1.为查询缓存优化你的查询
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让MySQL不使用缓存。请看下面的示例:
// 查询缓存不开启
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// 开启查询缓存
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而开启缓存。
注:不针对MySQL,许多数据库都有查询缓存机制
2.EXPLAIN 你的 SELECT 查询(分析查询效率)
使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
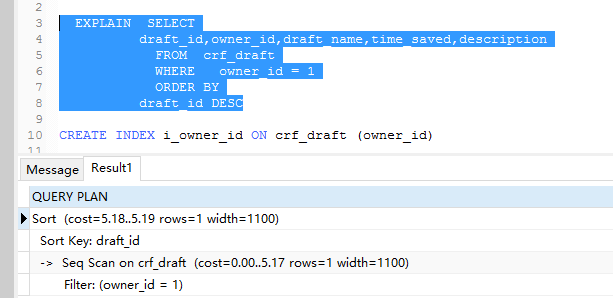
挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id
索引,并且有表联接:

3. 当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1)
// 没有效率的:
$r = mysql_query("SELECT * FROM user WHERE country = 'China'");
if (mysql_num_rows($r) > 0) {
// ...
}
// 有效率的:
$r = mysql_query("SELECT 1 FROM user WHERE country = 'China' LIMIT 1");
if (mysql_num_rows($r) > 0) {
// ...
}
4. 合理使用索引
索引能加快查询速度,但是不是什么情况下都使用索引
增加索引的不利因素:
第一, 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二, 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三, 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引是建立在数据库表中的某些列的上面。因此,在创建索引的时候,应该仔细考虑在哪些列上可以创建索引,在哪些列上不能创建索引。
一般来说,应该在这些列上创建索引。
第一, 在经常需要搜索的列上,可以加快搜索的速度;
第二, 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
第三, 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
第四, 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
第五, 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
第六, 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
不适合创建索引的情况:
第一, 对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二, 对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三, 对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第 四, 当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
第五,不同于 CREATE INDEX 定义为主键或者唯一性约束的列 数据库间接地为这些列创建了索引,所以这些类不需要再创建为索引了
5.千万不要 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你却不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录
// 千万不要这样做:
$r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");
// 这要会更好:
$r = mysql_query("SELECT count(*) FROM user");
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] - 1);
$r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
7. 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。
所以,你应该养成一个需要什么就取什么的好的习惯。
// 不推荐
$r = mysql_query("SELECT * FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// 推荐
$r = mysql_query("SELECT username FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
原文链接:http://www.jfox.info/20-tiao-mysql-xing-nen-you-hua-de-zui-jia-jing-yan.html