1. 概述
A Red-Black tree based NavigableMap implementation. The map is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time, depending on which constructor is used.
This implementation provides guaranteed log(n) time cost for the containsKey, get, put and remove operations. Algorithms are adaptations of those in Cormen, Leiserson, and Rivest’s Introduction to Algorithms.
之前已经学习过HashMap和LinkedHashMap了,HashMap不保证数据有序,LinkedHashMap保证数据可以保持插入顺序,而如果我们希望Map可以保持key的大小顺序的时候,我们就需要利用TreeMap了。
TreeMap tmap = new TreeMap();
tmap.put(1, "语文");
tmap.put(3, "英语");
tmap.put(2, "数学");
tmap.put(4, "政治");
tmap.put(5, "历史");
tmap.put(6, "地理");
tmap.put(7, "生物");
tmap.put(8, "化学");
for(Entry entry : tmap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
其大致的结构如下所示:
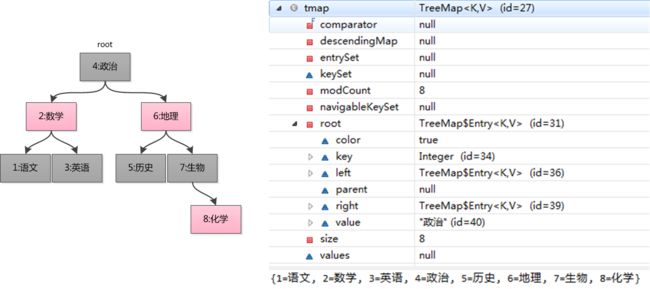
使用红黑树的好处是能够使得树具有不错的平衡性,这样操作的速度就可以达到log(n)的水平了。具体红黑树的实现不在这里赘述,可以参考 数据结构之红黑树、 wikipedia-红黑树等的实现。
2. put函数
Associates the specified value with the specified key in this map.If the map previously contained a mapping for the key, the old value is replaced.
如果存在的话,old value被替换;如果不存在的话,则新添一个节点,然后对做红黑树的平衡操作。
public V put(K key, V value) {
Entry t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry parent;
// split comparator and comparable paths
Comparator cpr = comparator;
// 如果该节点存在,则替换值直接返回
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 如果该节点未存在,则新建
Entry e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 红黑树平衡调整
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
3. get函数
get函数则相对来说比较简单,以log(n)的复杂度进行get
final Entry getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
Entry p = root;
// 按照二叉树搜索的方式进行搜索,搜到返回
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
public V get(Object key) {
Entry p = getEntry(key);
return (p==null ? null : p.value);
}
4. successor后继
TreeMap是如何保证其迭代输出是有序的呢?其实从宏观上来讲,就相当于树的中序遍历(LDR)。我们先看一下迭代输出的步骤
for(Entry entry : tmap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
根据The enhanced for statement,for语句会做如下转换为:
for(Iterator> it = tmap.entrySet().iterator() ; tmap.hasNext(); ) {
Entry entry = it.next();
System.out.println(entry.getKey() + ": " + entry.getValue());
}
在it.next()的调用中会使用nextEntry调用successor这个是过的后继的重点,具体实现如下:
static TreeMap.Entry successor(Entry t) {
if (t == null)
return null;
else if (t.right != null) {
// 有右子树的节点,后继节点就是右子树的“最左节点”
// 因为“最左子树”是右子树的最小节点
Entry p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
// 如果右子树为空,则寻找当前节点所在左子树的第一个祖先节点
// 因为左子树找完了,根据LDR该D了
Entry p = t.parent;
Entry ch = t;
// 保证左子树
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
怎么理解这个successor呢?只要记住,这个是中序遍历就好了,L-D-R。具体细节如下:
a. 空节点,没有后继
b. 有右子树的节点,后继就是右子树的“最左节点”
c. 无右子树的节点,后继就是该节点所在左子树的第一个祖先节点
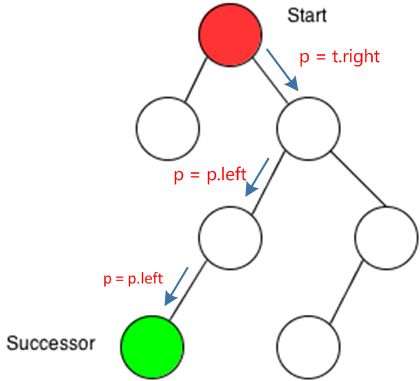
a.好理解,不过b, c,有点像绕口令啊,没关系,上图举个例子就懂了!
有右子树的节点,节点的下一个节点,肯定在右子树中,而右子树中“最左”的那个节点则是右子树中最小的一个,那么当然是右子树的“最左节点”,就好像下图所示:
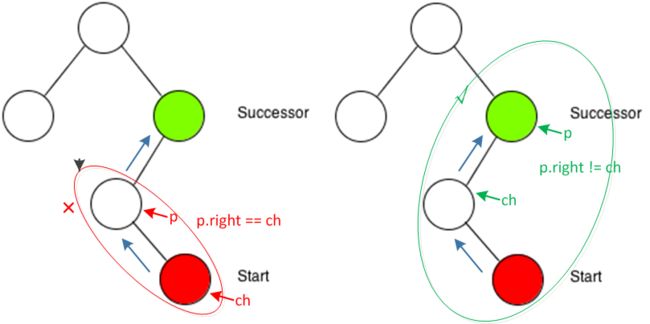
无右子树的节点,先找到这个节点所在的左子树(右图),那么这个节点所在的左子树的父节点(绿色节点),就是下一个节点。
参考资料
TreeMap (Java Platform SE 8)
浅谈算法和数据结构: 九 平衡查找树之红黑树
Java提高篇(二七)——-TreeMap
数据结构之红黑树
wikipedia-红黑树
Red-Black Trees
How TreeMap searches successor for given Entry?