这一回我们来深入im2col。我们会顺便介绍一下Cuda的c接口以及一些基本的cuda编程的概念。
Cuda Introduction
http://www.nvidia.com/content/GTC-2010/pdfs/2131_GTC2010.pdf
这是一个很好的入门指南。为了方便起见,我们略去原文中和我们这次需要使用的接口无关的篇幅简要复述。
概述
Cuda是Nvidia为了不了解显卡以及并行操作的人群提供的一个方便的接口。Cuda提供了自己的类C编译器nvcc,在C的基础上添加了关于N卡操作的关键字/接口。你可以直接使用nvcc编译你的程序,也可以把给CPU跑的程序和给GPU跑的代码分别写在.cu,.cpp,把他们分辨编译成.cuo,.o,最后再通过链接器组成一个完整的程序。nvcc提供了比较方便的编程方式,把多流处理器并行处理程序的概念抽象成类似于进程/线程的结构方便使用。同时还提供了cublas这种官方优化过的blas库。
内存管理
Cuda的内存和CPU的内存是分开管理的,Cuda提供了互相映射的办法。Cuda中把GPU内存称为Device,把CPU内存称为Host
int main( void ) {
int a, b, c; // host copies of a, b, c
int *dev_a, *dev_b, *dev_c; // device copies of a, b, c
int size = sizeof( int ); // we need space for an integer
// allocate device copies of a, b, c
cudaMalloc( (void**)&dev_a, size );
cudaMalloc( (void**)&dev_b, size );
cudaMalloc( (void**)&dev_c, size );
a = 2;
b = 7;
// copy inputs to device
cudaMemcpy( dev_a, &a, size, cudaMemcpyHostToDevice );
cudaMemcpy( dev_b, &b, size, cudaMemcpyHostToDevice );
// launch add() kernel on GPU, passing parameters
add<<< 1, 1 >>>( dev_a, dev_b, dev_c );
// copy device result back to host copy of c
cudaMemcpy( &c, dev_c, size, cudaMemcpyDeviceToHost );
cudaFree( dev_a );
cudaFree( dev_b );
cudaFree( dev_c );
return 0;
}
我们简单地看一下这一份代码,略去
add<<< 1, 1 >>>(dev_a, dev_b, dev_c);
这一行代码不看的话。我们可以发现这好像和C的malloc, memcpy, free差不多。我们来回顾一下c的分配内存,复制内存,释放内存的办法。(以下摘自http://cplusplus.com/

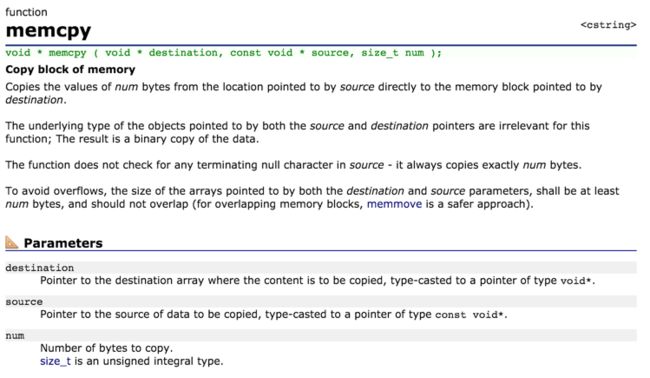

可以发现,除了cudaMemcpy需要注明一下从Host到Device或者是从Device到Host以外,cudaMemcpy,cudaFree和c的memcpy,free区别不大。比较奇怪的cudaMalloc,为什么传入的参数是指针的指针?其实也很好理解,我们实际上要改变的是指针的值(也就是指针的地址),如果我们把指针传进去,只能够改变原来指向的内存的部分,不能改变指针上的值,所以我们把它的指针穿进去就可以改变它指向的值了(实际上C++的引用传参就是这个原理)。
global 关键字
cuda巧妙地把多核并行运行的操作抽象成了我们熟悉的进程/线程的概念。举个大家熟悉的例子,python使用多进程的例子。原blog地址http://blog.sina.com.cn/s/blog_951bb8a101017icd.html
from multiprocessing import Process
def f(name):
print 'hello', name
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
大多数多进程/线程库的设计都是,把运行器(Process)当做一个工厂,把你定义需要并行的多进程库当做一个工作,把工作分配给工厂这样一个设计模式。Cuda提供的接口和这个很像。Cuda定义了两种概念分别对应进程和线程: block(对应进程), thread(对应进程)。如果我们要定义一个并行工作,那么我们要给这个函数顶一个__global__关键字(这个关键字是nvcc提供)。我们考虑一个n维向量加法的任务。
我们把上面的代码重新写一次
__global__ void add( int *a, int *b, int *c ) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
c[index] = a[index] + b[index];
}
#define N (2048*2048)
#define THREADS_PER_BLOCK 512
int main( void ) {
int *a, *b, *c; // host copies of a, b, c
int *dev_a, *dev_b, *dev_c; // device copies of a, b, c
int size = N * sizeof( int ); // we need space for N integers
// allocate device copies of a, b, c
cudaMalloc( (void**)&dev_a, size );
cudaMalloc( (void**)&dev_b, size );
cudaMalloc( (void**)&dev_c, size );
a = (int*)malloc( size );
b = (int*)malloc( size );
c = (int*)malloc( size );
random_ints( a, N );
random_ints( b, N );
// copy inputs to device
cudaMemcpy( dev_a, a, size, cudaMemcpyHostToDevice );
cudaMemcpy( dev_b, b, size, cudaMemcpyHostToDevice );
// launch add() kernel with blocks and threads
add<<< N/THREADS_PER_BLOCK, THREADS_PER_BLOCK >>>( dev_a, dev_b, dev_c );
// copy device result back to host copy of c
cudaMemcpy( c, dev_c, size, cudaMemcpyDeviceToHost );
free( a ); free( b ); free( c );
cudaFree( dev_a );
cudaFree( dev_b );
cudaFree( dev_c );
return 0;
}
代码中threadIdx.x, blockIdx.x是nvcc在__global__关键字定义的函数中直接定义出的变量。意义是当前所属的block和thread。调用__global__申明的函数的不仅需要调用普通函数需要传入参数,还需要指定运行这个函数你所分配的block和thread。(注意写在三对尖括号中,用逗号隔开)
GLOBAL_FUNCTION<<< block_num, thread_num >>> (params...)
特别需要指出的是,block之间不能共享内存。如果在thread之间如果要声明共享内存的话,使用__shared__关键字。这个例子我们会在下面的同步问题中一起给出代码。
同步问题
说到并行就不得不提锁和同步的问题。这也是软件开发中的日经问题了。我们来看看Cuda中对于同步提供的接口。同样地,我们也通过一个例子来说一下。这个例子我们就举一下内积问题。内积分成两个部分,第一部分把对应的元素相乘,第二步加和。同步问题就会出现了:如果我们把内积分成两部分来做,那么加和的操作必须要等到所有的乘积运算结束之后才能运行;如果我们在乘积结束之后直接把当前的乘积值加入到累加器中,那么我们又面临着加法原子性的问题。我们通过例子分别解释这两种方法如何实现。
__global__ void dot( int *a, int *b, int *c ) {
// All threads in the same block
// share `temp` array
__shared__ int temp[N];
temp[threadIdx.x] = a[threadIdx.x] * b[threadIdx.x];
// wait for all thread
__syncthreads();
if( 0 == threadIdx.x ) {
int sum = 0;
for( int i = 0; i < N; i++ )
sum += temp[i];
*c = sum;
}
}
int main() {
...
dot<<<1, N>>>(a, b, c);
...
}
上面这段代码中我们介绍了如何声明同一block下同步内存的__shared__的使用方法,如何等待其他thread同步到同一点的__synchthreads()函数,以及强调了同步问题只能在thread中使用(调用是只分配了一个block)。
我们再介绍另外一种方法。
__global__ void dot( int *a, int *b, int *c ) {
// All threads in the same block
// share `temp` array
__shared__ int temp[N];
temp[threadIdx.x] = a[threadIdx.x] * b[threadIdx.x];
// assume that c[0] == 0
atomicAdd(c , temp[threadIdx.x);
}
以及multiblock的办法
#define N (2048*2048)
#define THREADS_PER_BLOCK 512
__global__ void dot( int *a, int *b, int *c ) {
__shared__ int temp[THREADS_PER_BLOCK];
int index = threadIdx.x + blockIdx.x * blockDim.x;
temp[threadIdx.x] = a[index] * b[index];
__syncthreads();
if( 0 == threadIdx.x ) {
int sum = 0;
for( int i = 0; i < THREADS_PER_BLOCK; i++ )
sum += temp[i];
}
}
Caffe im2col

上面代码中的height_col和width_col分别是卷积之后的长宽(下一层的长宽)
我们久违地见到了这个函数
im2col_gpu_kernel
<<>>(
num_kernels, data_im, height, width, kernel_h, kernel_w,
pad_h, pad_w, stride_h, stride_w,
dilation_h, dilation_w, height_col, width_col, data_col);
可以知道这是一个template,同时带一个__global__关键字的。我们继续回溯看看im2col_gpu_kernel的实现。
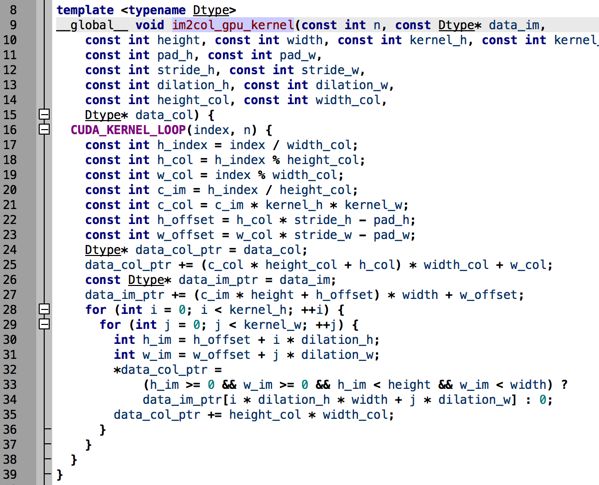

整个过程都比较繁琐,代码需要自己去慢慢理解。为了方便大家理解我在这里告诉大家。我们原来的图片是一个channel X height x width一个三维数组转换成一个(kernel_height * kerner_width * channel) x (height_col * width_col)一个矩阵。