Author: Zuguang Gu ( [email protected] )
翻译:诗翔
Date: 2018-10-30
一个简单的热图通常用户快速浏览数据。一个热图列表的特殊例子就是只包含一个热图。相比于已经存在的工具, ComplexHeatmap包提供了一种更灵活的方式支持单个热图的可视化。在下面的例子中,我们会说明如何设置参数以显示一个简单的热图。
首先让我们载入包并生成一个随机矩阵。
library(ComplexHeatmap)
library(circlize)
set.seed(123)
mat = cbind(rbind(matrix(rnorm(16, -1), 4), matrix(rnorm(32, 1), 8)),
rbind(matrix(rnorm(24, 1), 4), matrix(rnorm(48, -1), 8)))
# 置换行列
mat = mat[sample(nrow(mat), nrow(mat)), sample(ncol(mat), ncol(mat))]
rownames(mat) = paste0("R", 1:12)
colnames(mat) = paste0("C", 1:10)
使用默认的设置绘制热图。热图默认的样式跟其他相似热图函数生成的效果很接近。
Heatmap(mat)

颜色
大多数情况下,热图可视化含连续值得矩阵。在这种情况下,用户需要提供一个颜色映射函数。一个颜色映射函数需要接收一个数值向量并返回对应的颜色。circlize包提供的colorRamp2()对于生成这样的函数很有用。当前该函数通过LAB颜色空间线性地在每个区间插入颜色。
在下面的例子中,-3到3的区间被线性插入值用于获取对应的颜色,值大于3的被映射为红色,小于-3的被映射为绿色(因此这里的颜色对于异常值具有鲁棒性)。
mat2 = mat
mat2[1, 1] = 100000
Heatmap(mat2, col = colorRamp2(c(-3, 0, 3), c("green", "white", "red")),
cluster_rows = FALSE, cluster_columns = FALSE)

如果矩阵值是连续的,你也可以提供一个颜色向量,颜色会根据第"k"个百分位进行插值。但是记住这种方法对于异常点没有鲁棒性。
Heatmap(mat, col = rev(rainbow(10)))
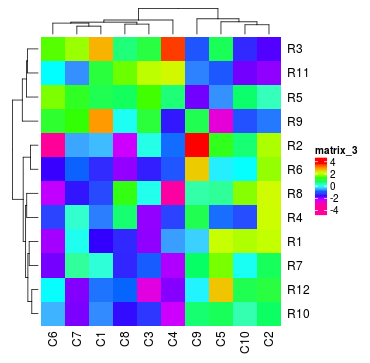
如果矩阵包含离散值(要么是数值的要么是字符串),颜色应该指定为一个命名向量用于将离散值映射为颜色。如果颜色没有名字,那么颜色的顺序会对应于unique(mat)的顺序。
discrete_mat = matrix(sample(1:4, 100, replace = TRUE), 10, 10)
colors = structure(circlize::rand_color(4), names = c("1", "2", "3", "4"))
Heatmap(discrete_mat, col = colors)
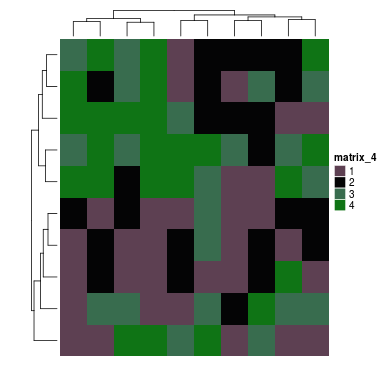
或者一个字符串矩阵:
discrete_mat = matrix(sample(letters[1:4], 100, replace = TRUE), 10, 10)
colors = structure(circlize::rand_color(4), names = letters[1:4])
Heatmap(discrete_mat, col = colors)
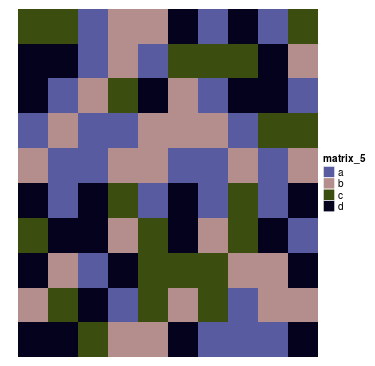
你可以看到,对于数值型矩阵(无论它是连续映射还是离散映射),默认两个维度都会进行聚类。而对于字符串矩阵,聚类默认是被抑制的。
热图中允许存在NA值。你可以通过na_col参数控制NA值的颜色。包含NA值矩阵也可以使用Heatmap()函数聚类(因为dist()函数接收NA值),使用“pearson”、 “spearman” 或 “kendall” 方法会给出警告信息。
mat_with_na = mat
mat_with_na[sample(c(TRUE, FALSE), nrow(mat)*ncol(mat), replace = TRUE, prob = c(1, 9))] = NA
Heatmap(mat_with_na, na_col = "orange", clustering_distance_rows = "pearson")
## Warning in get_dist(submat, distance): NA exists in the matrix, calculating distance by removing NA
## values.
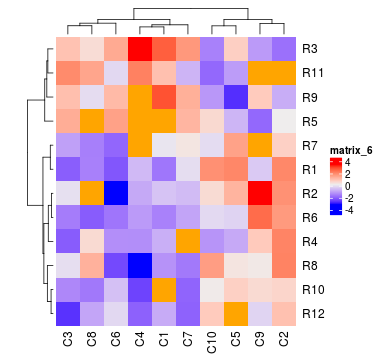
对颜色插值来说颜色空间非常重要。默认情况下,颜色都是在LAB color space中线性插值,但你可以使用,colorRamp2()函数选择其他的颜色空间。比较下面的两幅图:
f1 = colorRamp2(seq(min(mat), max(mat), length = 3), c("blue", "#EEEEEE", "red"))
f2 = colorRamp2(seq(min(mat), max(mat), length = 3), c("blue", "#EEEEEE", "red"), space = "RGB")
Heatmap(mat, col = f1, column_title = "LAB color space") +
Heatmap(mat, col = f2, column_title = "RGB color space")
下面图形显示了不同颜色空间的差别(使用HilbertCurve包绘制)。

标题
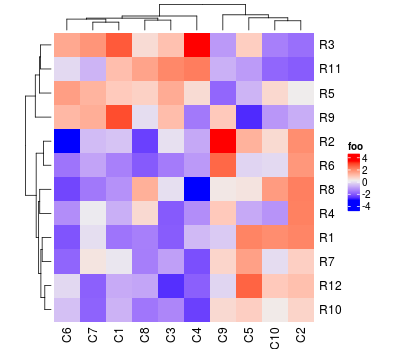
热图的名字默认用作热图图例的标题。如果你将多个热图放到一起,名字可以作为唯一的标识符。
Heatmap(mat, name = "foo")
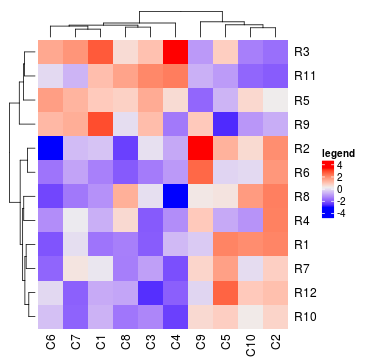
热图图例的标题可以通过参数heatmap_legend_param进行更改。
Heatmap(mat, heatmap_legend_param = list(title = "legend"))
你可以设定热图的行与列标题,行与列图形参数分别通过row_title_gp和column_title_gp选项指定,使用gpar()函数进行具体的设置。
Heatmap(mat, name = "foo", column_title = "I am a column title",
row_title = "I am a row title")

Heatmap(mat, name = "foo", column_title = "I am a big column title",
column_title_gp = gpar(fontsize = 20, fontface = "bold"))

标题的选择可以使用row_title_rot和column_title_rot设置,但只支持水平和垂直旋转。
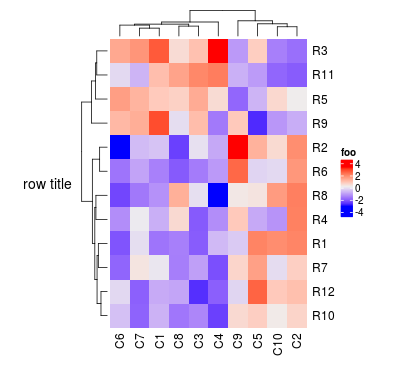
Heatmap(mat, name = "foo", row_title = "row title", row_title_rot = 0)
聚类
聚类是热图可视化的关键特征之一。该包支持高度灵活的聚类设定。
首先有一些聚类的通用设定,例如是否显示树状图、其大小。
Heatmap(mat, name = "foo", cluster_rows = FALSE)

Heatmap(mat, name = "foo", show_column_dend = FALSE)
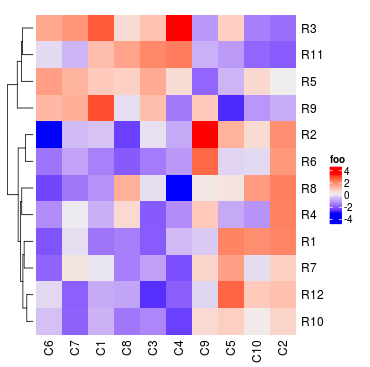
Heatmap(mat, name = "foo", row_dend_side = "right")
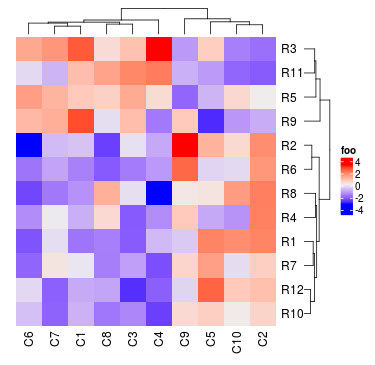
Heatmap(mat, name = "foo", column_dend_height = unit(2, "cm"))
有3种方式指定聚类的距离度量:
- 使用提前设定的选项,合法的值包括
dist()函数支持的方法以及pearson、spearman和kendall。 - 一个从矩阵中计算距离的自定义函数,函数仅包含一个参数
- 一个从两个向量中计算距离的自定义函数,函数仅包含2个参数
Heatmap(mat, name = "foo", clustering_distance_rows = "pearson")

Heatmap(mat, name = "foo", clustering_distance_rows = function(m) dist(m))
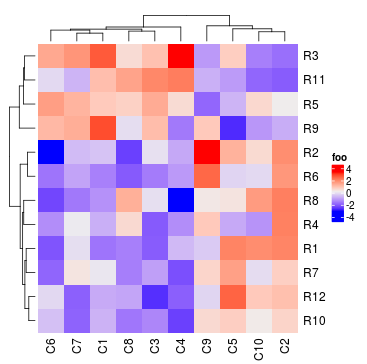
Heatmap(mat, name = "foo", clustering_distance_rows = function(x, y) 1 - cor(x, y))

基于这个特征,我们开源使用配对距离应用聚类使得可以鲁棒地处理异常值。
mat_with_outliers = mat
for(i in 1:10) mat_with_outliers[i, i] = 1000
robust_dist = function(x, y) {
qx = quantile(x, c(0.1, 0.9))
qy = quantile(y, c(0.1, 0.9))
l = x > qx[1] & x < qx[2] & y > qy[1] & y < qy[2]
x = x[l]
y = y[l]
sqrt(sum((x - y)^2))
}
Heatmap(mat_with_outliers, name = "foo",
col = colorRamp2(c(-3, 0, 3), c("green", "white", "red")),
clustering_distance_rows = robust_dist,
clustering_distance_columns = robust_dist)

如果提供了距离方法,你也可以对字符串矩阵进行聚类。cell_fun参数会在后面进行解释。
mat_letters = matrix(sample(letters[1:4], 100, replace = TRUE), 10)
# distance in th ASCII table
dist_letters = function(x, y) {
x = strtoi(charToRaw(paste(x, collapse = "")), base = 16)
y = strtoi(charToRaw(paste(y, collapse = "")), base = 16)
sqrt(sum((x - y)^2))
}
Heatmap(mat_letters, name = "foo", col = structure(2:5, names = letters[1:4]),
clustering_distance_rows = dist_letters, clustering_distance_columns = dist_letters,
cell_fun = function(j, i, x, y, w, h, col) {
grid.text(mat_letters[i, j], x, y)
})

创建层次聚类的方法可以通过选项clustering_method_rows和clustering_method_columns指定,可以使用hclust()函数支持的方法。
Heatmap(mat, name = "foo", clustering_method_rows = "single")
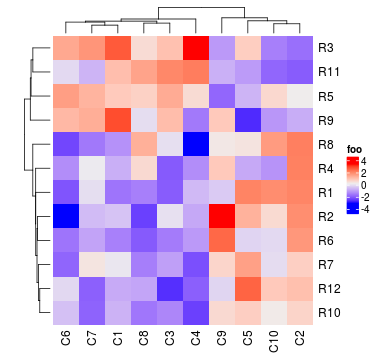
默认,聚类由hclust()实施。但你可以通过cluster_rows或cluster_columns指定由其他方法生成的hclust或dendrogram对象。在下面的例子中,我们使用来自cluster包的diana()和agnes()函数进行聚类。
library(cluster)
Heatmap(mat, name = "foo", cluster_rows = as.dendrogram(diana(mat)),
cluster_columns = as.dendrogram(agnes(t(mat))))

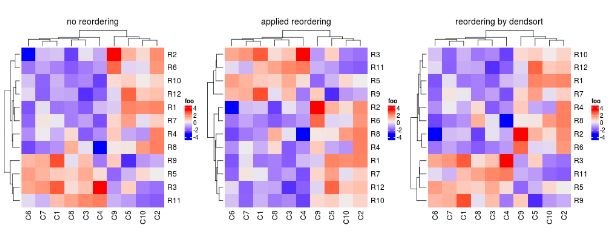
在原始的Heatmap()函数中,行或列的树状图都是根据使得特征可以最大地进行分隔而排序的,Heatmap()提供了选项进行调整。除了默认的重排序方法,你也可以先生成一个树状图,然后应用一些重排序的方法,然后将重排序的树状图传给cluster_rows参数。
比较下面3幅图:
pushViewport(viewport(layout = grid.layout(nr = 1, nc = 3)))
pushViewport(viewport(layout.pos.row = 1, layout.pos.col = 1))
draw(Heatmap(mat, name = "foo", row_dend_reorder = FALSE, column_title = "no reordering"), newpage = FALSE)
upViewport()
pushViewport(viewport(layout.pos.row = 1, layout.pos.col = 2))
draw(Heatmap(mat, name = "foo", row_dend_reorder = TRUE, column_title = "applied reordering"), newpage = FALSE)
upViewport()
library(dendsort)
dend = dendsort(hclust(dist(mat)))
pushViewport(viewport(layout.pos.row = 1, layout.pos.col = 3))
draw(Heatmap(mat, name = "foo", cluster_rows = dend, row_dend_reorder = FALSE,
column_title = "reordering by dendsort"), newpage = FALSE)
upViewport(2)
你可以使用dendextend包渲染你的dendrogram对象,自定义树状图。
library(dendextend)
dend = hclust(dist(mat))
dend = color_branches(dend, k = 2)
Heatmap(mat, name = "foo", cluster_rows = dend)

更通用地,cluster_rows和cluster_columns可以提供计算聚类的函数。自定义函数的输入需要是一个矩阵,返回值需要时一个hclust或者dendrogram对象。
Heatmap(mat, name = "foo", cluster_rows = function(m) as.dendrogram(diana(m)),
cluster_columns = function(m) as.dendrogram(agnes(m)))
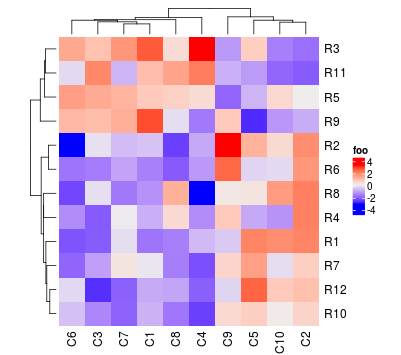
fastcluster::hclust实现了更快版本的hclust。
# code not run when building the vignette
Heatmap(mat, name = "foo", cluster_rows = function(m) fastcluster::hclust(dist(m)),
cluster_columns = function(m) fastcluster::hclust(dist(m))) # for column cluster, m will be automatically transposed

为了更方便的使用快速版本的hclust,我们可以设定一个全局选项。
# code not run when building the vignette
ht_global_opt(fast_hclust = TRUE)
# now hclust from fastcluster package is used in all heatmaps
Heatmap(mat, name = "foo")

聚类可以帮助调整行和列的顺序。但是你仍然需要手动设定row_order和column_order来设定顺序。注意这个时候你需要将聚类给关掉,另外如果矩阵有行名和列名也可以直接通过名字调整顺序。
Heatmap(mat, name = "foo", cluster_rows = FALSE, cluster_columns = FALSE,
row_order = 12:1, column_order = 10:1)

注意row_dend_reorder和row_order是不同的。前者应用于树状图。因为对于树状图的任何结点,旋转两个叶子都会给出唯一的树状图。当row_order设置时,树状图会被抑制。
维度名字
维度名字的侧边、可视度和图形参数可以进行如下设置。
Heatmap(mat, name = "foo", row_names_side = "left", row_dend_side = "right",
column_names_side = "top", column_dend_side = "bottom")

Heatmap(mat, name = "foo", show_row_names = FALSE)
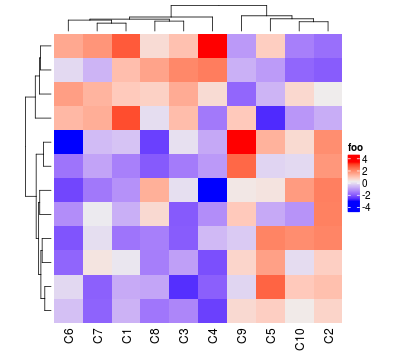
Heatmap(mat, name = "foo", row_names_gp = gpar(fontsize = 20))

Heatmap(mat, name = "foo", row_names_gp = gpar(col = c(rep("red", 4), rep("blue", 8))))

当前行名和列名不支持旋转。文字旋转可以通过热图注释实现(这在热图注释手册中将会看到)。
按行切分热图
热图可以按行切分。这可以增加热图中的分组可视化。参数km设置大于1的值意味着对行实施K-means聚类并在每个子类中实施聚类。
Heatmap(mat, name = "foo", km = 2)
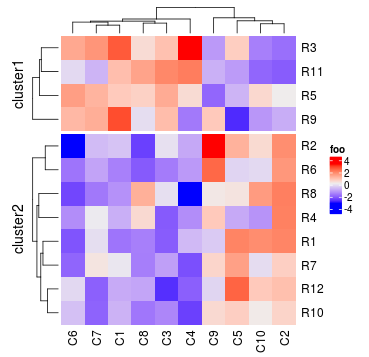
更通用地,split可以传入一个分割热图行不同组合水平的向量或是数据框。实际上k-means聚类也是先聚类得到行的分类然后使用split实现切分。每一个行切片的标题可以通过combined_name_fun参数设定。每个切片的顺序通过split中每个变量的水平控制。
Heatmap(mat, name = "foo", split = rep(c("A", "B"), 6))
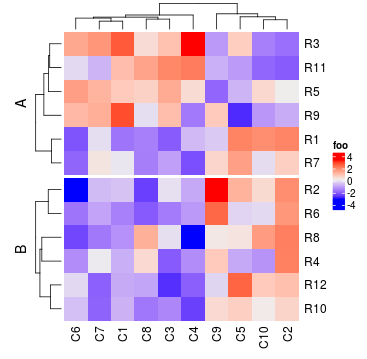
Heatmap(mat, name = "foo", split = data.frame(rep(c("A", "B"), 6), rep(c("C", "D"), each = 6)))

Heatmap(mat, name = "foo", split = data.frame(rep(c("A", "B"), 6), rep(c("C", "D"), each = 6)),
combined_name_fun = function(x) paste(x, collapse = "\n"))
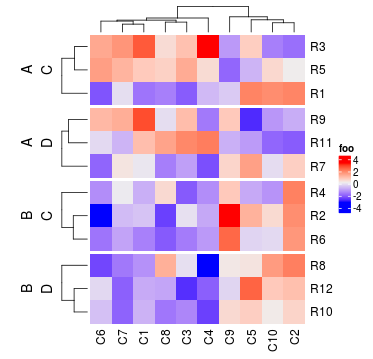
Heatmap(mat, name = "foo", km = 2, split = factor(rep(c("A", "B"), 6), levels = c("B", "A")),
combined_name_fun = function(x) paste(x, collapse = "\n"))

Heatmap(mat, name = "foo", km = 2, split = rep(c("A", "B"), 6), combined_name_fun = NULL)

如果你不喜欢默认的k-means分类方法,你可以通过将分类向量传入split的方式使用其他方法。
pa = pam(mat, k = 3)
Heatmap(mat, name = "foo", split = paste0("pam", pa$clustering))
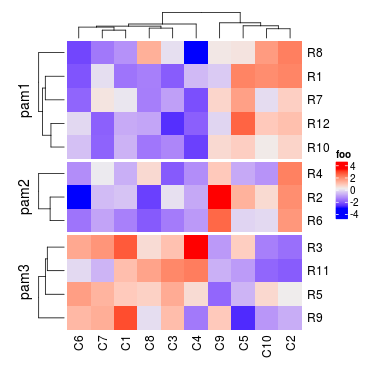
如果row_order设置了,在每个切片里面,行依然是按顺序排列的。
Heatmap(mat, name = "foo", row_order = 12:1, cluster_rows = FALSE, km = 2)

gap的高度可以通过gap参数控制(单个unit或者units向量)。
Heatmap(mat, name = "foo", split = paste0("pam", pa$clustering), gap = unit(5, "mm"))

字符串矩阵也可以通过split参数切分。
Heatmap(discrete_mat, name = "foo", col = 1:4,
split = rep(letters[1:2], each = 5))
当按行切分的时候,也可以通过图形参数自定义行标题和行名。
Heatmap(mat, name = "foo", km = 2, row_title_gp = gpar(col = c("red", "blue"), font = 1:2),
row_names_gp = gpar(col = c("green", "orange"), fontsize = c(10, 14)))
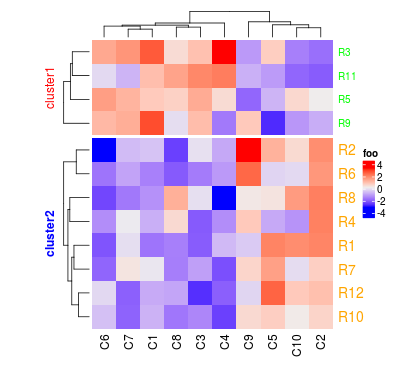
用户可能已经有一个行的树状图了,他们可能想要将树状图分为k个子树。这种情况下,split可以指定一个数。
dend = hclust(dist(mat))
dend = color_branches(dend, k = 2)
Heatmap(mat, name = "foo", cluster_rows = dend, split = 2)

或者可以直接指定split一个整数。注意这跟km不同。如果km设置了,首先是要k-means聚类,然后对每个子类进行聚类。当split是一个整数的时候,直接对整个矩阵进行聚类,然后根据cutree()切分。
Heatmap(mat, name = "foo", split = 2)
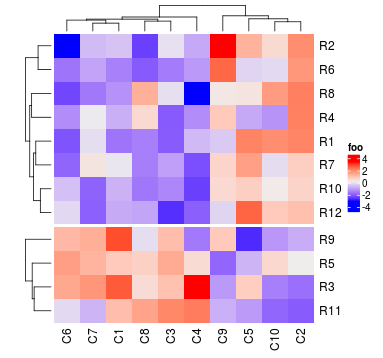
自定义热图主体
rect_gp参数提供了热图主体的基本图形设置(注意fill参数已经被禁用了)。
Heatmap(mat, name = "foo", rect_gp = gpar(col = "green", lty = 2, lwd = 2))

热图主体可以自定义。默认热图主体由带不同填充色的矩形数组组成(这里称为cell)。如果rect_gp中的type设置为none,整个cell数组被初始化但没有图形,然后用户可以通过cell_fun自定义他们自己的图形函数。cell_fun应用于热图的每一个cell,它需要为每一个cell提供下面的信息:
-
j- 矩阵中的列索引。 -
i- 矩阵中的行索引 -
x- cell中心点的x坐标 -
y- cell中心点的y坐标 -
width- cell的宽度 -
height- cell 的高度 -
fill- cell的填充色
最常见的使用是给热图添加数值信息。
Heatmap(mat, name = "foo", cell_fun = function(j, i, x, y, width, height, fill) {
grid.text(sprintf("%.1f", mat[i, j]), x, y, gp = gpar(fontsize = 10))
})

下面的例子中,我们创建一个类似corrplot包提供的相关矩阵图。
cor_mat = cor(mat)
od = hclust(dist(cor_mat))$order
cor_mat = cor_mat[od, od]
nm = rownames(cor_mat)
col_fun = circlize::colorRamp2(c(-1, 0, 1), c("green", "white", "red"))
# `col = col_fun` here is used to generate the legend
Heatmap(cor_mat, name = "correlation", col = col_fun, rect_gp = gpar(type = "none"),
cell_fun = function(j, i, x, y, width, height, fill) {
grid.rect(x = x, y = y, width = width, height = height, gp = gpar(col = "grey", fill = NA))
if(i == j) {
grid.text(nm[i], x = x, y = y)
} else if(i > j) {
grid.circle(x = x, y = y, r = abs(cor_mat[i, j])/2 * min(unit.c(width, height)),
gp = gpar(fill = col_fun(cor_mat[i, j]), col = NA))
} else {
grid.text(sprintf("%.1f", cor_mat[i, j]), x, y, gp = gpar(fontsize = 8))
}
}, cluster_rows = FALSE, cluster_columns = FALSE,
show_row_names = FALSE, show_column_names = FALSE)

最后一个例子是可视化围棋,输入数据记录在游戏中的形势。
str = "B[cp];W[pq];B[dc];W[qd];B[eq];W[od];B[de];W[jc];B[qk];W[qn]
;B[qh];W[ck];B[ci];W[cn];B[hc];W[je];B[jq];W[df];B[ee];W[cf]
;B[ei];W[bc];B[ce];W[be];B[bd];W[cd];B[bf];W[ad];B[bg];W[cc]
;B[eb];W[db];B[ec];W[lq];B[nq];W[jp];B[iq];W[kq];B[pp];W[op]
;B[po];W[oq];B[rp];W[ql];B[oo];W[no];B[pl];W[pm];B[np];W[qq]
;B[om];W[ol];B[pk];W[qp];B[on];W[rm];B[mo];W[nr];B[rl];W[rk]
;B[qm];W[dp];B[dq];W[ql];B[or];W[mp];B[nn];W[mq];B[qm];W[bp]
;B[co];W[ql];B[no];W[pr];B[qm];W[dd];B[pn];W[ed];B[bo];W[eg]
;B[ef];W[dg];B[ge];W[gh];B[gf];W[gg];B[ek];W[ig];B[fd];W[en]
;B[bn];W[ip];B[dm];W[ff];B[cb];W[fe];B[hp];W[ho];B[hq];W[el]
;B[dl];W[fk];B[ej];W[fp];B[go];W[hn];B[fo];W[em];B[dn];W[eo]
;B[gp];W[ib];B[gc];W[pg];B[qg];W[ng];B[qc];W[re];B[pf];W[of]
;B[rc];W[ob];B[ph];W[qo];B[rn];W[mi];B[og];W[oe];B[qe];W[rd]
;B[rf];W[pd];B[gm];W[gl];B[fm];W[fl];B[lj];W[mj];B[lk];W[ro]
;B[hl];W[hk];B[ik];W[dk];B[bi];W[di];B[dj];W[dh];B[hj];W[gj]
;B[li];W[lh];B[kh];W[lg];B[jn];W[do];B[cl];W[ij];B[gk];W[bl]
;B[cm];W[hk];B[jk];W[lo];B[hi];W[hm];B[gk];W[bm];B[cn];W[hk]
;B[il];W[cq];B[bq];W[ii];B[sm];W[jo];B[kn];W[fq];B[ep];W[cj]
;B[bk];W[er];B[cr];W[gr];B[gk];W[fj];B[ko];W[kp];B[hr];W[jr]
;B[nh];W[mh];B[mk];W[bb];B[da];W[jh];B[ic];W[id];B[hb];W[jb]
;B[oj];W[fn];B[fs];W[fr];B[gs];W[es];B[hs];W[gn];B[kr];W[is]
;B[dr];W[fi];B[bj];W[hd];B[gd];W[ln];B[lm];W[oi];B[oh];W[ni]
;B[pi];W[ki];B[kj];W[ji];B[so];W[rq];B[if];W[jf];B[hh];W[hf]
;B[he];W[ie];B[hg];W[ba];B[ca];W[sp];B[im];W[sn];B[rm];W[pe]
;B[qf];W[if];B[hk];W[nj];B[nk];W[lr];B[mn];W[af];B[ag];W[ch]
;B[bh];W[lp];B[ia];W[ja];B[ha];W[sf];B[sg];W[se];B[eh];W[fh]
;B[in];W[ih];B[ae];W[so];B[af]"
然后我们将它转换为一个矩阵:
str = gsub("\\n", "", str)
step = strsplit(str, ";")[[1]]
type = gsub("(B|W).*", "\\1", step)
row = gsub("(B|W)\\[(.).\\]", "\\2", step)
column = gsub("(B|W)\\[.(.)\\]", "\\2", step)
mat = matrix(nrow = 19, ncol = 19)
rownames(mat) = letters[1:19]
colnames(mat) = letters[1:19]
for(i in seq_along(row)) {
mat[row[i], column[i]] = type[i]
}
mat
## a b c d e f g h i j k l m n o p q r s
## a NA NA NA "W" "B" "B" "B" NA NA NA NA NA NA NA NA NA NA NA NA
## b "W" "W" "W" "B" "W" "B" "B" "B" "B" "B" "B" "W" "W" "B" "B" "W" "B" NA NA
## c "B" "B" "W" "W" "B" "W" NA "W" "B" "W" "W" "B" "B" "B" "B" "B" "W" "B" NA
## d "B" "W" "B" "W" "B" "W" "W" "W" "W" "B" "W" "B" "B" "B" "W" "W" "B" "B" NA
## e NA "B" "B" "W" "B" "B" "W" "B" "B" "B" "B" "W" "W" "W" "W" "B" "B" "W" "W"
## f NA NA NA "B" "W" "W" NA "W" "W" "W" "W" "W" "B" "W" "B" "W" "W" "W" "B"
## g NA NA "B" "B" "B" "B" "W" "W" NA "W" "B" "W" "B" "W" "B" "B" NA "W" "B"
## h "B" "B" "B" "W" "B" "W" "B" "B" "B" "B" "B" "B" "W" "W" "W" "B" "B" "B" "B"
## i "B" "W" "B" "W" "W" "W" "W" "W" "W" "W" "B" "B" "B" "B" NA "W" "B" NA "W"
## j "W" "W" "W" NA "W" "W" NA "W" "W" NA "B" NA NA "B" "W" "W" "B" "W" NA
## k NA NA NA NA NA NA NA "B" "W" "B" NA NA NA "B" "B" "W" "W" "B" NA
## l NA NA NA NA NA NA "W" "W" "B" "B" "B" NA "B" "W" "W" "W" "W" "W" NA
## m NA NA NA NA NA NA NA "W" "W" "W" "B" NA NA "B" "B" "W" "W" NA NA
## n NA NA NA NA NA NA "W" "B" "W" "W" "B" NA NA "B" "B" "B" "B" "W" NA
## o NA "W" NA "W" "W" "W" "B" "B" "W" "B" NA "W" "B" "B" "B" "W" "W" "B" NA
## p NA NA NA "W" "W" "B" "W" "B" "B" NA "B" "B" "W" "B" "B" "B" "W" "W" NA
## q NA NA "B" "W" "B" "B" "B" "B" NA NA "B" "W" "B" "W" "W" "W" "W" NA NA
## r NA NA "B" "W" "W" "B" NA NA NA NA "W" "B" "B" "B" "W" "B" "W" NA NA
## s NA NA NA NA "W" "W" "B" NA NA NA NA NA "B" "W" "W" "W" NA NA NA
基于矩阵的值我们放上黑子和白子。
Heatmap(mat, name = "go", rect_gp = gpar(type = "none"),
cell_fun = function(j, i, x, y, w, h, col) {
grid.rect(x, y, w, h, gp = gpar(fill = "#dcb35c", col = NA))
if(i == 1) {
grid.segments(x, y-h*0.5, x, y)
} else if(i == nrow(mat)) {
grid.segments(x, y, x, y+h*0.5)
} else {
grid.segments(x, y-h*0.5, x, y+h*0.5)
}
if(j == 1) {
grid.segments(x, y, x+w*0.5, y)
} else if(j == ncol(mat)) {
grid.segments(x-w*0.5, y, x, y)
} else {
grid.segments(x-w*0.5, y, x+w*0.5, y)
}
if(i %in% c(4, 10, 16) & j %in% c(4, 10, 16)) {
grid.points(x, y, pch = 16, size = unit(2, "mm"))
}
r = min(unit.c(w, h))*0.45
if(is.na(mat[i, j])) {
} else if(mat[i, j] == "W") {
grid.circle(x, y, r, gp = gpar(fill = "white", col = "white"))
} else if(mat[i, j] == "B") {
grid.circle(x, y, r, gp = gpar(fill = "black", col = "black"))
}
},
col = c("B" = "black", "W" = "white"),
show_row_names = FALSE, show_column_names = FALSE,
column_title = "One famous GO game",
heatmap_legend_param = list(title = "Player", at = c("B", "W"),
labels = c("player1", "player2"), grid_border = "black")
)

将热图主体设置为光栅图像
将图形以PDF格式保存时保存质量的最好方式。然而,如果行数太多(> 10000),输出的PDF文件将非常之大。将热图渲染为光栅图像可以减少文件大小。Heatmap()函数中有4个选项控制如何生成光栅图像:use_raster、raster_device、raster_quality和raster_device_param。
你可以通过raster_device选择图像设备(png、jpeg和tiff),使用raster_quality控制图像质量,raster_device_param可以传入更多参数。
会话信息
sessionInfo()
## R version 3.5.1 Patched (2018-07-12 r74967)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 16.04.5 LTS
##
## Matrix products: default
## BLAS: /home/biocbuild/bbs-3.8-bioc/R/lib/libRblas.so
## LAPACK: /home/biocbuild/bbs-3.8-bioc/R/lib/libRlapack.so
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C LC_TIME=en_US.UTF-8
## [4] LC_COLLATE=C LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] stats4 parallel grid stats graphics grDevices utils datasets methods
## [10] base
##
## other attached packages:
## [1] dendextend_1.9.0 dendsort_0.3.3 cluster_2.0.7-1 IRanges_2.16.0
## [5] S4Vectors_0.20.0 BiocGenerics_0.28.0 HilbertCurve_1.12.0 circlize_0.4.4
## [9] ComplexHeatmap_1.20.0 knitr_1.20 markdown_0.8
##
## loaded via a namespace (and not attached):
## [1] mclust_5.4.1 Rcpp_0.12.19 mvtnorm_1.0-8 lattice_0.20-35
## [5] png_0.1-7 class_7.3-14 assertthat_0.2.0 mime_0.6
## [9] R6_2.3.0 GenomeInfoDb_1.18.0 plyr_1.8.4 evaluate_0.12
## [13] ggplot2_3.1.0 highr_0.7 pillar_1.3.0 GlobalOptions_0.1.0
## [17] zlibbioc_1.28.0 rlang_0.3.0.1 lazyeval_0.2.1 diptest_0.75-7
## [21] kernlab_0.9-27 whisker_0.3-2 GetoptLong_0.1.7 stringr_1.3.1
## [25] RCurl_1.95-4.11 munsell_0.5.0 compiler_3.5.1 pkgconfig_2.0.2
## [29] shape_1.4.4 nnet_7.3-12 tidyselect_0.2.5 gridExtra_2.3
## [33] tibble_1.4.2 GenomeInfoDbData_1.2.0 viridisLite_0.3.0 crayon_1.3.4
## [37] dplyr_0.7.7 MASS_7.3-51 bitops_1.0-6 gtable_0.2.0
## [41] magrittr_1.5 scales_1.0.0 stringi_1.2.4 XVector_0.22.0
## [45] viridis_0.5.1 flexmix_2.3-14 bindrcpp_0.2.2 robustbase_0.93-3
## [49] fastcluster_1.1.25 HilbertVis_1.40.0 rjson_0.2.20 RColorBrewer_1.1-2
## [53] tools_3.5.1 fpc_2.1-11.1 glue_1.3.0 trimcluster_0.1-2.1
## [57] DEoptimR_1.0-8 purrr_0.2.5 colorspace_1.3-2 GenomicRanges_1.34.0
## [61] prabclus_2.2-6 bindr_0.1.1 modeltools_0.2-22