和最新的深度学习模型,比如 逻辑回归、正则项、f1的计算、类别不平衡的处理、LSTM、Attention、Transformer、word2vec、glove、ELMo、BERT等等。因此,我打算系统地、扎实地将这些知识学习一遍,同时将学习的笔记写成博客,以供自己以后查看。如果不幸帮助了别人,还可以收获一些虚荣:-)。对吧~
万事开头难。所以,先从学过的EM算法开始吧。
从贝叶斯公式到极大似然估计
贝叶斯估计
已知样本的特征向量,为了求样本的类别,我们可以使用经典的贝叶斯公式,求解已知特征向量时不同类别的概率,
然后,选择使得中最大的作为样本类别的估计值,即有
其中,被称为先验概率,可通过统计标记样本中不同类别样本的比例得到,即
被称为类条件概率,当样本的特征数为1且是为离散值时,
其中,表示特征为且类别为的样本数目。样本特征数不为1的情况,这里暂且不讨论。当特征的取值是连续值的时候,问题就复杂了起来。我们可以使用极大似然估计来解决这个问题。
极大似然估计
在极大似然估计中,我们首先假设服从一个概率分布,常用的是正态分布,即
记参数,当我们得到一组时,类条件概率随之确定。
为了求解,令所有类别为的样本集合为,假设中样本之间相互独立,那么有
被称为似然函数,它描述了参数的合理程度。一组合适的参数应能使得尽量大。所以,求解最直观的想法是找到一组使得最大。为了计算的方便,我们定义对数似然函数
于是,的估计值为
由于极值点往往在导数等于0的地方取得,我们常常通过求导的方法求解上式,即
解得
引入EM算法
在上一节,我们看到极大似然估计通过最大化似然函数的方法,找到模型的最佳参数。在这个过程中,我们需要对对数似然函数求偏导,令导数等于0,进而得到参数的估计值。然而,在某些复杂的模型中,由于存在“隐变量”,我们难以通过对对数似然函数求偏导的方法得到参数的估计值。
我们考虑如下的三硬币问题
假设有3枚硬币,分别记作A、B、C,这些硬币正面朝上的概率分别为。现进行如下的抛掷实验:首先掷硬币A,根据其结果选择硬币B和硬币C,如果是正面选择硬币B,如果是反面选择硬币C;然后掷选出的硬币,记录掷硬币的结果,正面记作1,反面记作0;独立地重复n次实验(这里,n=10),观测结果如下:
假设只能观测到掷硬币的结果,不能观测掷硬币的过程。问如何估计三硬币模型的参数。
记。首先,让我们尝试使用极大似然估计的方法,写出对数似然函数,然后求解。不妨令每次实验中硬币A的抛掷结果为,硬币B和C的抛掷结果为。于是
显然,的取值有0、1两种,并且。而当时,意味着选择了硬币C,此时;同理,当时,有。于是,上式可展开为
对于三硬币模型多次抛掷的结果,有
相应的对数似然函数为
事实证明对上式求偏导,令导数等于0,是无法得到解析解的。也就是极大似然估计无法解决上述问题。
使用EM算法求解
一方面,假设我们知道模型参数,我们就可以预测某次实验中的抛掷结果来源于硬币B的概率,不妨记,有
另一方面,假设我们已知每次实验中抛掷结果来源于硬币B的概率,我们就可以估计模型参数,即
也就是说,当我们已知模型参数的时候,我们可以计算的值;当我们知道的值时,我们可以估计模型参数。对于这种蛋鸡问题,使用迭代法求解是最好不过了。也就是,先假设一组模型参数,比如,然后计算的值;接着使用的值,去估计模型参数。重复上述过程多次之后,我们就可以得到。
在上述过程中,我们称为模型的隐变量,也即是无法观测到但也不是模型参数的变量。估计的过程称为E步,使用估计模型参数的过程称为M步。下面使用python实现了对三硬币模型的求解。
def E_step(pi,p,q,Y):
Mu = []
for y in Y:
pyz1 = pi * p**y * (1-p)**(1-y)
pyz0 = (1-pi) * q**y * (1-q)**(1-y)
mu = pyz1 / (pyz1 + pyz0)
Mu.append(mu)
return Mu
def M_step(Mu,Y):
n = len(Mu)
pi = sum(Mu)/n
p = sum([Mu[i]*Y[i] for i in range(n)]) / sum(Mu)
q = sum([(1-Mu[i])*Y[i] for i in range(n)]) / (n-sum(Mu))
return pi,p,q
def solve_tree_coin(Y,iter_num):
pi = p = q = 0.5
for i in range(iter_num):
Mu = E_step(pi,p,q,Y)
pi,p,q = M_step(Mu,Y)
print(pi,p,q)
if __name__ == "__main__":
Y = [1,1,0,1,0,0,1,0,1,1]
solve_tree_coin(Y,5)
说句题外话,三硬币问题是没有办法正确估计模型的参数。如和 在输出结果上是等价的。毕竟,对于这个模型观测数据太少了,任何方法对此都无能为力。
下面我们将正式地对EM算法进行介绍,并运用EM算法求解混合高斯模型。
EM算法的思想
在这里不介绍EM算法的形式化定义(因为没有必要),只是概括一下EM算法的核心思想。
EM算法的全称是Expectation Maximization Algorithm,也就是期望极大算法。EM算法适用于含有隐变量的模型。求解过程分为E步和M步:在E步中求解隐变量的期望;在M步中使用隐变量的期望代替隐变量的值,求解模型参数。
理论上(有兴趣的见李航的《统计学习方法),EM算法并不能保证得到全局最优值,而且很依赖所选取初始值的好坏,但EM算法简化了很多复杂问题的求解。计算机科学中的许多方法都是基于这样的思路。
使用EM求解GMM
首先介绍一下GMM。
GMM的全称是Gauss Mixture Model,即混合高斯模型,也就是将多个高斯分布叠加在一起。假设GMM中高斯分布的数量为M,那么相应的概率密度函数为
如下图就是一个GMM概率密度函数的函数图像。
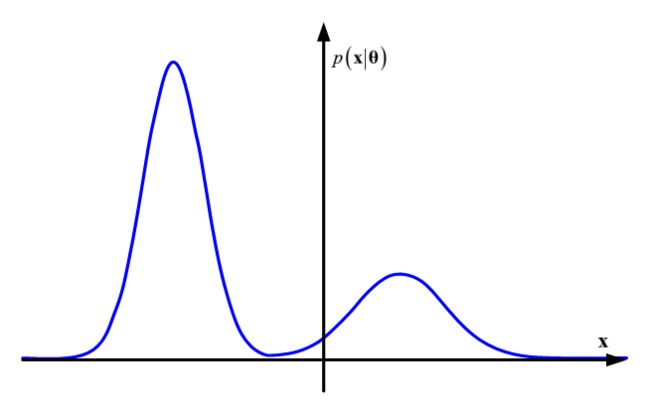
GMM产生样本的过程和三硬币模型有些类似,首先按照先验概率选择一个高斯分布,然后产生一个满足这个高斯分布的样本。如下图即为GMM产生的2维样本数据。

为了使用EM算法,我们首先要确定模型中的隐变量。在GMM中,隐变量是样本属于不同高斯分布的概率。于是在E步,我们这样估计隐变量
在M步,模型参数的估计过程如下
介绍EM算法的大多文章都是拿GMM举例的,但作为机器学习中的一类重要的思想,EM算法的应用非常广泛,如IBM翻译模型、主题模型等等。
先写到这里吧。