参考cppreference
参考The C++ Memory Model and Modern Hardware
- CPU架构——在不同的CPU core上因cache不一致性导致的读取/写入不同步;
编译器优化——编译器可能会把指令重新排序,导致即使上了同步原语,仍导致读取/写入乱序。
一个是不同步,也就是期待的是同步,是一个执行期的随机事件;
一个是乱序,也就是打乱顺序后的“固定顺序”是一个确定事件。
0.为什么C++要在语言层面引入对多线程的支持?
0.1 简介
基于多线程库如POSIT、boost.Thread不是工作的很好?
具体解释详见Threads Cannot be Implemented as a Library
因为C++03标准是单线程的,所以即便是完全符合标准的编译器也可能各个脑袋里面只装着一个线程,于是在对代码作优化的时候总是一不小心就可能做出危害多线程正确性的优化来。具体来说是因为两方面原因:1)编译器优化会产生多线程错误的代码;2)完全基于库的多线程代码会影响性能
编译器和硬件对程序内存做的优化:
1)编译器可能对内存操作进行重新排序,前提是不违反线程内部依赖。
2)在相同的限制条件下,硬件也可能对内存操作重排序。将store放在load的后面
关于硬件的内容,推荐阅读《Memory Barriers: a Hardware View for Software Hackers》。c/c++实现对Pthreads支持如下
1)pthread_mutex_lock()禁止硬件在调用附近对内存操作进行重排序。
2)编译器:内存操作不允许跨过锁函数的调用。(这种支持是不够的)
0.2 正确性问题
- 正确性问题1)并发修改
编译器并不知道有线程,它只受顺序正确性的约束,因此可能生成多线程包含数据竞争的代码。
解决这个问题,需要一个语言级别定义编译器实现的内存模型,以确保用户和编译器在有数据竞争时达成一致。
if (x == 1) ++y;
if (y == 1) ++x;
//编译器将代码重排序,在两个线程分别执行会有问题
++y; if (x != 1) --y;
++x; if (y != 1) --x;
- 正确性问题2)重写临近数据
实例1中,如果在tmp = x和x = tmp中间有一个并发的修改x.b的操作,这个修改将失效。
struct { int a:17; int b:15 } x;
//在小端32位机器上编译器编译成如下形式
{
tmp = x; // Read both fields into
// 32-bit variable.
tmp &= ~0x1ffff; // Mask off old a.
tmp |= 42;
x = tmp; // Overwrite all of x.
}
struct { char a; char b; char c; char d;
char e; char f; char g; char h; } x;
x.b = ’b’; x.c = ’c’; x.d = ’d’;
x.e = ’e’; x.f = ’f’; x.g = ’g’; x.h = ’h’;
// 在64位机器上被编译成:
x = ’hgfedcb\0’ | x.a;
- 正确性问题3)register promotion
引入了对x的额外的读和写,但是此时并没有锁。pthread的要求并不能阻止编译器的这种优化。
for (...) {
...
if (mt) pthread_mutex_lock(...);
x = ... x ...
if (mt) pthread_mutex_unlock(...);
}
// 编译器编译成:
r = x;
for (...) {
...
if (mt) {
x = r; pthread_mutex_lock(...); r = x;
}
r = ... r ...
if (mt) {
x = r; pthread_mutex_unlock(...); r = x;
}
}
x = r;
0.3 性能问题
- pthread_mutex_lock()和pthread_mutex_unlock操作需要一个硬件原子内存更新指令。这些指令隐式地禁止在调用周围对内存引用重排序。或者使用单独的内存屏障指令。这些代价都是相对较高的。
- 纯粹基于库的多线程操作中,不允许并发变量访问。因此,在某些情况下,如果不使用细粒度原子操作,将无法从多处理中获益。
- 为了获得性能,锁操作不应该禁止在其周围的所有重排序。为了并发操作,需要语言规格给出具体的语义,然后编译器实现这些语义。并且实现需要直到一些原语包含了特殊的内存虚限制。(memory ordering constraints)。
1.内存模型涉及的基本概念
- 内存模型为C++虚拟机定义内存存储的语义。
编译器说:“不如这样,你来告诉我哪些数据是线程间共享的。这样,我就可以在必要的时候保守优化,一般情况下全力优化。只要你保证自己的程序是正确同步的,那我保证程序执行时就是你要的那个样子。”这样一个在程序员和语言间的约定,就是“Memory Model”。 - 字节是内存最小的可寻址单位。
- 内存位置(memory location)
1)标量类型的对象(算术类型,指针类型,枚举类型和std::nullptr_t)
2)非零长度的最大连续的位域序列
引用或虚函数等可能涉及程序无法访问但由实现管理的其他内存位置。
struct S {
char a; // memory location #1
int b : 5; // memory location #2
int c : 11, // memory location #2 (continued)
: 0,
d : 8; // memory location #3
struct {
int ee : 8; // memory location #4
} e;
} obj; // The object 'obj' consists of 4 separate memory locations
- visible side-effects
线程1执行写操作A之后,如何可靠并高效地保证线程2执行读操作B时,操作A的结果是完整可见的?
为了解决该问题,引入了happens-before关系:
Let A and B represent operations performed by a multithreaded process. If A happens-before B, then the memory effects of A effectively become visible to the thread performing B before B is performed.
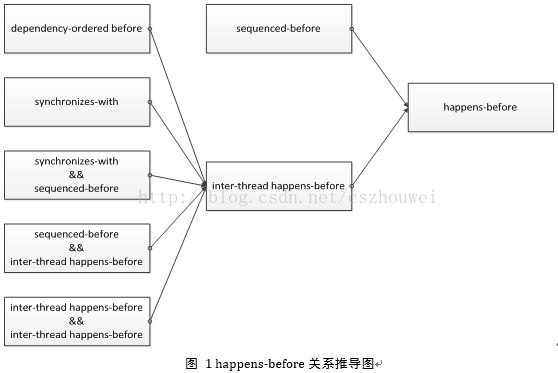
1)sequenced-before(线程内)
在同一个线程内,操作A先于操作B
2)dependency-ordered before (线程间)
case 1:线程1的操作A对变量M执行“release”写,线程2的操作B对变量M执行“consume”读,并且操作B读取到的值源于操作A之后的“release”写序列中的任何一个(包括操作A本身)
case 2:线程1的操作A 与线程2的操作X之间存在dependency-ordered before关系,同时线程2的操作B“depends on”操作X(所谓B“depends on”A,这里就不给出精确的定义,举个直观的例子:B=M[A])
3)synchronizes-with(线程间)
线程1的操作A对变量M执行“release”写,线程2的操作B对变量M执行“acquire”读,并且操作B读取到的值源于操作A之后的“release”写序列中的任何一个(包括操作A本身)
2.线程与数据竞争(data races)
- 执行线程是程序的控制流,由顶层函数(top-level)使用std::thread::thread、std::async或其他方式启动。
- 同时访问同一个内存位置会造成数据竞争。以下三种情况不会发生:
1)两个执行的计算在同一个线程或同一个singnal handler
2)计算都是原子操作(std::atomic)
3)其中一个计算happens-before 另一个(std::memory_order)
可以使用锁来防止数据竞争。
3.内存序——memory order
- 当线程从一个memory location读取值时,可能会看到初始值,同一线程写入的值或者其他线程写入的值。std::memory_order指定哪种值对其他线程可见。
- x86内存模型
因为 store-load 可以被重排,所以x86不是顺序一致。但是因为其他三种读写顺序不能被重排,所以x86是 acquire/release 语义。
aquire语义:load 之后的读写操作无法被重排至 load 之前。即 load-load, load-store 不能被重排。
release语义:store 之前的读写操作无法被重排至 store 之后。即 load-store, store-store 不能被重排。
Loads are not reordered with other loads.Stores are not reordered with other stores.Stores are not reordered with older loads.
Loads may be reordered with older stores to different locations.
3.1 Relaxed ordering
- 在单个线程内,所有原子操作是顺序进行的。按照什么顺序?基本上就是代码顺序(sequenced-before)。这就是唯一的限制了!
- 简单来说,标记为memory_order_relaxed的atomic操作对于memory order几乎不作保证,它们唯一的承诺就是“atomicity”,当然,不能破坏“modification order”的一致性要求。
对于下面代码片段而言,输出r1 == r2 == 42是合法的。这里,我们可以推导出的关系只有A sequenced-before B、C sequenced-before D,仅此而已。 - TIPS:Relaxed ordering比较适用于“计数器”一类的原子变量,不在意memory order的场景。
x = y = 0;
// Thread 1:
r1 = y.load(memory_order_relaxed); // A
x.store(r1, memory_order_relaxed); // B
// Thread 2:
r2 = x.load(memory_order_relaxed); // C
y.store(42, memory_order_relaxed); // D
3.2 Release-Acquire ordering
来自不同线程的两个原子操作顺序不一定?那怎么能限制一下它们的顺序?这就需要两个线程进行一下同步(synchronize-with)。同步什么呢?同步对一个变量的读写操作。线程 A 原子性地把值写入 x (release), 然后线程 B 原子性地读取 x 的值(acquire). 这样线程 B 保证读取到 x 的最新值。注意 release -- acquire 有个副作用:线程 A 中所有发生在 release x 之前的写操作,对在线程 B acquire x 之后的任何读操作都可见!本来 A, B 间读写操作顺序不定。这么一同步,在 x 这个点前后, A, B 线程之间有了个顺序关系,称作 inter-thread happens-before.
首先,我们可以直观地得出如下关系:A sequenced-before B sequenced-before C、C synchronizes-with D、D sequenced-before E sequenced-before F。
利用前述happens-before推导图,不难得出A happens-before E、B happens-before F,因此,这里的E、F两处的assert永远不会fail。TIPS:Release-Acquire ordering难度系数与性能指数相对均衡,属于实现lock-free算法的首选。
#include
#include
#include
#include
std::atomic ptr;
int data;
void producer()
{
std::string* p = new std::string("Hello"); // A
data = 42; // B
ptr.store(p, std::memory_order_release); // C
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire))) // D
;
assert(*p2 == "Hello"); // E
assert(data == 42); // F
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
3.3 Release-Consume ordering
- 只想同步一个 x 的读写操作,结果把 release 之前的写操作都顺带同步了?如果我想避免这个额外开销怎么办?用 release -- consume 呗。同步还是一样的同步,这回副作用弱了点:在线程 B acquire x 之后的读操作中,有一些是依赖于 x 的值的读操作。管这些依赖于 x 的读操作叫 赖B读. 同理在线程 A 里面, release x 也有一些它所依赖的其他写操作,这些写操作自然发生在 release x 之前了。管这些写操作叫 赖A写. 现在这个副作用就是,只有 赖B读 能看见 赖A写.
数据依赖carries dependency
S1. c = a + b;
S2. e = c + d;
S2 数据依赖于 S1,因为它需要 c 的值。
- 这次我们把D处修改为memory_order_consume,情况又会有何不同呢?首先,基本的关系对毋庸置疑:A sequenced-before B sequenced-before C、C dependency-ordered before D、D sequenced-before E sequenced-before F。
那么我们还能那么轻易地推导出A happens-before E、B happens-before F吗?答案是:A、E关系成立,而B、F关系破裂。根据我们之前的定义,E depends-on D,从而可以推导出,接着就是水到渠成了。反观D、F之间并不存在这种依赖关系。因此,这里的E永远不会fail,而F有可能fail。 - TIPS:Release-Consume ordering难度系数最高,强烈不推荐初学者使用,很多大师级人物都在这上面栽过跟头,当然,它的系统开销可能小于Release-Acquire ordering,适用于极致追求性能的场景,前提是你得能够hold住它。
void producer()
{
std::string* p = new std::string("Hello"); // A
data = 42; // B
ptr.store(p, std::memory_order_release); // C
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume))) // D
;
assert(*p2 == "Hello"); // E
assert(data == 42); // F
}
3.4 Sequentially-consistent ordering
- Release -- acquire 就同步一个 x,顺序一致就是对所有的变量的所有原子操作都同步。这么一来,我擦,所有的原子操作就跟由一个线程顺序执行似的。
- 所谓的Sequentially-consistent ordering,其实就是“顺序一致性”,它是最严格的memory order,除了满足前面所说的Release-Acquire/Consume约束之外,所有的线程对于该顺序必须达成一致。
这里,C处的assert是永远不会fail的。反证法:在线程c的世界里,如果++z未执行,需要操作A先于操作B完成;在线程d的世界里,如果++z未执行,需要操作B先于操作A完成。由于这些操作都是memory_order_seq_cst类型,因此,所有的线程需要达成一致,出现矛盾。 - TIPS:Sequentially-consistent ordering难度系数最低,潜在开销可能最大,最符合人类常规思维模型,因此,在多线程编程中最易推理,最不容易出错,强烈推荐初学者使用,当出现性能瓶颈时再考虑优化。
std::atomic x = ATOMIC_VAR_INIT(false);
std::atomic y = ATOMIC_VAR_INIT(false);
std::atomic z = ATOMIC_VAR_INIT(0);
void write_x()
{
x.store(true, std::memory_order_seq_cst); // A
}
void write_y()
{
y.store(true, std::memory_order_seq_cst); // B
}
void read_x_then_y()
{
while (!x.load(std::memory_order_seq_cst))
;
if (y.load(std::memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x()
{
while (!y.load(std::memory_order_seq_cst))
;
if (x.load(std::memory_order_seq_cst)) {
++z;
}
}
int main()
{
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
assert(z.load() != 0); // C
}
3.5 volatile
- 推荐使用场景:信号处理函数中使用到的信号标志变量。关于volatile更多精彩讨论推荐阅读《Nine ways to break your systems code using volatile》。
- 这里的讨论仅限于C/C++,不同语言对于volatile赋予的语义并不相同,比如java中的volatile是保证顺序一致性的。*
4. foward progress演进
- 在一个有效的C++程序中,每个程序最终都会做如下几件事之一:
1)终止
2)调用IO库函数
3)执行volatile glvalue访问
4)执行一个原子操作或者一个同步操作
没有一个线程一直运行,却不执行这些操作的任何一种。这表明这种无线递归或循环的程序是未定义的行为。编译器可以去掉这种循环。 - make progress演进
一个进程是make progress,如果执行了以下动作:
1)在(I/O、volatile、atomic、同步)上执行了
2)阻塞在标准库函数里面
3)调用原子无锁函数没有完成执行,因为一个非阻塞的并发线程 - 三种演进(forward progress)
1)并发forward progress
只要线程没有终止,将在有限时间内make progress,无论其他线程是否make progress。
2)并行forward progress
如果线程尚未执行任何(I/O、volatile、atomic、同步),则无需确保make progress。但是一旦执行,将提供1)中的并发forward progress保证。(此规则描述了线程池中的线程以任意顺序执行任务)
3)弱并行forward progress
不保证最终make progress。