Hadoop简介
*Hadoop 擅长处理一次写入,多次读出的数据
hadoop两大核心组件是 HDFS 和 mapreduce
不太适用于实时性较高,小文件较多以及多用户在写,任意修改的文件
Hadoop诞生背景:
Hadoop 提出者是doug cutting ;刚开始hadoop是Lucene中的小项目,2002年从Lucene中分发出Nutch,之后发现利用工具Nutch处理大规模搜索任务,遇到的瓶颈;后来google发布了自己 google file system 以及map 与reduce的任务;后来开发者在Nutch中实现了自己的mapreduce系统;后来通过NDFS以及mapreduce形成最初的hadoop原型;
2008-2009年google和yahoo, 在处理大规模数据(ITB)排序只用了68s 与 62s
2 简介hadoop几大组件;
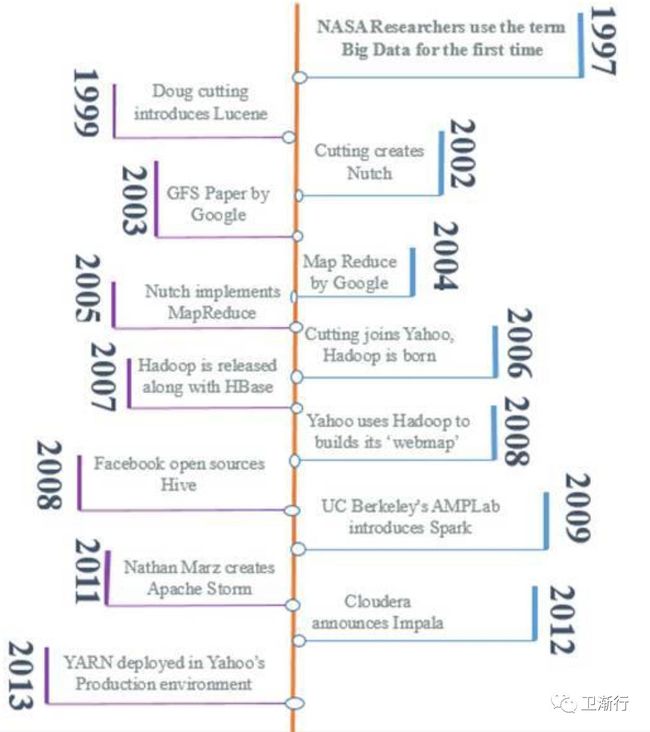
HDFS 分解常规的文件较小的chunks->blocks(默认最小地址为64M);然后将这些blocks冗余分布在不同的集群节点当中;一个HDFS读操作的过程如下:
用户将请求发送到namenode,然后找出文件对应block 放在集群的哪些位点;
Namenode 提供数据对应的blockIDS以及文件位点
用户通过上述信息,分别找出datanode对应blocksId对应数据 ( preserving the order
of the block)
HDFS写数据的过程如下:
用户通知nameNode,利用文件名更新命名空间;同时确认文件是否存在以及对应权限
如果文件存在,namenode跑出异常;否则,返回FSDataPutputstream给用户,并指向数据队列尾部;
namenode协调资源,将数据队列信息分发到何时的datanodes;
然后将数据拷贝到dataNode;按照复制策略;从该节点的数据拷贝到剩下可用的节点去;
特别重要的提醒;不通过namenode实现的数据写操作,存在性能的瓶颈;
如下图:
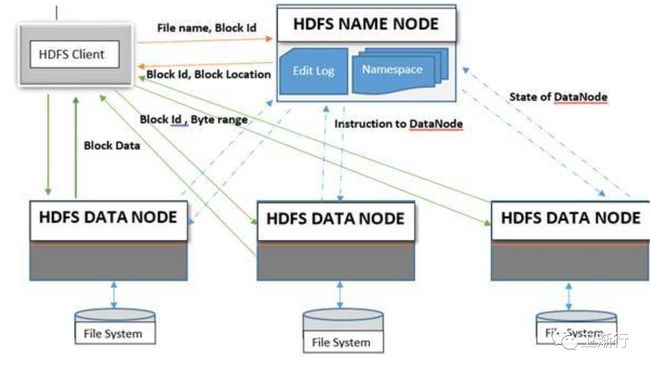
Yarn:yet another resource manager
Yarn 的基本方法是集群中的资源管理以及任务调度(管理)中心,是节点运行的守护线程;大致思路就是:集群拥有一个全局的resourcemanage 以及单个应用的应用管理;可以是单个任务应用,也可以是有向无环图的任务;
ResourceManage 以及NodeManager 组成了YARN的数据计算框架;
ResourceManage 是非常重要权威的部分,能够协调整个系统应用的资源;
NodeManager 是节点管理的代理,包含着容器的管理,监控者资源(资源包含着CPU,内存,磁盘空间,网络)的使用;同时将这些信息反馈到resourcemanager中;

ResourceManager 包含着两个组件:任务调度者(scheduler)以及应用管理者(applicationManager)
每个应用applicationmaster,实际上是一个特定的库和框架;主要任务是协调资源;并由ResourceManager与nodemanager工作(S)执行并监控任务。
Scheduler 分发资源到多个正在执行的应用,知晓每个节点的容量,队列个数的限制等;每个scheduler是运行到具体到单个节点,并能够管理和追溯应用的状态;同时由于应用执行的失败以及磁盘的读写失败时,它不提供恢复失败的功能,因此每个scheduler 的执行,都了解每个应用的资源要求,调用的规范;
任务调度者,有一个可拓展的策略,就是分配集群的资源在不同的队列当中,当前的任务单调度正,比如: CapacityScheduler 以及 FairScheduler 有一些示例;
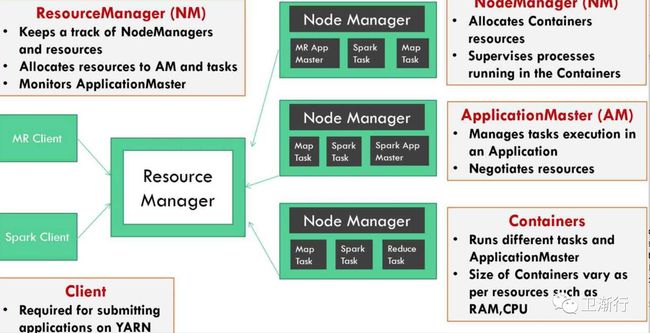
运行在YARN上的MR任务,能够分成五大步骤,
用户提交一个MR任务
resourceManager 请求一个应用的IDs;
检查输入数据的位置,以及计算split文件的大小
确定数据输出位置同样是存在的
如果上述三个条件都满足;MR按照任务的配置文件的详细信息,将文件复制到HDFS固定目录中,resourceManager命名应用的ID;然后将这个任务提交到resourceManager中,启动任务具体的应用master,MRappmaster;
Map phase
map 水平上,一旦RM收到用户的请求,加载MRAppMaster,收到的信息后,Yarn的调度器分配容器给应用;
对于每个可用的资源,可运行的容器,自从MRAppMster已经启动,就认为可以提供资源了;
MRAppmaster从用户提供的HDFS的路径中加载信息,分解成map,根据mapper的数量,计算出来所需的reducer;
(Uber tasks)如果MRAppMaster,找到了mapper以及reducer的个数,以及输入的数据能够在同样的JVM运行,就会进行下一步;
然后,在其他的情景下,MRmaster从正在运行的任务中协调容器的资源,albeit(虽然,尽管)maptask拥有高的优先级;
这也是Mapper tasks 必须先结束,然后才能进行排序的工作;
Shuffle(清洗数据) and sort phase
Notes:
A map task keeps updating the status to ApplicationMaster for its entire life cycle.
It is only when 5 percent of a Map task has been completed that the Reduce task starts;
An auxiliary() service in the NodeManager serving the Reduce task starts a Netty web server that
Makes a request to MRAppMaster for Mapper hosts having specific Mapper partitioned files ,All the
Partitioned files that pertain to the Reducer are copied to their respective nodes in a similar fashion.
Since multiple file get copied as data from various nodes representing that Reduce nodes gets
Collected, a background thread merges the sorted map file and again sorts them and if the combiner is
Configured ,then combines the result too;
考虑到环形buffer,有一定的大小限制;默认是内存的80%;线程从buffer取得数据;但是在拷贝数据到硬盘之前;计算,
先要根据reducer分区,然后后面的reducer根据key来排序,如果需要combiner的数据,则先combine(优化方案);
reduce阶段:
这是非常重要的提醒,在进行reduce之前,数据已经根据key,已经排序过;
reduce操作的时候,要将集合的key转化成列表的形式,一旦reducer处理数据,就会讲数据输出到job提交到路径下
清理阶段:
每个reducer发出一个任务结束的心跳信号给 MRAppMaster,一旦reduce任务完成,applicationMaster开始清理的任务;任务的状态由运行转化成完成状态;所有的临时文件将被删除,应用的执行的情况,归档到任务的历史数据管理的服务器上;
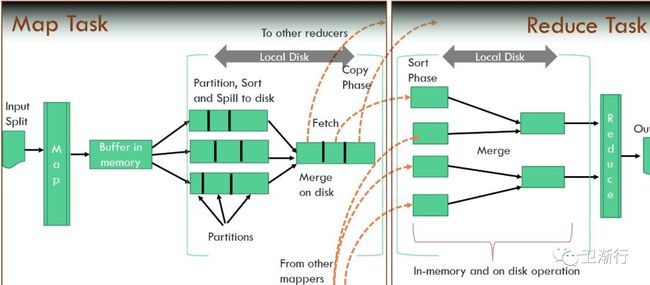
Notes:一般的mapreduce过程如下:
在map语法当中,数据的transformation起作用,它能够将数据分解key-value键值队的关键字;(combine)
Shuffle and sorted : group and sort
在reduce关键字,处理map结果数据的集合
举例简单说明如下:
Sample text:
Imagine there’s no heaven
It’s easy if you try
No hell beyond us
Imagine I think you’re right
执行map操作后:
执行reduce操作后

参考资料:
spark2.0 for java developer
hadoop权威指南第三版