1. Tensorflow 实现原理
实现原理
TensorFlow有一个重要组件client,顾名思义,就是客户端,它通过Session的接口与master及多个worker相连。其中每一个worker可以与多个硬件设备(device)相连,比如CPU或GPU,并负责管理这些硬件。而master则负责指导所有worker按流程执行计算图。TensorFlow有单机模式和分布式模式两种实现,其中单机指client、master、worker全部在一台机器上的同一个进程中;分布式的版本允许client、master、worker在不同机器的不同进程中,同时由集群调度系统统一管理各项任务。
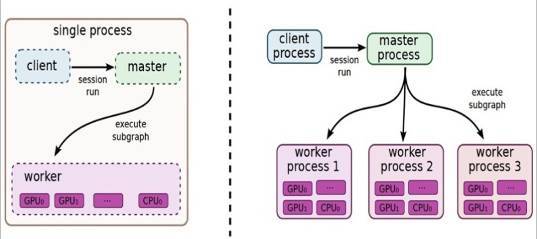
图1.1 TensorFlow单机版本和分布式版本的示例图
TensorFlow计算图的运行机制
Client
Client基于TensorFlow的编程接口,构造计算图。此时,TensorFlow并未执行任何计算。直至建立Session会话,并以Session为桥梁,建立Client与后端运行时的通道,将Protobuf格式的GraphDef发送至Distributed Master。也就是说,当Client对OP结果进行求值时,将触发Distributed Master的计算图的执行过程。如下图所示,Client构建了一个简单计算图。它首先将w与x进行矩阵相乘,再与截距b按位相加,最后更新至s。
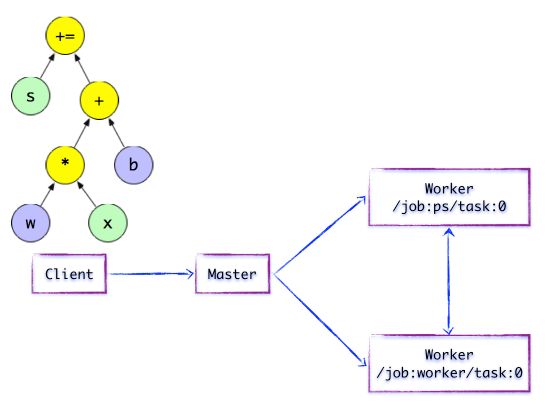
图1.2 简单的TensorFlow计算图
Distributed Master
在分布式的运行时环境中,Distributed Master根据Session.run的Fetching参数,从计算图中反向遍历,找到所依赖的最小子图。然后Distributed Master负责将该子图再次分裂为多个「子图片段」,以便在不同的进程和设备上运行这些「子图片段」。最后,Distributed Master将这些图片段派发给Work Service。随后Work Service启动「本地子图」的执行过程。Distributed Master将会缓存「子图片段」,以便后续执行过程重复使用这些「子图片段」,避免重复计算。
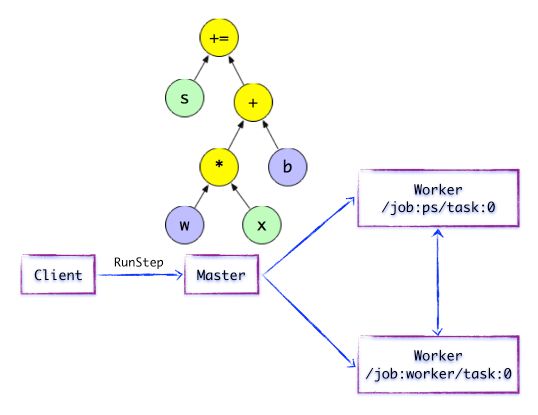
图1.3 简单的TensorFlow计算图---开始执行
执行图计算
如上图所示,Distributed Master开始执行计算子图。在执行之前,Distributed Master会实施一系列优化技术,例如「公共表达式消除」,「常量折叠」等。随后,Distributed Master负责任务集的协同,执行优化后的计算子图。
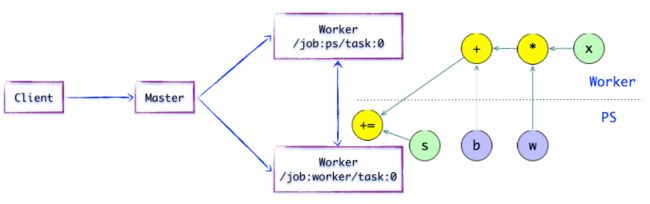
图1.4 简单的TensorFlow计算图---子图片段
子图片段
如上图所示,存在一种合理的「子图片段」划分算法。Distributed Master将模型参数相关的OP进行分组,并放置在PS任务上。其他OP则划分为另外一组,放置在Worker任务上执行。
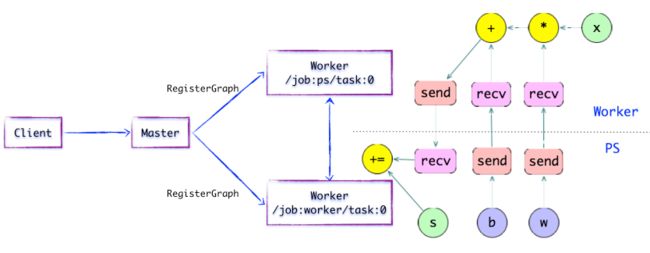
图1.5 简单的TensorFlow计算图---插入SEND/RECV节点
如上图所示,如果计算图的边被任务节点分割,Distributed Master将负责将该边进行分裂,在两个分布式任务之间插入SEND和RECV节点,实现数据的传递。
随后,Distributed Master将「子图片段」派发给相应的任务中执行,在Worker Service成为「本地子图」,它负责执行该子图的上的OP。
Worker Service
对于每个任务,都将存在相应的Worker Service,它主要负责如下3个方面的职责:
- 处理来自Master的请求;
- 调度OP的Kernel实现,执行本地子图;
- 协同任务之间的数据通信。
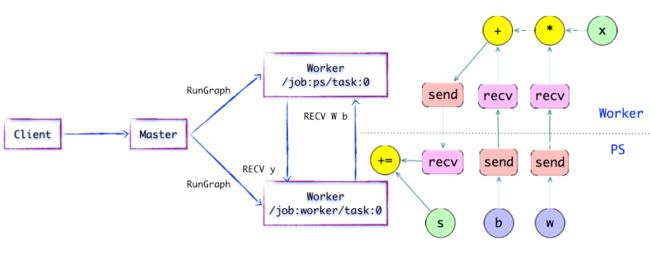
图1.6 简单的TensorFlow计算图---执行本地子图
执行本地子图
Worker Service派发OP到本地设备,执行Kernel的特定。它将尽最大可能地利用多CPU/GPU的处理能力,并发地执行Kernel实现。
另外,TensorFlow根据设备类型,对于设备间的SEND/RECV节点进行特化实现:
- 使用cudaMemcpyAsync的API实现本地CPU与GPU设备的数据传输;
- 对于本地的GPU之间则使用端到端的DMA,避免了跨host CPU昂贵的拷贝过程。
对于任务之间的数据传递,TensorFlow支持多协议,主要包括:
- gRPC over TCP
- RDMA over Converged Ethernet
示例代码
import tensorflow as tf
# 定义常量
hello = tf.constant('Hello World!')
sess = tf.Session()
"""
target: (Optional.) The execution engine to connect to.
Defaults to using an in-process engine. See
@{$distributed$Distributed TensorFlow}
"""
sess.run(hello)
# Terminal out put info:
$ b'Hello World!'
以上简短的代码其实就已经运用到了Tensorflow分布式结构,只不过该分布式的client、master、worker都是在本地的同一台机器而已。而多台机器实现分布式只需要指定相应的client、master、worker分布在不同的机器上就可以实现了,下面将详细介绍如何在多台机器上实现Tensorflow分布式。
3. Tensorflow 分布式之 In-graph replication (图内拷贝)
gRPC
上面提到了Tensorflow的单机模式是将client、master、worker都放在同一台机器上,而分布式模式就是将三者分布到多台机器上。这时就需要考虑多台机器之前的通信问题了,在Tensorflow的分布式中常使用的通信协议是gRPC协议,gRPC是Google开发的一个开源的RPC(Remote procedure call)协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。
In-graph replication
Tensorflow训练模型通常需要一些训练参数,训练参数的分发有两种方式:In-graph replication、Between-graph replication。其中In-graph replication方式的数据分发是在一个节点上,这样的好处是配置简单, 其他多机多GPU的计算节点,只要起个join操作, 暴露一个网络接口,等在那里接受任务就好了。 但是这样的坏处是训练数据的分发在一个节点上,要把训练数据分发到不同的机器上, 严重影响并发训练速度。在大数据训练的情况下, 不推荐使用这种模式。
示例代码1 自动节点分配策略----简单的贪婪策略代价模型估计
worker_01
import tensorflow as tf
# 设置worker 地址与端口
worker_01 = "172.17.0.2:2222"
worker_02 = "172.17.0.3:2222"
worker_hosts = [worker_01, worker_02]
# Creates a `ClusterSpec`
cluster_spec = tf.train.ClusterSpec({"worker": worker_hosts})
# Creates a new server with ClusterSpec、job_name、task_index
server = tf.train.Server(cluster_spec, job_name="worker", task_index=1)
server.join()
# Terminal Output
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:200] Initialize GrpcChannelCache for job worker -> {0 -> localhost:2222, 1 -> 172.17.0.3:2222}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:221] Started server with target: grpc://localhost:2222
worker_02
import tensorflow as tf
# 设置worker 地址与端口
worker_01 = "172.17.0.2:2222"
worker_02 = "172.17.0.3:2222"
worker_hosts = [worker_01, worker_02]
# Creates a `ClusterSpec`
cluster_spec = tf.train.ClusterSpec({"worker": worker_hosts})
# Creates a new server with ClusterSpec、job_name、task_index
server = tf.train.Server(cluster_spec, job_name="worker", task_index=0)
server.join()
# Terminal Output
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:200] Initialize GrpcChannelCache for job worker -> {0 -> 172.17.0.2:2222, 1 -> localhost:2222}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:221] Started server with target: grpc://localhost:2222
client
import tensorflow as tf
import numpy as np
# placeholder
X = tf.placeholder("float")
Y = tf.placeholder("float")
# Creates weight
w = tf.Variable(0.0, name="weight")
# Creates biases
b = tf.Variable(0.0, name="reminder")
# init Variable
init_var = tf.global_variables_initializer()
# loss function
loss = tf.square(Y - tf.multiply(X, w) - b)
# Optimizer
op = tf.train.GradientDescentOptimizer(0.01).minimize(cost_op)
# input parameter
train_X = np.linspace(-1, 1, 101)
train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.33 + 10
with tf.Session("grpc://172.17.0.2:2222") as sess:
sess.run(init_op)
for i in range(10):
for (x, y) in zip(train_X, train_Y):
sess.run(train_op, feed_dict={X: x, Y: y})
print(sess.run(w))
print(sess.run(b))
从上面的示例代码中我们可以看出:这里使用了三台机器在训练,一个clint,两个worker。这里可能会有一些问题:
问题1. master在哪里?
问题2. 每一个节点的任务怎么分配?
对于问题1,在In-graph replication方式中master其实就是with tf.Session("grpc://172.17.0.2:2222") as sess: 这句话中指定的target,也就是说172.17.0.2:2222这台机器就是master,在运行的时候会在这台机器上打印如下日志:
I tensorflow/core/distributed_runtime/master_session.cc:1012] Start master session 254ffd62801d1bee with config:
对于问题2,
把计算已经从单机多GPU,已经扩展到了多机多GPU了, 不过数据分发还是在一个节点。 这些计算节点暴露出来的网络接口,使用起来就跟本机的一个GPU的使用一样, 只要在操作的时候指定tf.device("/job:worker/task:n"), 就可以向指定GPU一样,把操作指定到一个计算节点上计算,使用起来和多GPU的类似。
示例代码2 用户限制的节点分配策略
3. Tensorflow 分布式之 Between-graph replication (图间拷贝)
between-graph模式下,训练的参数保存在参数服务器, 数据不用分发, 数据分片的保存在各个计算节点, 各个计算节点自己算自己的, 算完了之后, 把要更新的参数告诉参数服务器,参数服务器更新参数。这种模式的优点是不用训练数据的分发了, 尤其是在数据量在TB级的时候, 节省了大量的时间,所以大数据深度学习还是推荐使用between-graph模式。
Reference
[1]:TensorFlow架构与设计:概述 http://www.jianshu.com/p/a5574ebcdeab