最近两个月的时间,很少发文章,实在抱歉,你们可能好奇突然消失的我究竟干嘛去了呢?转行了?失踪了?... 咳咳,你们也甭猜测了,我实话实说好了。
有一天下午,和好朋友傅爷出去吃饭,期间,傅爷向我提了一个在他看来level很low的问题:“你知道局部性原理嘛?”
我还清晰地记得上次被傅爷问及到一些算法题目的时候自己惨遭鄙视的情景,难道这次又来挑衅我?思索片刻,我十分淡定地回答道:“不知道...那是什么原理啊?怎么从来没有听说过啊”
接着傅爷又问了我一个问题:“你了解计算机的体系结构嘛?” 我:“...” 傅爷:“...”
“作为一名程序猿,竟然连体系结构这种基本的知识都不知道,还好意思称呼自己是程序猿?” 一时无语的傅爷对我嗤之以鼻地说道。再次惨遭鄙视有木有u(T_T) !!!
“一个人最大的悲哀莫过于从未察觉到自己的无知吧,啊!没文化,真可怕。”我心里这么嘀咕着自己。
乐于传道授业的傅爷见我已经意识到了自身的不足和无知,便随手向我扔了一本书,并撂下一句话:“少年,回去好好读一读吧”,事后拂衣去,深藏功与名。

(哈哈,开玩笑了,真迹在下面↓)

傅爷推荐,必属精品,于是乎,受完刺激的我,利用两个月的业务时间把它从头到尾读了一遍。
好吧,今天的主角就是它《深入理解计算机系统》——一本介绍计算机系统的扛鼎之作。本着分享学习和经验的目的,我想把书中的章节内容简要介绍给大家,同时也是作为个人今后巩固知识的指导笔记吧。
简单谈一下阅读此书后的感受
《深入理解计算机系统》(简称CS:APP)是我目前读到的最好的计算机书籍,它从程序员的角度阐述了计算机系统相关的本质概念,清晰透彻地描绘了计算机体系结构、信息编码、链接、异常控制、虚拟内存、并发等方方面面的知识,读后,让非计算机专业出身的我对计算机内部的运作机理有了更加深刻的认识,那些过往模糊的概念在脑海中也得到了全新整理和重塑,一时间,豁然开朗,视野开阔,醍醐灌顶,简直如获法宝,相见恨晚。
在正式介绍这本书之前,我觉得有必要先带大家认识一下这本书的两位作者——计算机届的神级人物:Randal E.Bryant和David R.O’Hallaron。
Bryant,麻省理工大学计算机博士学位,卡内基-梅隆大学计算机科学学院院长,被评为ACM院士、IEEE院士和美国国家工程院院士。从事本科生和研究生计算机系统方面课程的教学超过30年,在讲授计算机体系结构方面拥有丰富的理论知识和实践经验。
O’Hallaron,弗吉尼亚大学计算机科学博士学位,现为Intel匹兹堡实验室主任,卡内基-梅隆大学电子和计算机工程系副教授。他和Bryant教授一起开设了“计算机系统导论”课程,曾获得CMU计算机学院颁发的Herbert Simon杰出教学奖、高性能计算领域中的最高国际奖项—Gordon Bell奖。
待大家膜拜完二位大神之后,下面就正式开始我们今天的探索之旅吧。
前言介绍
「如果你研究和领会了这本书里的概念,你将开始成为极少数的“牛人”,这些“牛人”知道事情是如何运作的,也知道当事情出现故障时如何修复」这是书本前言部分中的一句话,也是整本书中最打鸡血的一句话,当初就是因为看到这句话,才坚定了读完此书的决心的[捂脸]。
读者应具备的背景知识
- 对Linux系统有一定的了解
- 对C和C++有一定的了解(只有Java经验,是不足够的),无论你的编程背景如何,推荐将Brian Kernighan和Dennis Ritchie著作的介绍C语言的经典“K&R”文献作为个人藏书的一部分。
本书概述
本书由12章组成,旨在阐述计算机系统的核心概念。内容概述如下:计算机系统漫游、信息的表示和处理、程序的机器级表示、处理器体系结构、优化程序性能、存储器层次结构、链接、异常控制流、虚拟内存、系统级I/O、网络编程、并发编程等。
第1章:计算机系统漫游
这一章通过研究“hello,world”这个简单程序的生命周期,介绍了计算机系统的主要概念和主题。其中印象最深的就是下面这幅图:

对程序员来说,了解编译系统如何工作是大有益处的,因为它可以辅助程序员优化程序性能,理解链接时出现的错误以及规避一些未知的安全漏洞。
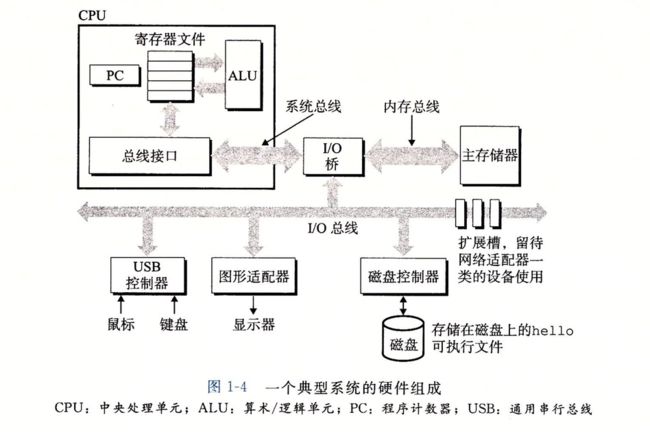
系统的硬件组成
为了帮助我们在脑海中建立一个深刻的印象,直观地感受系统的构成,作者介绍了一个典型系统的硬件组织图。这张图是Intel系统产品簇的模型,跟所有其他系统具有相同的外观和特性,书中其他章节将会对其进行详尽的介绍。
第2章:信息的表示和处理
现代计算机存储和处理以二进制为基础,以二值信号表示信息,这些普通的二进制数字,或者位(bit),形成了数字革命的基础。使用十进制对人类来说是很自然地事情,但是构造存储和处理信息时,二进制可以工作的很好。
单个位并不是非常有用,然而,把位组合在一起,再加上某种解释,即给予不同的可能位模式以含意。
三种比较重要的数字编码:
- 无符号 -- 基于传统的二进制表示法,表示大于或者等于零的数字。
- 补码 -- 表示有符号整数的最常见方式,有符号整数就是可以为正或者为负得数字。
- 浮点数 -- 表示实数的科学记数法的以二为基数的版本。
作者就整数的不同表示法之间的转换给予了讲解和理论证明,针对浮点数部分,又专门介绍了IEEE浮点表示的规范,帮助我们更加深刻的理解其中蕴藏的细节和原理。
第3章:程序的机器级表示
作者利用软件逆向工程的方法讲授本章内容,通过对目标可执行程序实施反汇编,剖析编译器产生的汇编代码,以此来加深我们对代码的认识和理解。本章涉及汇编方面的知识,即便你在这里缺乏经验和基础,也不会影响你的阅读。作者以一种“show me the code”的方式带着你理解汇编,认识汇编,而不局限于很多细小的语法,让仅仅懂得C语言的程序员也毫无障碍。仅仅100多页,不仅初步讲解了汇编的语法和使用,而且还配合了大量的示例程序来分析和解读它们生成的汇编代码,让人记忆深刻,不禁慨叹作者的匠心独运和深厚的计算机科学知识。
下面给大家看一个反汇编的例子:定义两个c文件main.c和mstore.c
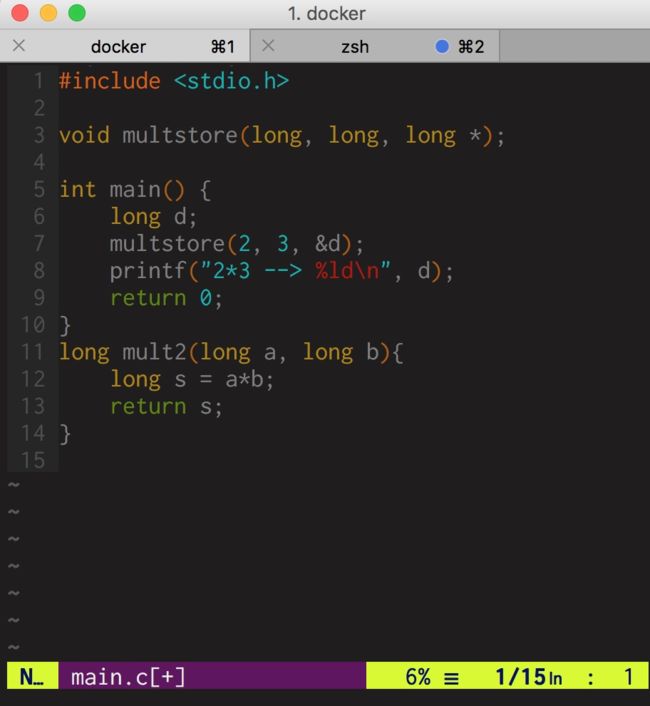

编译生成可执行文件prog
gcc -Og -o prog main.c mstore.c
对可执行目标程序prog进行反编译
objdump -d prog
下面是反编译后的部分截图:
第4章:处理器体系结构
现在微处理器可以称得上是人类创造出的最复杂的系统之一。本章将简要介绍处理器硬件的设计,研究一个硬件系统执行某种ISA(Instruction Set Architecture,指令集架构)指令的方式。
你很可能永远都不会自己设计处理器。因为这是专家们的任务,他们工作在全球不到100家的公司里。那么为什么还应该了解处理器设计呢?
学习事物是怎样工作的有其内在价值。了解作为计算机科学家和工程师日常生活一部分的一个系统的内部工作原理(特别是对很多人来说这还是个谜),是件格外有趣的事情。理解处理器如何工作可以帮助你更好地理解整个计算机系统如何演绎计算的精彩过程。相信你,看完本章,就会明白作者这样安排的用意。
下图展示了流水线式的Y86-64处理器的硬件结构。
第5章:优化程序性能
在这一章里,作者介绍了许多提高代码性能的技术,主要目的就是让程序员通过使编译器能够生成更有效的机器代码来学习编写C程序,确认和消除程序中的性能瓶颈。
现代编译器采用复杂的分析和优化形式,可以产生尽可能高效、具有指定行为的机器级程序。然而,即使是最好的编译器也会受到妨碍优化的因素的影响。程序员必须编写出容易优化的代码,以帮助编译器更好的发挥魔力。
作者谈到优化程序的第一步工作就是消除不必要的函数调用、条件测试和内存引用,让代码尽可能有效地执行所期望的任务。除此之外,就是利用处理器提供的指令级并行能力,增加并行度。
最后,以对优化大型程序的问题的讨论来结束这一章,特别描述了代码剖析程序(profiler)的使用,可谓是让读者朋友们开了一次眼界,真会领会程序优化后的性能差异变化。
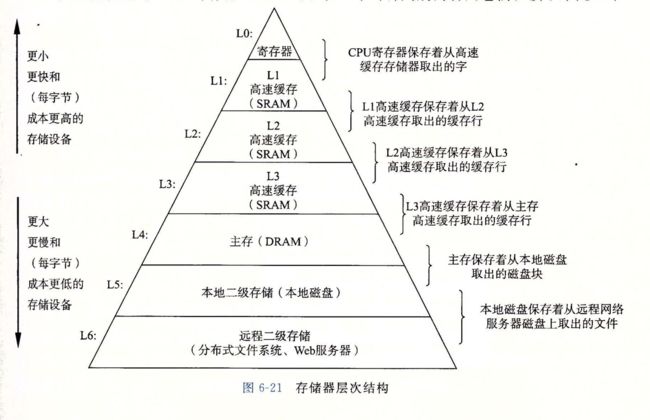
第6章:存储器层次结构
“存储器层次结构”实际上可以看作是“优化程序性能”一章的延伸,以及为之后的“虚拟内存”做铺垫。这章主要介绍了存储器的层次结构,详细解释了高速缓存(cache)的工作方式,以及利用局部性(ps:原来傅爷说到的局部性就在这里...[捂脸])使得cache达到最好效果的方法。
存储器系统是一个具有不同容量、成本和访问时间的存储设备的层次结构。作为一个程序员,你需要理解存储器的层次结构,因为它对应用程序的性能有着巨大的影响。
如果你的程序需要的数据是存储在CPU寄存器中的,那么在指令的执行期间,在0个周期内就能访问到它们。如果存储在高速缓存中,需要4~75个周期。如果存储在主存中,需要上百个周期。而如果存储在磁盘上,则需要大约几千万个周期!
下图展示了存储器系统的层次结构。
作者谈到计算机系统中一个基本而持久的思想:如果你理解了系统是如何将数据在存储器层次结构中上上下下移动的,那么你就可以编写自己的应用程序,使得它们的数据项存储在层次结构中较高的地方,因为在那里CPU能更快地访问到它们。
这个思想围绕着计算机程序的一个称为局部性(locality)的基本属性。具有良好局部性的程序倾向于一次有一次地访问相同的数据项集合,或是倾向于访问邻近的数据项集合。具有良好局部性的程序比局部性差的程序更多地倾向于从存储器层次结构中较高层次处访问数据项,因此运行得更快。
在本章中,读者还可以了解到基本的存储技术——SRAM存储器、DRAM存储器、ROM存储器以及旋转的和固态的硬盘,学习如何分析C程序的局部性,并且掌握一些改进你的程序中局部性的技术。
第7章:链接
链接(linking)是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。链接可以执行于编译时(compile time),也就是在源代码被翻译成机器代码时;也可以执行于加载时(load time),也就是在程序被加载器(loader)加载到内存并执行时;甚至执行于运行时(run time),也就是由应用程序来执行。
链接通常是由链接器来默默处理的,对于那些在编程入门课堂上构造小程序的学生而言,链接不是一个重要的议题。那么,为什么还要这么麻烦地学习关于链接的知识呢?
关于这个问题,作者从下面几点给予了解答。
- 理解链接器将帮助你构造大型程序。
- 理解链接器将帮助你避免一些危险的编译错误。
- 理解链接将帮助你理解语言的作用域规则是如何实现的。
- 理解链接将帮助你理解其他重要的系统概念。
- 理解链接将使你能够利用共享库。
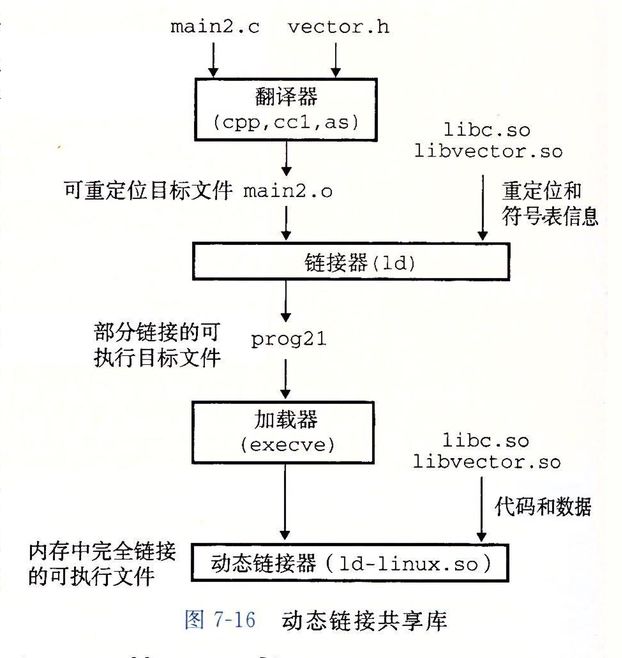
本章提供了关于链接各方面的全面讨论,从传统静态链接到加载时的共享库的动态链接,以及到运行时的共享库的动态链接。中间还讲到了符号表、符号解析、重定位等知识,另外介绍了库打桩技术和常用的处理目标文件的工具(如下所述)。
此处引用上文中示范的main.c文件产生的可重定位目标文件main.o,简单show一下几个常用的工具,提前帮你揭露目标文件中隐藏的秘密。
准备工作
# 生成汇编文件main.s
$ gcc -Og -S main.c
# 生成可重定位的目标文件main.o
$ as -o main.o main.s
- READELF:显示一个目标文件的完整结构,包括ELF头中编码的所有信息,包括SIZE和NM的功能。所下图所示:
- STRINGS:列出一个目标文件中所有可打印的字符串。效果如下:
$ strings main.o
2*3 --> %ld
GCC: (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4
.symtab
.strtab
.shstrtab
.rela.text
.data
.bss
.rodata.str1.1
.comment
.note.GNU-stack
.rela.eh_frame
main.c
main
multstore
__printf_chk
mult2
- NM: 列出一个目标文件的符号表中定义的符号。
$ nm main.o
U __printf_chk
0000000000000000 T main
0000000000000040 T mult2
U multstore
- SIZE:列出目标文件中节的名字和大小。
$ size main.o
text data bss dec hex filename
157 0 0 157 9d main.o
OBJDUMP:所有二进制工具之母。能够显示一个目标文件中的所有信息。它最大的作用是反编译.text节中的二进制指令。具体效果可参考上文中的示例。
LDD 列出一个可执行文件在运行时所需要的共享库。
$ ldd prog
linux-vdso.so.1 (0x00007ffd6f7f6000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f6d3e9ee000)
/lib64/ld-linux-x86-64.so.2 (0x000055bbbd754000)
第8章:异常控制流
对系统的学习,到目前这个章节为止,你已经了解了应用是如何与硬件交互的。本章的重要性在于你将开始学习应用是如何与操作系统交互的。有趣的是,这些交互都是围绕着异常控制流(Exceptional Control Flow,简称ECF)进行展开的。
ECF发生在计算机系统的各个层次,是计算机系统中提供并发的基本机制。比如,在硬件层,硬件检测到的事件会触发控制突然转移到异常处理程序。在操作系统层,内核通过上下文切换将控制从一个用户进程切换到另一个用户进程。在应用层,一个进程可以发送信号到另一个进程,而接收者会将控制突然转移到它的一个信号处理程序。
作为程序员,理解ECF很重要,作者给出了以下几个理由:
- 理解ECF将帮助你理解重要的系统概念。ECF是操作系统用来实现I/O、进程和虚拟内存的基本机制。
- 理解ECF将帮助你理解应用程序是如何与操作系统交互的。应用程序通过使用一个叫做陷阱(trap)或者系统调用(system call)的ECF形式,向操作系统请求服务。
- 理解ECF将帮助你编写出有趣的新应用程序。操作系统为应用程序提供了强大的ECF机智,用来创建新进程、等待进程终止、通知其他进程系统中的异常事件及检测和响应这些事件。
- 理解ECF将帮助你理解并发(第12章会更详细地研究并发)。
- 理解ECF将帮助你理解软件异常是如何工作的。像C++和Java这样的语言通过try catch以及throw语句来提供软件异常机制。
下图展示了实现多任务的较高层形式ECF的上下文切换过程。
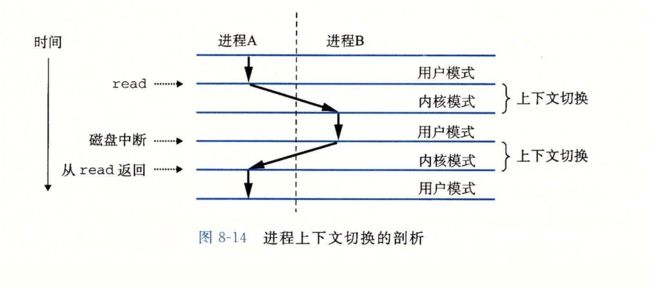
本章主要讨论了有关ECF机制的知识,关于进程和信号,作者只做了简要的描述。如果您对进程、信号的实现细节感兴趣的话,推荐阅读Bovert和Cesati的著作《深入理解Linux内核》,这本书给出了非常清晰的描述。
第9章:虚拟内存
虚拟内存(VM)是计算机系统最重要的概念之一。它为每个进程提供了一个大的、一致的和私有的地址空间。通过一个很清晰的机制,虚拟内存提供了三个重要的能力:
- 它将主存看作是磁盘的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传递数据,通过这种方式,它高效地使用了主存。
- 它为每个进程提供了一致的地址空间,从而简化了内存管理。
- 它保护了每个进程的地址空间不被其他进程破坏。
这一章从两个角度来看虚拟内存。前一部分描述虚拟内存是如何工作的,后一部分描述的是应用程序是如何使用和管理虚拟内存的。无可避免的事实是虚拟内存很复杂,但是如果你掌握了其中的细节,虚拟内存将永远不在神秘。
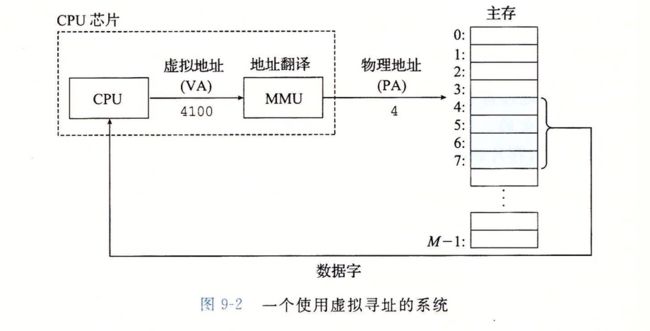
下图展示了一个使用虚拟寻址的系统。
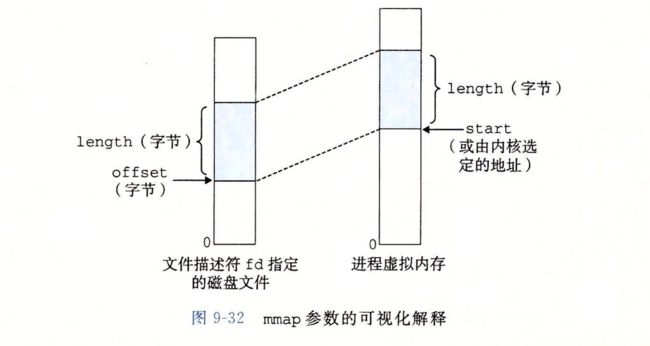
下图展示了用于将磁盘文件映射到虚拟内存的mmap参数的可视化解释。
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
第10章:系统级I/O
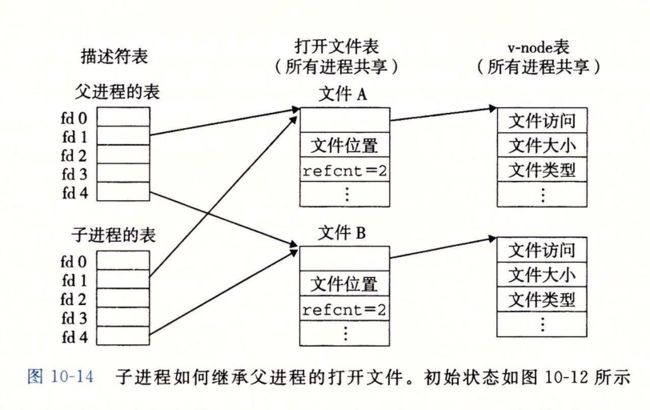
输入/输出(I/O)是主存和外部设备(例如磁盘驱动器、终端和网络)之间复制数据的过程。这一章介绍Unix I/O和标准I/O的一般概念,并且向你展示在C程序中如何可靠地使用它们。除了作为一般性的介绍之外,这一章还为我们随后学习网络编程和并发性奠定坚实的基础。
附一父子进程打开文件的内部数据结构图。
第11章:网络编程
网络应用随处可见。任何时候浏览web、发送email信息或是玩在线游戏,你都在使用网络应用程序。有趣的是,所有的网络应用都是基于相同的基本编程模型,有着相似的整体逻辑结构,并且依赖相同的编程接口。
本章你将学习基本的客户端-服务器编程模型,以及如何编写使用因特网提供的服务的客户端-服务器程序。

第12章:并发编程
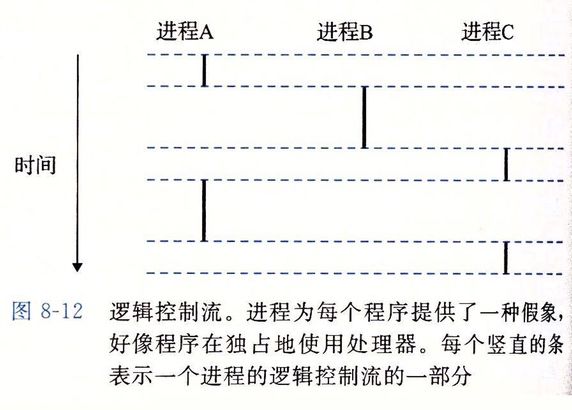
正如我们在第8章学到的,如果逻辑控制流在时间上重叠,那么它们就是并发的(concurrent)。
如下图所示:进程A和B并发地运行,A和C也一样,B和C则没有并发地运行。
在这一章里,读者将会学习到三种不同的构建并发程序的机制:
- 进程。 每个逻辑控制流都是一个进程,由内核负责调度和维护。一个控制流可以使用(interprocess communication)IPC机制与其他流通信。
- I/O多路复用。应用程序可以在一个进程的上下文中显示地调度它们自己的逻辑流。所有的流共享同一个地址空间。
- 线程。线程是运行在一个单一进程上下文中的逻辑流,由内核进行调度。可以把线程看成是其他两种方式的混合体。
作者以一个并发网络服务器作为贯穿全章的应用示例,带你全面解读并发的这三种工作机制。除此之外,还向我们介绍了如何实现线程的同步,提高程序的并行性,进度图的概念,以及由并发引入的一些困难问题。比如:竞争、死锁、线程安全等。
附:顺序、并发和并行程序集合之间的关系图
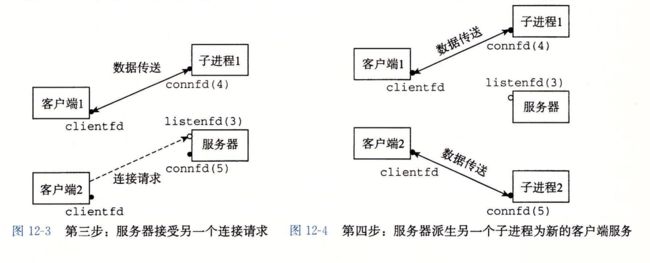
附:基于进程的并发编程:服务器—客户端模型
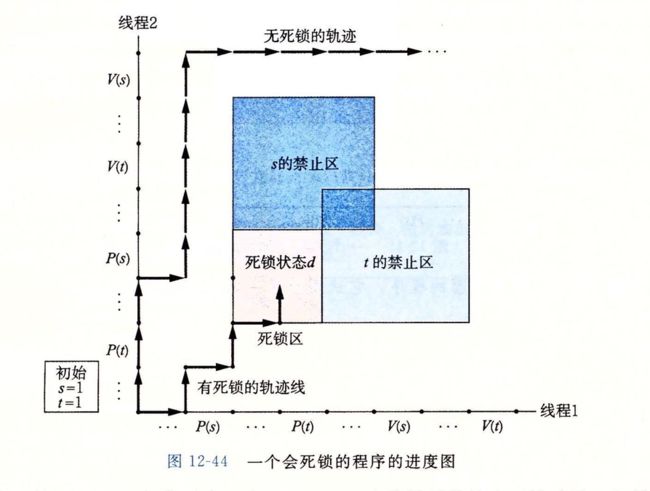
附:一张用于方便理解死锁的进度图。
写到最后
本书的一个目的是要把程序员带入权威行列,成为极少数的牛人,理解整个计算机系统,开拓技术视野、提高编程思路,可以说是程序员眼中透彻讲述计算机系统的旷世扛鼎之作。
纵览全书,CSAPP重点再讲述硬件和软件的结合、程序的结构和执行,后面章节则讲到些偏应用层面的东西。CSAPP在应用层知识的讲解上,点到为止,可谓是起了画龙点睛、抛砖引玉之作用。如果你想继续深入学习操作系统、了解更多有关网络编程方面的细节,推荐阅读APUE(Advanced Programming in the UNIX® Environment,UNIX环境高级编程)、UNP(UNIX Network Programming,UNIX网络编程)等书。相信读完这些书后,你一定会成为计算机领域的大牛。