
简评:本文通过实际范例教大家如何实现一个低配版国际象棋 AI。
文中的基本概念如下,先自行搜索以方便理解:
- move-generation
- board evaluation
- minimax
- alpha beta pruning
在每个步骤中,我们将使用其中某种技术来改进我们的算法,并且演示他们是如何影响象棋 AI 的执行效果。
你可以在 GitHub 上查看算法的最终版。
我无法打败我自己写的象棋程序,真不知道这是我太弱还是算法太好。
—— lhartikk
Step 1: 移动生成和边界可视化
使用 chess.js 库进行移动生成,并使用 chessboard.js 来显示棋盘。移动生成库基本上实现了棋的所有规则。基于此,我们可以计算出所有合法棋步。
移动生成功能的可视化。起始位置用作输入,输出是从该位置出发的所有可能的移动。

使用这些库将有助于我们专注于最有趣的任务:最佳棋步算法的构建。
首先,我们创建一个从所有可移动中返回随机移动的函数:
Gif:黑手随机移动
Step 2 : 位置评估
现在我们来评估哪一方在某一位置更强。可以用这个表来判断:

通过评估功能,我们可以创建一个选择提供最高评估的动作的算法:
var calculateBestMove = function (game) {
var newGameMoves = game.ugly_moves();
var bestMove = null;
//use any negative large number
var bestValue = -9999;
for (var i = 0; i < newGameMoves.length; i++) {
var newGameMove = newGameMoves[i];
game.ugly_move(newGameMove);
//take the negative as AI plays as black
var boardValue = -evaluateBoard(game.board())
game.undo();
if (boardValue > bestValue) {
bestValue = boardValue;
bestMove = newGameMove
}
}
return bestMove;
};
我们的算法现在可以在一块区域内实现评估。
Gif:测起来,动起来
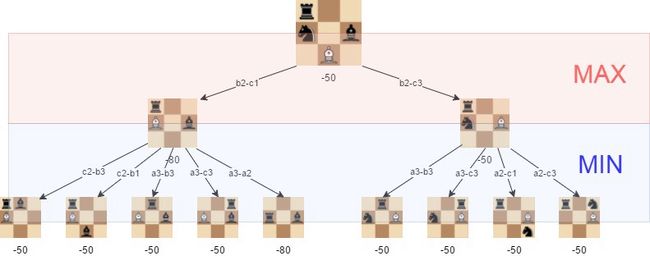
Step 3: 使用 Minimax 搜索树
接下来,我们要创建一个搜索树,算法可以从中选择最佳方法。这里用 Minimax 算法实现。
在该算法中,将所有可能移动的递归树探索到给定的深度,并且在树叶处评估位置。
之后,我们将最小值或最大值返回给父节点,这取决于它是移动白色还是黑色。(也就是说,我们尽可能地减少或最大限度地提高每一级的成果。)
白色的最佳举措是 b2-c3,因为我们可以保证我们能够达到评估为 -50 的位置
var minimax = function (depth, game, isMaximisingPlayer) {
if (depth === 0) {
return -evaluateBoard(game.board());
}
var newGameMoves = game.ugly_moves();
if (isMaximisingPlayer) {
var bestMove = -9999;
for (var i = 0; i < newGameMoves.length; i++) {
game.ugly_move(newGameMoves[i]);
bestMove = Math.max(bestMove, minimax(depth - 1, game, !isMaximisingPlayer));
game.undo();
}
return bestMove;
} else {
var bestMove = 9999;
for (var i = 0; i < newGameMoves.length; i++) {
game.ugly_move(newGameMoves[i]);
bestMove = Math.min(bestMove, minimax(depth - 1, game, !isMaximisingPlayer));
game.undo();
}
return bestMove;
}
};
利用最小值,我们的算法开始了解象棋的基本策略:
极小值算法的有效性很大程度上取决于我们可以实现的搜索深度,我们将在以下步骤中进行改进。
Step 4: Alpha-beta pruning
Alpha-beta pruning 是最小化算法的优化,允许我们忽略搜索树中的一些分支。这有助于我们在使用相同的资源的同时更深入地评估最小值搜索树。如果我们发现导致比之前动作更糟糕的情况时,这个算法能停止评估搜索树。它不会影响算法结果,反而能加速其进行。
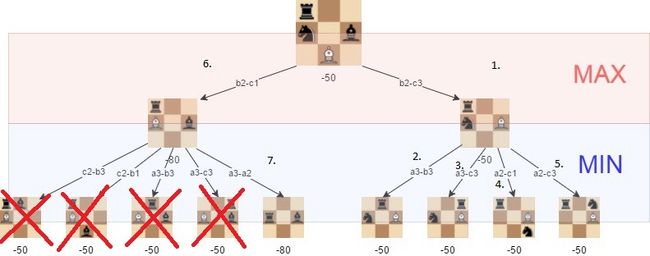
使用 alpha-beta,可以显着提升极小值算法,如下例所示:

按照 这个链接来尝试这个国际象棋 AI 的 alpha-beta 改进版。
Step 5: 改进评估功能
初始评估功能非常简陋。为了改善这一点,我们增加一些因素。比如,棋盘中心的骑士比边缘的骑士更好(因为它有更多的选择,因此更加活跃)。
在 chess-programming-wiki 中描述的改进表格:
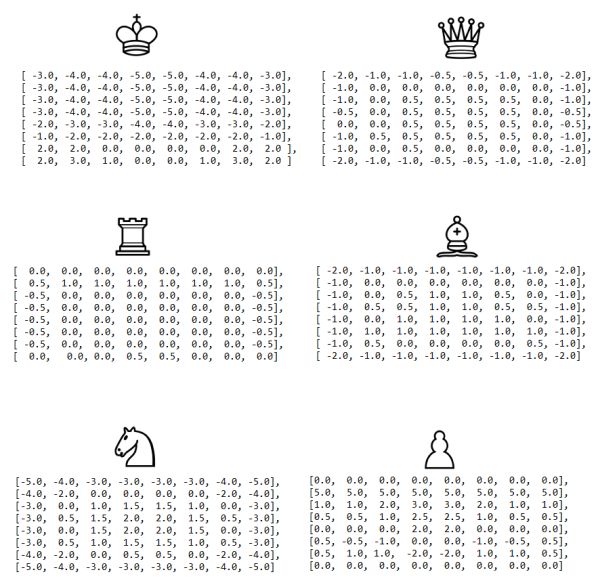
改进后我们能得到稍微聪明一点的象棋 AI,至少从业余玩家的眼中是这样的。
结论
即使是这样一个简单的象棋算法,它的优势也在于几乎不会产生显而易见的错误。但这同时也显示,它缺乏战略性思考。
本文阐述的方法已经足够编程基本象棋的棋艺算法,AI 的部分其实只有区区 200 行代码(不包括 move-generation),实现起来并不难。
戳 GitHub 链接看最终版本,更多信息可以查看 chess programming wiki。
原文地址:A step-by-step guide to building a simple chess AI
欢迎关注知乎专栏「极光日报」,每天为 Makers 导读三篇优质英文文章。
日报延伸阅读:
- 开发者提到最多的十个 GitHub 仓库