简评:苹果官方手写识别团队的技术文章,讲解了如何用机器学习的方法实现中文的手写识别。
以下「 我们」都代表「 苹果手写识别团队」。
因为手机,平板电脑和可穿戴设备如智能手表的流行,手写识别比以往任何时候都更重要。在移动设备上支持中文手写识别所需的大型字符库,成了嵌入式设备独特的挑战。
本文介绍了我们如何应对这些挑战,以实现 iPhone,iPad 和 Apple Watch(Scribble 模式)上的实时性能。我们的识别系统,基于深度学习,可以准确处理最多 30000 个字符的集合。为了达到可接受的准确度,我们特别注意数据的不同收集条件,写作风格的差异和对应的机器训练方案。我们发现,在合适的条件下,更多的汉字识别是可以实现的。我们的实验表明,只要我们使用足够的质量和足够数量的训练数据,字符库的增加以及准确性的保证都是可以做到的。
介绍
手写识别可以增强移动设备的用户体验,特别是对于中文输入。中文手写识别是独一无二的挑战,因为其底层字符库量级大。英文字母的手写通常涉及 100 个符号以下,但中国汉字国家标准 GB18030 - 2005 中的一组 Hànzì 字符就包含 27533 个条目,并且大多数中文还使用了不同字体。
为了让识别更容易实现,通常将重点放在有限数量的字符中,这些字符是日常使用率较高的常用字符。因此,标准 GB2312-80 集仅包括 6763 个条目(分别为 1 级常用字符 3755 个,2 级常用字符 3008 个)。中国科学院自动化研究所建立的流行常用 CASIA 字符集共包含大约 7356 个条目。SCUT-COUCH 数据库具有类似的常用字符数[8]。
上述这些集合倾向于反映普遍中文输入的常用字符。然而,放在个别用户身上,「常用」通常因人而异。大多数人至少要用到几个「不常用」的字符,例如与他们相关的专有名称。因此,中文手写识别算法的理想状态至少要达到 GB18030-2005 的水平(27533 个)。
经过选型,最终 CNN 成为了我们团队的的选择方案。但是,这种方法需要将 CNN 扩展到约 30000 个字符,同时还要保持嵌入式设备的实时性能。本文重点介绍了我们面对汉字识别准确性,角色覆盖率和写作风格方面所遇到的挑战。
系统配置
我们采取类似 CNN 的系统配置,整个系统配置如图 1 所示。
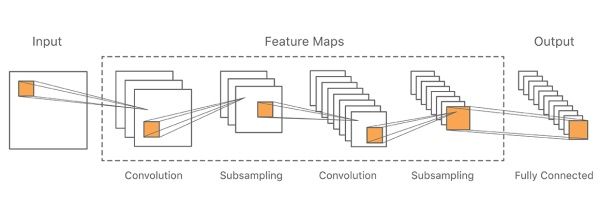
输入端数据是手写的中文字符,48 X 48 像素分辨率(出于性能考虑)。输入数据传递至多个层级完成交替卷积和采样,经过最后一个特征层后然后输出。
从一个卷积层到下一个卷积层,我们筛选了内核的大小和特征图的数量,以便导出越来越粗糙的粒度的特征。我们通过使用 2×2 内核的最大池层[9]进行二次采样。最后一个特征层通常包含大约 1000 个小特征图。输出层每个类都有一个节点,例如 GB2312-80 的Hànzìlevel-1 有 3755 个节点,而扩展到全部库接近 30000 节点。
作为基准,我们评估了以前描述的 CASN 基准任务的 CNN 实现模型[6]。虽然这个任务只涵盖Hànzì 常用一级字符,但在文献中有许多关于字符精度的参考结果可以直接使用(例如[7]和[14])。我们使用基于 CASIA-OLHWDB,DB1.0-1.2,作为训练和测试数据集[6],[7],产生大约一百万个训练样本。
要注意一点,考虑到我们的产品重点,目的是不要对 CASIA 的最高准确度进行调整。相反,我们的优先事项是模型大小,评估速度和用户体验。因此,我们选择了一种紧凑的系统,可以实现横跨多种字体风格,并兼顾非标准笔划顺序。
表 1 显示了使用图 1 的 CNN 的结果,其中缩写「Hz-1」是指 Hànzì 一级常用库(3755个字符),CR(n)表示第 n 层字符识别精度。

表 1 中的系统仅针对 CASIA 数据进行训练,不包括任何其他培训数据。我们也有兴趣提取 iOS 设备上内部收集的其他培训数据。这些数据涵盖了更多种类的风格(参见下一节),并且包含每个字符更多样的的训练实例。表 2 是我们的增强训练的结果,也是测试上面的 3755 个字符。

尽管产生了更大的占用空间(15MB),但精度提高了(第 4 层提高了2%)。
这表明:测试结果已经能够覆盖到绝大多数手写的字体;附加字体样式对底层无影响。
扩展到 30 K 个字符
常用字符只是理想状态,不同用户常用的字符并不相同,所以大量用户都需要远大于 3755 个 字符的库,然而选择哪个库并不是很容易。从 GB2312-80 定义的简体中文到繁体中文定义的 Big5,Big5E 和 CNS 11643-92,这个跨度太大了。最近又出现了新的 HKSCS-2008,额外又增加了 4568 个字符,甚至更符合 GB18030 - 2000 的标准。
我们希望能够让用户便捷的使用简体中文、繁体中文、常用的姓名,诗歌和常见的标记,视觉符号和表情符号来完成日常通信。我们还希望能够支持拉丁文脚本来用于偶尔的产品或商品名称。最终,我们遵循 Unicode 作为现行的国际字符编码标准,因为它几乎涵盖了所有上述标准。
因此,我们的字符识别系统集中在 GB18030-2005,HKSCS-2008,Big5E,核心 ASCII 的集合,以及一系列视觉符号和表情符号,总共约 30000 个字符,我们觉得这些已经能够满足几乎所有汉字输入的要求了。
选择底层字符库存后,对用户实际使用的写作风格进行抽样至关重要。虽然有很多识别关键元素(参见[13]),但实际情况依然有很多误差,例如,(i)使用 U+2EBF 草字头(艹)很难识别,因为有的用户把草字头写成两个「十」,或着(ii)草书 U+56DB「四」这个字和对 U+306E「の」经常混淆。
渲染的字体也可能导致混淆,因为某些用户期望特定字符以特定样式呈现。书写速度快但字形不一边忍的草书,往往会增加歧义,例如 U +38B(王)与 U+4E94(五)之间。最后,国际化有时会引发意想不到的冲突:例如,U+4E8C(二)当被草写时,可能与拉丁字符「2」和「Z」混淆。
对此,我们的逻辑是为用户提供全部的无约束的书写体备选,从印刷体到草书[5]。为了尽可能覆盖多的字体,我们向中国的手写者寻求数据,我们惊讶的发现世界上竟然有如此多的不同的中文字体。我们收集了不同年龄、性别、教育背景的参与数据。所得到的手写数据在许多方面都是独一无二。值得一提的是,iOS 设备有个非常大的优点,采样清晰。
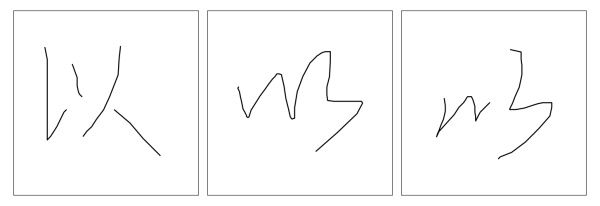
比如用 U+82B1「花」这个字来举例,就有好多种不同的写作风格:



事实上,在日常生活中,用户总是写的又快又乱,导致字体千变万化。同一个字可能认成两个字,同样的,不同的字可能识别成同一个字。


根据前面讨论的指导原则,我们收集数千万个字符的实例用于我们的训练数据。将上一节中的 3755 个字符系统与表 3 作比较后,在同一测试集上,我们将可识别字符数从 3755 增加到约 30000 个。

注意,表 3 的模型大小和表 2 相同,因为它们同样是使用了 Hz-1 的库,但是精确度有所下降,这是我们预期到的,因为要考虑到覆盖范围的大大增加,以及不同类型字体的混淆,比如「二」和「Z」。
比较表 2 和表 3,我们可以发现,覆盖率提高了 10 倍,但是储存空间没有变,精确度也只下降了一点。实际上,随着模型大小的增加,错误的数量增加的并不多。因此构建一个覆盖 3 万字符的高精度的汉字识别系统是可行和实用的。
为了了解系统在整个 30000 字符中的运行情况,我们进行了不同的测试,这些测试包含了各种情况,最后得出一个平均的结果。

当然,表 3 和表 4 是不能直接比较的,因为他们是在不同测试集上获取的。尽管如此,它们都展现了在前 4 层的识别精度上,都处于同一个较高的水准。
讨论
由于存在各种来源的新增内容,Unicode 中的 CJK 字符总数(目前约为75,000 [12])可能会增加。诚然,这些增加的字符可能都很罕见(例如,用于历史名称或诗歌)。不过,对于特定的人来说都是有价值的。
那么未来我们如何处理更大的字符库呢?根据本文探讨的实验学习曲线[2],我们可以以此推断,未来不同的类型的字体,不同的数据量产生的结果。
举个例子,表 3 比表 1 的数据量大十倍,而精准度下降少于 2%,由此我们可以推断出 100000 个字符的量级和相应增加的训练数据,使用相同的架构,第一层精度会在 84% 左右,而第十层的精度会在 97%,这是可以预期到的。
综上所述,在嵌入式设备上构建一个覆盖 30000 个字符的汉字手写识别系统是切实可行的。此外,在训练数据够多,数据质量高的情况下,随着字符库存的增加,精准度会有所细微的下降。这些结论对于未来构建更大的字符库是有很大意义的。
参考
[1] D.C. Ciresan, U. Meier, L.M. Gambardella, and J. Schmidhuber, Convolutional Neural Network Committees For Handwritten Character Classification, in 11th Int. Conf. Document Analysis Recognition (ICDAR 2011), Beijing, China, Sept. 2011.
[2] C. Cortes, L.D. Jackel, S.A. Jolla, V. Vapnik, and J.S. Denker, Learning Curves: Asymptotic Values and Rate of Convergence, in Advances in Neural Information Processing Systems (NIPS 1993), Denver, pp. 327–334, Dec. 1993.
[3] G.E. Hinton and K.J. Lang, Shape Recognition and Illusory Conjunctions, in Proc. 9th Int. Joint Conf. Artificial Intelligence, Los Angeles, CA, pp. 252–259, 1985.
[4] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, Gradient– based Learning Applied to Document Recognition, Proc. IEEE, Vol. 86, No. 11, pp. 2278–2324, Nov. 1998.
[5] C.-L. Liu, S. Jaeger, and M. Nakagawa, Online Recognition of Chinese Characters: The State-of-the-Art, IEEE Trans. Pattern Analysis Machine Intelligence, Vol. 26, No. 2, pp. 198–213, Feb. 2004.
[6] C.-L. Liu, F. Yin, D.-H. Wang, and Q.-F. Wang, CASIA Online and Offline Chinese Handwriting Databases, in Proc. 11th Int. Conf. Document Analysis Recognition (ICDAR 2011), Beijing, China, Sept. 2011.
[7] C.-L. Liu, F. Yin, Q.-F. Wang, and D.-H.Wang, ICDAR 2011 Chinese Handwriting Recognition Competition,in 11th Int. Conf. Document Analysis Recognition (ICDAR 2011), Beijing, China, Sept. 2011.
[8] Y. Li, L. Jin , X. Zhu, T. Long, SCUT-COUCH2008: A Comprehensive Online Unconstrained Chinese Handwriting Dataset (ICFHR 2008), Montreal, pp. 165–170, Aug. 2008.
[9] K. Jarrett, K. Kavukcuoglu, M. Ranzato, and Y. LeCun, What is the Best Multi-stage Architecture for Object Recognition?, in Proc. IEEE Int. Conf. Computer Vision (ICCV09), Kyoto, Japan, Sept. 2009.
[10] U. Meier, D.C. Ciresan, L.M. Gambardella, and J. Schmidhuber, Better Digit Recognition with a Committee of Simple Neural Nets, in 11th Int. Conf. Document Analysis Recognition (ICDAR 2011), Beijing, China, Sept. 2011.
[11] P.Y. Simard, D. Steinkraus, and J.C. Platt, Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis, in 7th Int. Conf. Document Analysis Recognition (ICDAR 2003), Edinburgh, Scotland, Aug. 2003.
[12] Unicode, Chinese and Japanese,http://www.unicode.org/faq/han_cjk.html, 2015.
[13] F.F. Wang, Chinese Cursive Script: An Introduction to Handwriting in Chinese, Far Eastern Publications Series, New Haven, CT: Yale University Press, 1958.
[14] F. Yin, Q.-F. Wang, X.-Y. Xhang, and C.-L. Liu, ICDAR2013 Chinese Handwriting Recognition Competition, in 11th Int. Conf. Document Analysis Recognition (ICDAR 2013), Washington DC, USA, Sept. 2013.
英文原文:Real-Time Recognition of Handwritten Chinese Characters Spanning a Large Inventory of 30,000 Characters - Apple
“本译文仅供个人研习之用,谢绝任何转载及用于任何商业用途。本译文所涉法律后果均由本人承担。本人同意平台在接获有关著作权人的通知后,删除文章。”
推荐阅读:
AI 何时会全面超越人类
什么!这款 App 居然用摄像头充当按钮!