上期,我们学会了用python内置得find()方法和replace()来进行查找和替换的操作。不过这两种的方法局限性很大,它们在查找时都是只能匹配特定的字符。比如下面这个查找:
string.find('Hello'),只能匹配Hello,对于HELLO和hello,find()方法都是匹配不到的。本期,我们可以用正则表达式来解决这个问题。
正则表达式,它是一系列规则,主要用于高级查找和替换。
re模块
使用正则表达式必须使用python内置的模块re,然后定义一个匹配规则,然后根据这个规则在给定的字符串内匹配[1]。

下面这个例子简单地给出了re模块的用法:
>>> line = 'Hello, Jack! hello, Lucy! HELLO, Linda!'
# 引入re模块
>>> import re
# 定义匹配规则
>>> pattern = re.compile(r'hello')
# 查找
>>> pattern.findall(line)
['hello']
回到文章开头的问题,如果我们只想匹配到hello不区分大小写,需要定义匹配规则时使用re模块中的参数re.I:
>>> line = 'Hello, Jack! hello, Lucy! HELLO, Linda!'
# 引入re模块
>>> import re
# 定义匹配规则,设置参数 re.I
>>> pattern = re.compile(r'hello',re.I)
>>> pattern.findall(line)
['Hello', 'hello', 'HELLO']
re模块不仅可以查找,还可以通过sub()方法实现替换。re.sub()有5个函数,三个必选参数pattern,repl,string;两个可选参数count,flags。
它的标准形式是re.sub(pattern,repl,string,count,flags)。其中:pattern可以是一个字符串,也可以是一个匹配规则;repl指替换成的字符串;string指要被替换的字符串;count指匹配的次数[2]。比如,将hello(不区分大小写)全部替换成Hi。
>>> line = 'Hello, Jack! hello, Lucy! HELLO, Linda!'
>>> import re
>>> pattern = re.compile(r'hello',re.I)
>>> re.sub(pattern, 'Hi', line)
'Hi,jack. Hi,Nancy! Hi, Linda!'
上面的例子中,pattern代表了所有不区分大小写的hello,然后使用re.sub()方法将其全部替换成Hi,line是目标字符串。
元字符
| 元字符 | 说明 |
|---|---|
| . | 匹配除了换行符以外的任何字符 |
| \w | 匹配所有的字母、数字和下划线 |
| \s | 匹配所有的空白字符(空格\f\n\r\t\v) |
| \d | 匹配所有的数字([0~9]) |
| \b | 匹配单词的开始或者结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
如果我们想找出一个字符串中的所有数字,就可以用\d来匹配。
>>> line = '''I have 2 phones, the one is iphone7
··· and the other is huawei p10.'''
>>> pattern = re.compile('\d')
>>> pattern.findall(line)
['2', '7', '1', '0']
如果我们并不想让10被拆分成1和0,而是要求['2', '7', '10']这样的结果,这时就需要给出重复次数。
重复
重复的次数大致有以下几种:
| 符号 | 说明 |
|---|---|
| * | 任意次数,包括0次 |
| + | 任意次数,且至少1次 |
| ? | 重复0次或者1次 |
| {n} | 重复n次 |
| {n,} | 重复n次或者更多次 |
| {n,m} | 重复n次到m次(n<=m) |
既然可以指定重复次数,那么当我们不想10被拆分,就可以使用+来匹配,这时10就是一个数字整体。
>>> line = '''I have 2 phones, the one is iphone7
··· and the other is huawei p10.'''
>>> pattern = re.compile('\d+')
>>> pattern.findall(line)
['2', '7', '10']
字符类
元字符中的字符类都比较宽泛,比如\d代表0~9这10个数字,可是如果我们只想找出0~4之间的数字,可以使用字符类来完成。
>>> line = '''I have 2 phones, the one is iphone7
··· and the other is huawei p10.'''
>>> pattern = re.compile('[01234]+')
>>> pattern.findall(line)
['2', '10']
[01234]可以看作是一个枚举出所有元素的集合,只要目标字符串中的元素在这个集合中,都能够匹配到。
反义
有的时候,我们仅仅想排除少数几个字符,如果用字符类的话,需要写出大量的字符,效率必然不高。这时,用反义会更加方便[3]。
| 元字符 | 说明 |
|---|---|
| \W | 匹配所有除了字母、数字和下划线的其它字符 |
| \S | 匹配所有除了空白字符的其它字符 |
| \D | 匹配除了数字以外的所有字符 |
| \B | 匹配不是字符串开头或结束的位置 |
| [^ab] | 匹配除了字母a和b以外所有的字符 |
比如:想要排除字符串line中的所有数字,只需要使用\D+就能实现。
>>> line = '''I have 2 phones, the one is iphone7
··· and the other is huawei p10.'''
>>> pattern = re.compile('\D+')
>>> pattern.findall(line)
['I have ', ' phone, the one is iphone', ' and the other is huawei p', '.']
注意,如果这个时候使用\D,匹配到的将是一个个单字符,大家可以尝试一下。
分组
如果两种匹配规则都满足要求,我们是否由办法让它们共存呢?答案是可以的,使用分组,符号是|。比如:我们想匹配到所有的数字和空白字符,就可以用\d|\s来表示。
>>> line = '''I have 2 phones, the one is iphone7
··· and the other is huawei p10.'''
>>> pattern = re.compile('\d+|\s+')
>>> pattern.findall(line)
[' ', ' ', '2', ' ', ' ', ' ', ' ', ' ', '7', ' ', ' ', ' ', ' ', ' ', ' ', '10']
总结
- 使用re模块可以借助正则表达式实现高级的字符串的查找和替换操作
- 元字符将字符划分成几大类
- 可以限定重复次数,更好地进行匹配
- 字符类和反义给出了更精准的匹配方式
- 使用分组,实现多种匹配模式并存
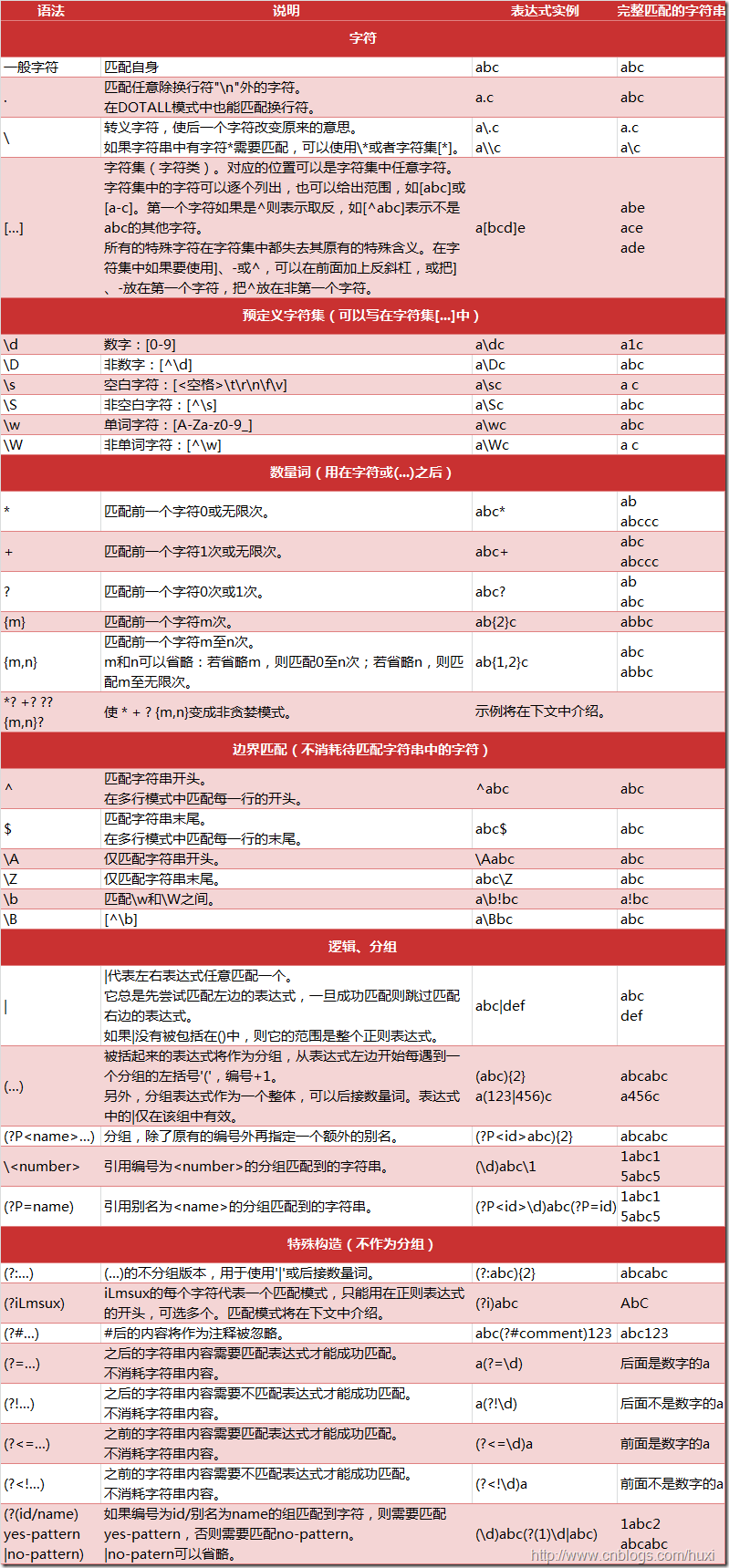
- 详细的正则表达式的匹配字符,请看下图:
思考
# 1.尝试写出能匹配到邮箱的正则表达式
# 提示:邮箱的格式是:用户名@域名.顶级域名
# 用户名是由字母数字下划线组成的
# 域名和顶级域名都是由字母和数字组成的
# 2.尝试写出能够匹配出ip地址的正则表达式
# 提示:ip地址由四个数字构成
# 数字之间用逗号隔开
# 每个数字的取值范围都是0~255
# 邮箱:\w+@[\w^_]+\.[\w^_]+
# ip地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
参考资料
- 《Python正则表达式指南》原文链接:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
- 《Python的替换函数——strip(),replace()和re.sub()》,原文链接:http://blog.csdn.net/zcmlimi/article/details/47709049
- 《正则表达式30分钟入门教程》原文链接:https://deerchao.net/tutorials/regex/regex.htm#mission
扫一扫这个二维码,关注公众号:聪哥python,获取最新python3基础教程
