二、Java正则表达式:
说明:位于Java.util.regex包中类Matcher与Pattern,需要掌握的3个对象是
String,Pattern,Matcher,他们都是final类对象。
其中String的matches()方法表示是否匹配给定的正则表达式对象,
类Pattern表示正则表达式的编译形式(字符串的匹配模式,需编译),
类Mathcher表匹配器。
2.1 Pattern类:
常用方法:
compile(String regex)将给定的正则表达式编译到模式中
返回Pattern编译模式对象
matcher(CharSequence input)表示匹配给定输入与此模式的匹配器
返回Matcher匹配器对象。
2.2 Matcher类:
常用方法:
- matches():表示全字匹配(也就是所有内容进行匹配);String的matchers()用的就是Pattern和Matcher对象来完成的,被String的封装了,使用起来简单,功能较单一;
如果不需要 全字 匹配,需要改用 lookingAt(); - find():将规则作用到字符串上,并进行符合规则的子串查找,匹配指针会下移;
- group():用于获取匹配后的结果
- start() 与 end() : 获取匹配字符串的下标
示例:
String str ="wo shi ge da ben dan.";
String reg ="\\b[a-z]{3}\\b";//查找单词为3个字符的\b表示单词边界
Pattern p =Pattern.compile(reg);//规则封装成对象
Matcher m=p.matcher(str);//让正则对象和要作用的字符串相关联,获取匹配器对象
while(m.find()) {
System.out.print(m.group() +" ");
}
输出为:shi ben dan
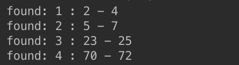
String text = "This is the text which is to be searched for occurrences of the word 'is'.";
String patternString = "is";
Pattern pattern = Pattern.compile(patternString);
matcher = pattern.matcher(text);
int count = 0;
while(matcher.find()) {
count++;
System.out.println("found: " + count + " : " + matcher.start() + " - " + matcher.end());}
输出:
Paste_Image.png
2.3例子Pattern,Matcher:
// 1.正则表达式模式对象
Pattern tPattern = Pattern.compile("[a-z]{3}");
// 2.返回Matcher匹配器对象
Matcher pMatcher = tPattern.matcher("abc");
// 3.是否匹配
System.out.println(pMatcher.matches());
2.4例子认识‘.*?’:
/**认识.*?**/
out("a".matches("."));// '.'匹配所有的单个字符
out("aa".matches("aa"));
out("aaaa".matches("a*"));// '*'表示0或多次
out("aaaa".matches("a+"));// '+'表示一次或多次
out("".matches("a*"));// 'a*'表示'a'出现0或多次
out("".matches("a?"));// 'a?'表示'a'出现0或1次
out("a".matches("a?"));
out("121321312".matches("\\d{3,20}"));
out("192.168.1.172".matches("\\d{1,3}\\.\\d{1,3}\\.\\d{1}\\.\\d{1,3}"));
out("259".matches("[0-2][0-5][0-5]"));// []表示在范围中取一个字符
}
public static void out(Object pObj) {
System.out.println(pObj);
}
2.5例子认识‘[]’表示范围之中:
/**范围[]**/
out("a".matches("[abc]"));
out("a".matches("[^abc]"));// '^'表示取反,不在abc之中
out("A".matches("[a-zA-z]"));// 'a-z'或者'A-Z'范围之中
out("A".matches("[a-z]|[A-Z]"));// '|'表或者,与上类似
out("A".matches("[a-z[A-Z]]"));//与上类似
out("R".matches("[A-Z&&[RFG]]"));//并且在'RFG'之中,取交集
2.5例子认识‘\s, \d, \w, \ ’:
注意: ‘\w ‘表示的范围中不包含’-’符号 也即是字母、数字、下划线三种;
/**认识\s\w\d\**/
out("\n\r\t".matches("\\s{4}"));// '\s'表示空格
out(" ".matches("\\S"));// '\S'表非空格
out("a_4".matches("\\w{3}"));// '\w'表单词字符:[a-zA-Z_0-9]
out("abc123&^%".matches("[a-z]{3}\\d+[&^#%]+"));
out("\\".matches("\\\\"));//匹配'\'
2.6例子边界匹配:
注意: ‘^’在‘[]’中表示取反,而在这里表示的开头的字母
/**边界处理查api**/
out("ncsmsoft company".matches("^n.*"));// '^n'表示以'n'头
out("ncsmsoft company".matches(".*ny$"));// 'y$'表示以'y'尾
// '\b'表示单词边界, 't'是否为单词边界
out("ncsmsoft company".matches("^n[a-z]{1,6}t\\b.*"));
out("ncsmsoftcompany".matches("^n[a-z]{1,20}t\\b.*"));
//空白行,以空格符开头,并且不是换行符,出现0或多次,以换行结尾
out(" \n".matches("^[\\s&&[^\\n]]*\\n$")
2.7例子:Match中的方法matches(),find(),lookingAt()
/**matches,find,lookingAt, start, end**/
Pattern tPattern = Pattern.compile("\\d{3,5}");
String tStr2 ="123-345-55653-33";
Matcher pMatcher = tPattern.matcher(tStr2);
out(pMatcher.matches()); // matches()表示匹配整个字符串
pMatcher.reset();//重置匹配器
out(pMatcher.find());//找子串,匹配的字符串,将被find()吞掉,可以reset()重置
//返回匹配的初始索引和结束之后的索引
out(pMatcher.start() +"-"+ pMatcher.end());//输出0-3
out(pMatcher.find());
out(pMatcher.find());
out(pMatcher.find(12));//重置匹配器,并从指定索引开始的输入序列的下一个子序列
out(pMatcher.lookingAt());//从头找, true
out(pMatcher.lookingAt());// true
2.8例子:Match中的方法替换
/**例子1.replaceAll全部替换**/
Pattern tPattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE);
String tStr3 ="Java java
JAVA jaVA JaVA I like java you hate Java";
Matcher tMatcher = tPattern.matcher(tStr3);
*out*(tMatcher.replaceAll("JAVA"));
/**例子2.奇偶替换appendReplacement()方法和appendTail()方法**/
Patternt pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE);
String tStr3 ="Java java
JAVA jaVA JaVA I like java you hate Java ncsmsoft";
Matchert matcher = tPattern.matcher(tStr3);
StringBuffer tStr4 =new StringBuffer();
int tInt = 0;
while (tMatcher.find()) {
if (tInt % 2 == 0) {//偶数
tMatcher.appendReplacement(tStr4,"java");
}else{//奇数
tMatcher.appendReplacement(tStr4,"JAVA");
}
tInt++;
}
tMatcher.appendTail(tStr4);//将后面的添加进来
out(tStr4);
2.9例子:认识’()’表示对正则表达式分组. Match中的group分组
为了让规则结果重用,可以将规则封装成一个组,用()完成,组的出现都有编号,从1开始,想使用已有的组,可用\n的形式来获取,如\1表示引入第一组;
如要获取组值,则用$n,如$1表示拿到第一个组中的值:
叠字替换:
String str ="abbccddeeff";
str.replaceAll("(.)[\\1]+","$1");//第一组出现多个
将ip字符串解析,并按照网段排序:
String ip ="10.10.10.10
2.2.2.2 192.168.2.3 78.23.56.89 10.11.22.33";
ip= ip.replaceAll("(\\d+)","00$1");//使用分组:每一组的连续数字前补2个0
ip= ip.replaceAll("0*(\\d{3})","$1");//只保留3位数的分组了
String[]arr = ip.split(" +");
TreeSettree = new TreeSet();
for(String str : arr)
{
tree.add(str);
}
for(String str : tree)
{
System.out.println(str.replaceAll("0*(\\d+)","$1"));//还原IP
}
str将变成: abcdef;
/**'()'分组group**/
Pattern tPattern = Pattern.compile("(\\d{3,5})([a-z]{2})")
String tStr4 ="123bd-3434dc-34333dd-00";
Matcher tMatcher =tPattern.matcher(tStr4);
while(tMatcher.find()){
out(tMatcher.group());//拿到所有
out(tMatcher.group(2));//拿到第2组的
}