GC分类
- Minor GC - 清理Young Generation
- Major GC - 清理Old Generation
- Full GC - 全部清理
其实这3个很难分开,有的Minor GC会触发Major GC,那算不算一次FGC呢?
jstat中FGC和FGCT是什么含义
jstat中的FGC的次数是stop the word的次数,比如cms的一次gc中有两次stop the word,那么一次gc过程jstat显示的FGC次数就会加2,FGCT是指的stop the word花费的时间。其实cms是一次Major GC的过程,但是jstat却显示了两次FGC,是不是坑呢?
参考Minor GC、Major GC和Full GC之间的区别
Minor GC
因为minor gc对程序的影响一般比较小,所以大家一般都比较少的关注minor gc,但是Minor GC还是会stop the world的。下面简单的探讨一下Minor GC。
大家比较少关注minor gc的一个原因是minor gc执行比较快。
为什么MinorGC比较快呢?
- Young Generation一般比较小
- Minor GC的时候不需要扫描Old Generation
- Young Generation中大部分都是没用的,GC中并不需要拷贝到Survivor或者Old Generation。
Minor GC的时候为什么不需要扫描Old Generation
Old Generation中有一个数据结构Card Table,这个数据结构记录了Old Generation中引用Young Generation的情况,所以Minor GC的时候只需要检查这里即可,不需要扫描整个Old Generation。
CMS GC
下面描述的算法只是对 Old Generation进行处理。
- Initial Mark (需要stop the world)
这个是标记Old Generation中被Young Generation引用的对象。这部分时间比较短。 - Concurrent Marking
递归的遍历Old Generation中被已经标记为live的对象引用的对象和root引用的对象。这一步是和业务线程并行的。 - Remark (需要stop the world)
寻找第二步中由于并行运行而漏掉的live的对象。 - Concurrent Sweep
清理没有被标记的对象。 - Resetting
一次GC完成,重置数据结构
516357.260: [GC [1 CMS-initial-mark: 4406638K(6291456K)] 4421249K(10136256K), 0.0226190 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
516357.283: [CMS-concurrent-mark-start]
516357.407: [CMS-concurrent-mark: 0.124/0.124 secs] [Times: user=1.72 sys=0.31, real=0.12 secs]
516357.407: [CMS-concurrent-preclean-start]
516357.455: [CMS-concurrent-preclean: 0.047/0.048 secs] [Times: user=0.27 sys=0.08, real=0.05 secs]
516357.456: [CMS-concurrent-abortable-preclean-start]
516360.647: [CMS-concurrent-abortable-preclean: 3.174/3.191 secs] [Times: user=14.11 sys=3.22, real=3.19 secs]
516360.653: [GC[YG occupancy: 1770775 K (3844800 K)]516360.653: [Rescan (parallel) , 0.2765090 secs]516360.930: [weak refs processing, 0.2960360 secs] [1 CMS-remark: 4406638K(6291456K)] 6177413K(10136256K), 0.5742240 secs] [Times: user=13.81 sys=0.00, real=0.58 secs]
516361.228: [CMS-concurrent-sweep-start]
516365.291: [CMS-concurrent-sweep: 4.036/4.064 secs] [Times: user=21.48 sys=5.05, real=4.06 secs]
516365.292: [CMS-concurrent-reset-start]
516365.317: [CMS-concurrent-reset: 0.025/0.025 secs] [Times: user=0.11 sys=0.03, real=0.03 secs]
从这个过程中能看出,CMS并没有compaction,就是把live的对象集中到一起,那么就有可能造成内存碎片,所以在使用cms回收器的时候,一般会带上useCMSCompactAtFullCollection,就是在FGC的时候进行compaction。
ParNewGC
我们使用cms gc算法的时候,新生代的gc算法就是并行gc算法。
- MaxTenuringThreshold=6
MaxTenuringThreshold这个参数用于控制对象能经历多少次Minor GC才晋升到老生代,但是并不是对象必须经历MaxTenuringThreshold才会晋升到老生代,jvm会动态计算可以参考这个 - SurvivorRatio
survivor区占新生代的比例
[Times: user=0.21 sys=0.00, real=0.02 secs]
608904.697: [GC 608904.699: [ParNew
Desired survivor size 178946048 bytes, new threshold 6 (max 6)
- age 1: 2477432 bytes, 2477432 total
- age 2: 155536 bytes, 2632968 total
- age 3: 4688 bytes, 2637656 total
- age 4: 5904 bytes, 2643560 total
- age 5: 5312 bytes, 2648872 total
- age 6: 10656 bytes, 2659528 total
: 3498496K->3772K(3844800K), 0.0151990 secs] 6053989K->2559272K(10136256K), 0.0172310 secs]
G1 (Garbage First) GC

- 每个region大小相同
- 每个region分别属于 eden survior和 old之一
Region的大小
一个Region的大小可以通过参数-XX:G1HeapRegionSize设定,取值范围从1M到32M,且是2的指数。如果不设定,那么G1会根据Heap大小自动决定。如果是jvm自动计算,会以分为2048左右个Region为目标,计算Region的大小。
GC过程
G1提供了两种GC模式,Young GC和Mixed GC,两种都是会Stop The World的。
- Young GC:选定所有年轻代里的Region。通过控制年轻代的region个数,即年轻代内存大小,来控制young GC的时间开销。
- Mixed GC:选定所有年轻代里的Region,外加根据global concurrent marking统计得出收集收益高的若干老年代Region。在用户指定的开销目标范围内尽可能选择收益高的老年代Region。
由上面的描述可知,Mixed GC不是full GC,它只能回收部分老年代的Region,如果mixed GC实在无法跟上程序分配内存的速度,导致老年代填满无法继续进行Mixed GC,就会使用serial old GC(full GC)来收集整个GC heap。所以我们可以知道,G1是不提供full GC的。
GC特点
- 因为内存块不是连续的,而是由一些小内存块组成的,所以可以比较容易的调整eden和survivor区的大小
- 使用remember set来减少gc时扫描的region的数目
- 使用SATB算法,保证gc的时候的正确性
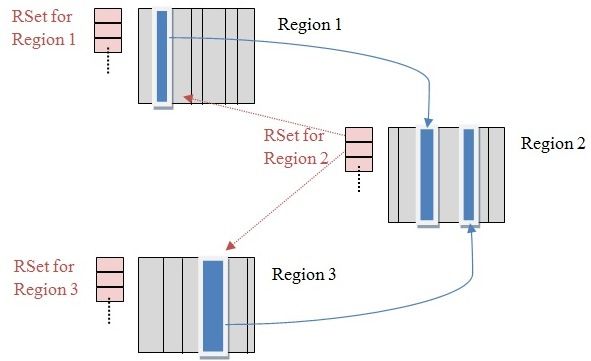
RSet(Remember Set)
RSet存储的是有引用我这个region的card table的index(card是一个更小的单元,一般是512B,所以一个region一般有多个card),有了这个数据结构,如下图(出处)所示,那么如果要回收Region2的对象的话,只需要查看Region2的RSet中的card是否还有指向这个region的对象即可,不需要扫描全部的region,这样能大大的节省时间。
concurrent的GC算法
先介绍一下背景知识,根据三色标记算法,我们知道在gc过程中对象存在三种状态:
白:对象没有被标记到,标记阶段结束后,会被当做垃圾回收掉。
灰:对象被标记了,但是它的field还没有被标记或标记完。
黑:对象被标记了,且它的所有field也被标记完了。
试想一下如果一个有引用的对象在标记算法的时候,没有被标记上,那么就会在gc算法运行结束的时候被清除掉,这对一个gc算法来说是个灾难。这种情况发生有两个充分必要条件:
- Mutator赋予一个黑对象该白对象的引用。
- Mutator删除了所有从灰对象到该白对象的直接或者间接引用。
incremental update
破坏了第一个条件,如果发生第一个情况,那么这个黑对象要么被改成灰色,要么把白色改成灰色。因为这个建立的调用关系图在gc的过程中是会增量更新的,所以叫incremental update。
snapshot-at-the-begining
SATB算法破坏了第二个条件,就是在gc过程中,如果一个待回收region中的白对象的引用被替换或者删除了,那么就会保留这个引用,这样在标记完成后,这个白对象肯定不会被清楚。当然这样做也有一定的副作用,有可能这个保留的白对象是个真正的Garbage,那么就被放过了。为啥叫这个名字呢?因为他建立的调用关系图是gc开始的时候的snapshot,后来没有update。
G1 为什么比CMS能更好的预测GC的停顿时间呢?
CMS要进行一次GC,那么就需要扫描Old Generation内存中所有的object,但是G1就不需要,他可以选择一个Region进行GC,所以能较好的控制停顿时间。
参考文献
- 美团关于G1的分享
- Getting Started with the G1 Garbage Collector