Scrapy抓取到网页数据,保存到数据库,是通过pipelines来处理的。看一下官方文档的说明。
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
一、解析页面数据 Spider类
本文以《读书》专题为例,抓取专题收录的所有文章数据,http://www.jianshu.com/collection/yD9GAd
把需要爬取的页面数据解析出来,封装成对象Item,提交(yield)。
item = JsArticleItem()
author = info.xpath('p/a/text()').extract()
pubday = info.xpath('p/span/@data-shared-at').extract()
author_url = info.xpath('p/a/@href').extract()
title = info.xpath('h4/a/text()').extract()
url = info.xpath('h4/a/@href').extract()
reads = info.xpath('div/a[1]/text()').extract()
reads = filter(str.isdigit, str(reads[0]))
comments = info.xpath('div/a[2]/text()').extract()
comments = filter(str.isdigit, str(comments[0]))
likes = info.xpath('div/span[1]/text()').extract()
likes = filter(str.isdigit,str(likes[0]))
rewards = info.xpath('div/span[2]/text()')
## 判断文章有无打赏数据
if len(rewards)==1 :
rds = info.xpath('div/span[2]/text()').extract()
rds = int(filter(str.isdigit,str(rds[0])))
else:
rds = 0
item['author'] = author
item['url'] = 'http://www.jianshu.com'+url[0]
item['reads'] = reads
item['title'] = title
item['comments'] = comments
item['likes'] = likes
item['rewards'] = rds
item['pubday'] = pubday
yield item
定义好的Item类,在items.py中
class JsArticleItem(Item):
author = Field()
url = Field()
title = Field()
reads = Field()
comments = Field()
likes = Field()
rewards = Field()
pubday = Field()
二、pipelines.py中定义一个类,操作数据库
class WebcrawlerScrapyPipeline(object):
'''保存到数据库中对应的class
1、在settings.py文件中配置
2、在自己实现的爬虫类中yield item,会自动执行'''
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
'''1、@classmethod声明一个类方法,而对于平常我们见到的叫做实例方法。
2、类方法的第一个参数cls(class的缩写,指这个类本身),而实例方法的第一个参数是self,表示该类的一个实例
3、可以通过类来调用,就像C.f(),相当于java中的静态方法'''
#读取settings中配置的数据库参数
dbparams = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8', # 编码要加上,否则可能出现中文乱码问题
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=False,
)
dbpool = adbapi.ConnectionPool('MySQLdb', **dbparams) # **表示将字典扩展为关键字参数,相当于host=xxx,db=yyy....
return cls(dbpool) # 相当于dbpool付给了这个类,self中可以得到
# pipeline默认调用
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item) # 调用插入的方法
query.addErrback(self._handle_error, item, spider) # 调用异常处理方法
return item
# 写入数据库中
# SQL语句在这里
def _conditional_insert(self, tx, item):
sql = "insert into jsbooks(author,title,url,pubday,comments,likes,rewards,views) values(%s,%s,%s,%s,%s,%s,%s,%s)"
params = (item['author'], item['title'], item['url'], item['pubday'],item['comments'],item['likes'],item['rewards'],item['reads'])
tx.execute(sql, params)
# 错误处理方法
def _handle_error(self, failue, item, spider):
print failue
三、在settings.py中指定数据库操作的类,启用pipelines组件
ITEM_PIPELINES = {
'jsuser.pipelines.WebcrawlerScrapyPipeline': 300,#保存到mysql数据库
}
#Mysql数据库的配置信息
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = 'testdb' #数据库名字,请修改
MYSQL_USER = 'root' #数据库账号,请修改
MYSQL_PASSWD = '1234567' #数据库密码,请修改
MYSQL_PORT = 3306 #数据库端口,在dbhelper中使用
其他设置,伪装浏览器请求,设置延迟抓取,防ban
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
ROBOTSTXT_OBEY=False
DOWNLOAD_DELAY = 0.25 # 250 ms of delay
运行爬虫,cmdline.execute("scrapy crawl zhanti".split()) 开始,OK!
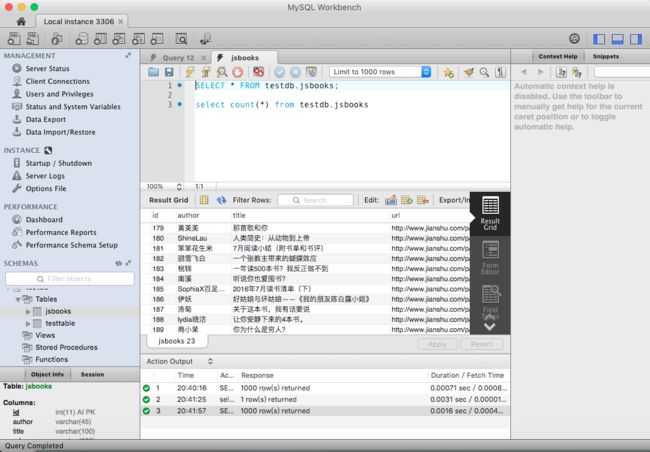
Scrapy爬取数据存入Mongdb貌似更方便,代码更少,看下面文章链接。
我的Scrapy爬虫框架系列文章:
- 《Scrapy爬取用户url分析》
- 《Scrapy+Mongodb爬取数据》
- 《Scrapy输出CSV指定列顺序》
- 《使用Scrapy ItemLoaders爬取整站图片》
- 《Scrapy用Cookie实现模拟登录》