面试常见的大数据之TopK
提纲
1. TopK之单节点;
2. TopK之多节点;
3. 实时TopK之低请求率;
4. 实时TopK之高请求率;
5. Approx topk
6. MapReduce
TopK之单节点(根据值进行排序)
描述:
给定一个无序的整数数组,根据值的大小找到最大/小的K个元素。list={3,10,1000,-99,98,99}, k=3,topK={1000,98,99}
1.哪一类数据结构可以解决该类问题? 优先队列
2.优先队列采用升序or降序? 升序
采用升序结构,给定n个数值,如果取出其中最大的k个数(n>>k),优先队列的大小只需要设置成k,而不需要设置成k,每一次操作的时间复杂度是lgK,那么总的时间复杂度就是nlgk。
采用降序结构,给定n个数值,如果选取出其中最大的k个数(n>>k),优先队列的大小需要设置成n,这样每一次的操作的时间复杂度是lgn,总的时间复杂度是nlgn。降序结构花费的时间远远大于升序结构。
TopK之单节点(根据频率进行排序)
问题:
给定一些系列的热门话题,找到最火的前K个。
1.数据预处理,分别计算每个热门话题出现的次数;采用HashMap统计话题次数。
2.优先队列。队列中存放 '话题+次数',这里需要新建一个数据结构。
key+Frequency
class Pair {
String key;
int frequncy;
public Pair(String key, int frequency) {
this.key = key;
this.frequency = frequency;
}
}
可是PriorityQueue并不知道如何对该数据结构进行排序,因此,还需要重写compare方法。
private Comparator pairComparator = new Comparator();
public int compare(Pair left, Pair right) {
//按照从小到大排序
return left.frequency - right.frequency;
}
时间复杂度:O(nlgk),空间复杂度:O(|n|+k),|n|代表不重复的数字个数。
TopK之多节点
场景一:
假设给一组10T文件,文件内容是10million用户,当天的微博搜索记录,求微博今日热搜?
此时不能再用单机解决,不可以:
● 文件太大,单机无法处理
● 处理速度太慢
因此,采用分布式进行处理。
处理流程:分 & 合
- 将大文件拆分成一个个小文件;
- 将小文件分配到不同的节点;
- 从每一个节点上获取TopK;
- 从上一步中得到的TopK计算,总结出最后的TopK。
TopK之多节点 -> 分
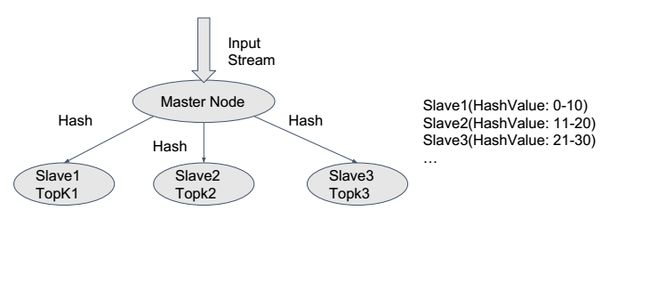
1.如何进行拆分?

根据文件顺序拆分?显然,这种方案不正确。
因此,我们采用hash方法(md5/sha1)。从整体保证了hash值相同的文件分配到相同的节点,但是该方案仍存在数据倾斜(data skew),导致某个节点过载,处理速度慢的缺点。针对这种情况,master侦测每一个slave的负载量,进行二次拆分,同样利用多节点的方式分担该节点的数据。
注意:
这里的拆分不能直接按照hash方法进行拆分,需要在第一次hash以后,获取出需要进行二次拆分的文件。此时,每读取一个大文件时加上一个标记,比如后缀(_01,_02),或者前缀。再利用hash方法拆分。合并时再去掉标记。
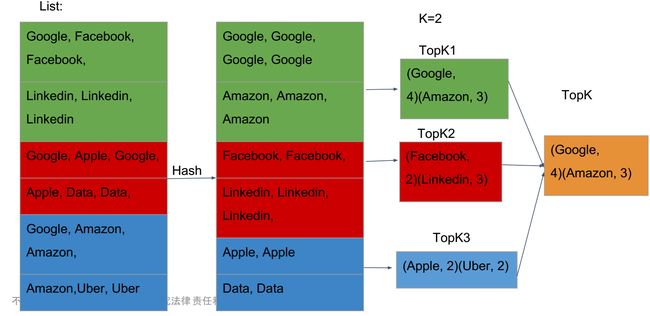
TopK之多节点 -> 合
1.TopK集合:{topk1,topk2,topk3,...};
2.最后的TopK。
场景二:
有N台机器, 每台机器各自存储单词文件,求所有单词出现频率的topK。
解决措施:
- 从每一个节点上分别获取TopK;
- 合并。
该方法同样并未考虑拆分时,同样的文件被分别到不同的节点。此时,需要对拆分后的文件再次进行rehash,再重复上述方法。
实时TopK之低请求率
场景一:
有实时数据流进入,需要实时计算topK。
解决措施:
- 当有新的数据流入时,将其写入磁盘的文件系统;
- 每当收到计算TopK请求,在磁盘上运行TopK算法;
- 获得Topk。
方案存在的缺陷:
- 重复工作。当计算已经存入磁盘中文件的TopK时,首先,计算每个唯一文件(unique words)的总数(hashMap数据结构),然后放入优先队列(PQ)中,得到此时的TopK。然而,当有新的文件写入磁盘时,各节点会对总的文件再次进行TopK计算,导致对最初的文件进行二次TopK计算。
- 处理速度过慢。磁盘文件读写速度慢。
改进措施:
- 当有新的数据进入时,将其写入内存中的hashMap;
- 当HashMap更新时,同时更新PQ;
- 得到TopK。
方案存在的措施:
- 内存溢出;
- 节点挂掉或者断电导致数据丢失。
数据丢失发生在哪一个阶段?
- HashMap? (Yes)
- Priority Queue? (No)
改进措施:
- 将数据存入磁盘中的数据库;
-
写入新的数据时,更新数据库中文件计数。
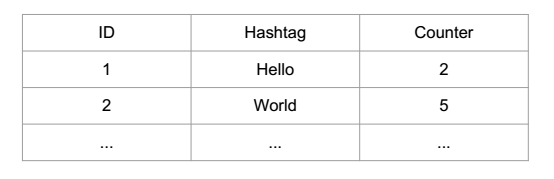
注意:
- 这里数据库取代的是HashMap,仍然保留了PQ。虽然数据库可以直接选出TopK,但是在数据量非常庞大的情况下,每当有新的数据写入时,数据库都会对所有的文件进行排序,这样做是非常耗时,耗资源,且极大部分的文件是与最后的TopK结果无关。
- PQ仍然存放在内存中。即使节点挂掉或者断电,再次重启时,新建的PQ只需要遍历数据库中的数据一遍即可得到新的TopK。
总结:文件数据写入磁盘数据库,PQ存放在内存中得到TopK。
疑问:这里的PQ和普通的PQ具有同样的功能吗?
● 存储TopK;
● 当有新的数据写入时,比较新的文件大小和PQ中的最小文件大小;
● 替换OR继续。
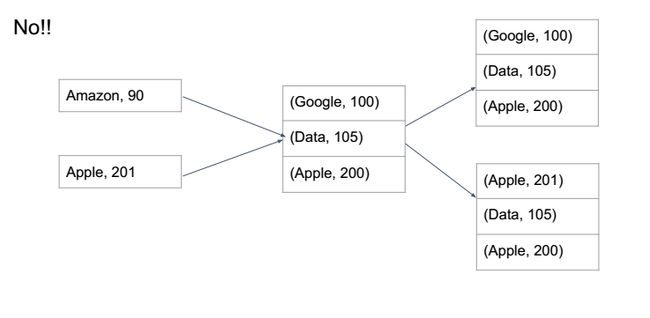
在替换PQ中原有值时,无法进行查找重复文件(key)的操作。原有的静态文件之所以可以运用PQ,是因为在已有文件的基础上对每一个唯一文件(unique words)先进行计数操作,PQ中不需要再考虑是否存在重复文件。
改进措施:TreeMap替换PQ
● 支持根据值进行排序;
● 支持PQ中的所有操作;
● 不仅如此,支持按key进行查找、删除操作。
实时TopK之高请求率
问题:
数据库无法实时响应,甚至停止响应 -> 高延迟。
解决措施:
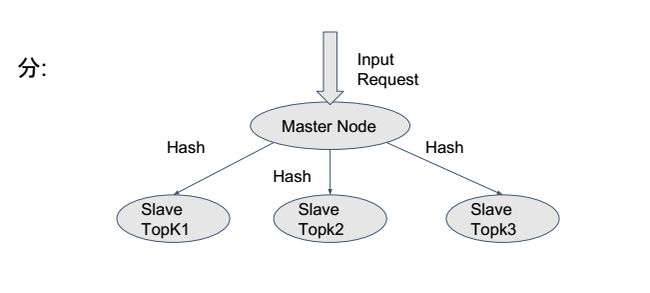

拆分原始请求数据,分配到每一个节点,分别写入各自的数据库中。这里的分配方法仍然采用Hash的方法。
问题:
如果其中的某一个文件(key)出现频率非常高,会导致什么结果? ->高延迟
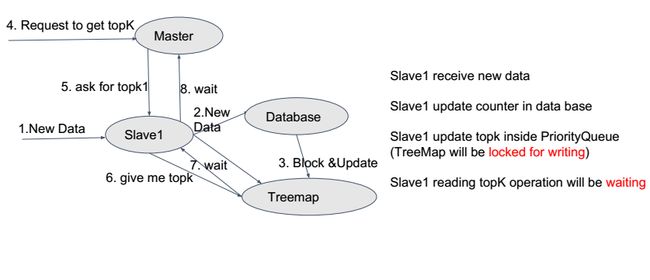
高延迟主要体现在:
- 数据量过大 ->写入数据库;
- 数据库一直被写入数据,导致TreeMap一直接收到数据库的数据写入时,最后TreeMap被锁住/更新,最后的结果一定不准确 ->写入TreeMap;
准确性 OR 时效性 ? -> 缓存(cache)换取时效性,缓存时仍需要考虑缓存大小和缓存时间。
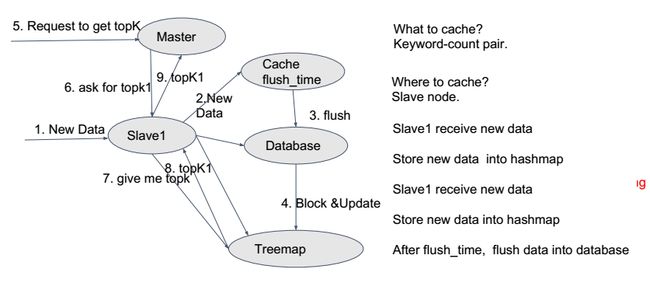
问题:
低频率的数据占据了大部分的磁盘空间。
解决措施:
a. Approx TopK算法 - 准确性换取空间利用率
- 新的数据写入时,更新hashMap/database中的count值;
- 更新treeMap中的TopK。
这里以HashMap为例:
key=word_hashValue, value=frequnecy,hashMap大小可以自定义。
缺点:
- 所有低频率出现的文件(单词)将会hash到一个value上,从而导致不正确的结果(出现情况极少)。
- 一些低频率的单词可能写入的时间比较晚,导致一替换掉其他高频率的单词(布隆过滤器)。
b.Mapreduce --只能处理静态数据,非实时
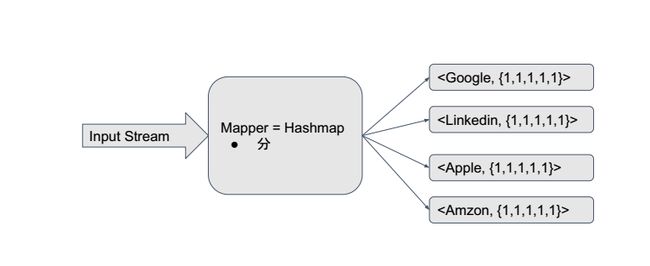
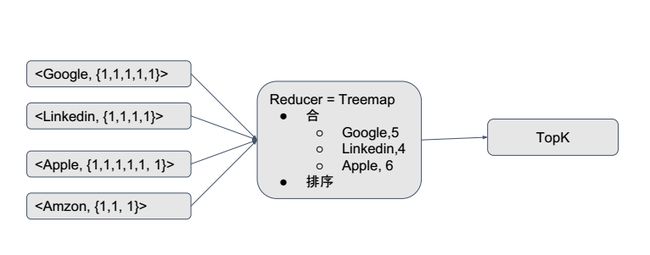
如果要处理实时数据
- datablocker->kafka接收数据;
- storm、spark Streaming实时处理数据。