之前介绍过本地模式(伪分布式)安装运行Hadoop,今天介绍一下如何在分布式的环境下安装并运行Hadoop。
0x00 介绍
首先说一下环境:一个NameNode节点,一个SecondaryNameNode节点,三个DataNode节点
NameNode -- hostname:namenode.athrob.com -- IP:192.168.187.128 -- 【NameNode节点和JobTracker节点】
SecondaryNameNode -- hostname:snn.athrob.com -- IP:192.168.187.129 -- 【SecondaryNameNode节点】
DataNode1 -- hostname:dn1.athrob.com -- IP:192.168.187.130 -- 【DataNode和TaskTracker节点】
DataNode2 -- hostname:dn2.athrob.com -- IP:192.168.187.131 -- 【DataNode和TaskTracker节点】
DataNode3 -- hostname:dn3.athrob.com -- IP:192.168.187.132 -- 【DataNode和TaskTracker节点】
0x01 其他准备
[1]修改hostname
CentOS修改hostname需要修改两个文件:
(1) /etc/sysconfig/network
(2) /etc/hosts
例如,我想修改我的hostname为:snn.athrob.com
一、vi打开[1]中的这个network文件,将HOSTNAME=localhost.localdomain改为HOSTNAME=snn.athrob.com
二、编辑(2)中的这个hosts文件,将其中localhost.localdomain替换为snn.athrob.com
注:保存重启后生效
[2]修改hosts文件,使前面的hostname和IP地址对应起来
仍然编辑(2)中的hosts文件,添加:
192.168.187.128 namenode.athrob.com
192.168.187.129 snn.athrob.com
192.168.187.130 dn1.athrob.com
192.168.187.131 dn2.athrob.com
192.168.187.132 dn3.athrob.com
注:使用hostname访问,避免使用IP地址访问。
0x02 配置ssh免密码登录
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
(1)在NameNode,SecondaryNameNode,DataNode1,DataNode2,DataNode3上配置如下命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
(2)将NameNode上生成的公钥copy到其他四台机器上:
scp ~/.ssh/id_dsa.pub [email protected]:~
注:此命令是将本机的ssh公钥上传到SecondaryNameNode这台机器上。
然后,在SecondaryNameNode上,进入root主目录,ls一下会看到刚才copy的来的这个id_dsa.pub文件
将该文件追加到~/.ssh/authorized_keys文件中:
cat id_dsa.pub >> ~/.ssh/authorized_keys
(3)确认免密码登录成功
在NameNode上输入:ssh [email protected]
如果能直接登录到SecondaryNameNode这台机器上,则说明免密码登录配置成功。
从NameNode上免密码登录到其他DataNode节点上,参考上面步骤。
0x03 配置JDK
设置JAVA环境变量:
cd ~
vi .bash_profile
添加下面三行:
export JAVA_HOME=/opt/jdk1.8.0_92
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
注:其中/opt/jdk1.8.0_92为JDK目录的路径,其它机器配置JAVA环境变量方法一样
0x04 配置Hadoop
假设我的Hadoop目录为:/opt/hadoop-1.2.1
cd /opt/hadoop-1.2.1/conf
该目录下有六个文件需要修改:
hadoop-env.sh、core-site.xml、hdfs-site.xml、masters、slaves、mapred-site.xml
(1)hadoop-env.sh
修改JAVA_HOME的路径
找到JAVA_HOME,修改如下:
export JAVA_HOME=/opt/jdk1.8.0_92
(2)core-site.xml
配置NameNode和Hadoop的工作目录:

(3)hdfs-site.xml
配置Block的副本数:(默认为3,不能大于DataNode的个数)
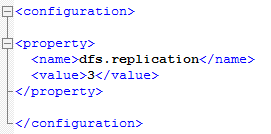
(4)masters
配置SecondaryNameNode:
将local改为:snn.athrob.com
(5)slaves
配置DataNode:
dn1.athrob.com
dn2.athrob.com
dn3.athrob.com
(6)mapred-site.xml
配置JobTracker:

注:NameNode和SecondaryNameNode不能配置为同一台机器。TaskTracker不用配置,因为TaskTracker存在DataNode上。
从NameNode上复制Hadoop这6个配置文件到相应其他节点上的Hadoop配置目录
为了省事,也可以直接copy整个配置目录
scp /opt/hadoop-1.2.1/conf/* [email protected]:/opt/hadoop-1.2.1/conf/
0x05 启动Hadoop
在NameNode上,进入Hadoop目录下的bin目录下:
(1)启动前格式化NameNode
./hadoop namenode -format
(2)启动NameNode,SecondaryNameNode,DataNode,JobTracker,TaskTracker
./start-all.sh
0x06 JobTracker或者其他节点起不来
说明:有的时候虽然说我们在NameNode上执行了./start-all.sh,也看到输出NameNode、SecondaryNameNode、DataNode、JobTracker、TaskTracker启动了。但是jps查看的时候,就是没有相应的进程!
这个时候请关闭Linux的防火墙再重新启动hadoop,应该就可以了!
service iptables stop
或ufw disable
下次准备介绍,在Windows环境下,使用Eclipse编译Hadoop中的eclipse插件。
不足之处,请批评指正。
如有问题,请私信联系。
谢谢!