字符串格式化调用方法 —— format
通过创建字符串模板,利用format函数,替代相应的值。
可以通过绝对位置、相对位置以及关键字进行替代。例如
# 字符串格式化调用方法
template = '{0}, {1} and {2}' # By position
print(template.format('spam', 'ham', 'eggs'))
#spam, ham and eggs
template = '{motto}, {pork} and {food}' # By keyword
print(template.format(motto='spam', pork='ham', food='eggs'))
#spam, ham and eggs
template = '{}, {} and {}' # By relative position
print(template.format('spam', 'ham', 'eggs')) # New in 3.1 and 2.7
#'spam, ham and eggs'
print('{motto}, {0} and {food}'.format(42, motto=3.14, food=[1, 2]))
# 3.14, 42 and [1, 2]
可以看到,food是一个列表,它会根据__str__()进行替代。
格式化调用的高级用途
格式化字符串指定对象属性(点表示)和字典键。例如
print('My {map[kind]} runs {sys.platform}'.format(sys=sys, map={'kind': 'laptop'}))
#My laptop runs win32
形式化结构
{fieldname|conversionflag:formatspec}
- fieldname是指定参数的一个数字或关键字
- conversionflag可以是r、s,或者a,分别是该值上对repr、str或ascii内置函数的一次调用
- formatspce指定了如何表示该值,包括字段宽度、对齐方式、补零、小数点精度等细节,可以表示成
[fill|align][sign][#][0][width][.precision][typecode]
例如align可能是<,>或=,分别表示左对齐、右对齐或居中对齐。
例如
print('{0.platform:>10} = {1[kind]:<10}'.format(sys, dict(kind='laptop')))
# win32 = laptop
print('{0:f}, {1:.2f}, {2:06.2f}'.format(3.14159, 3.14159, 3.14159))
#3.141590, 3.14, 003.14
if/else三元表达式
例子
A = 't' if 'spam' else 'f'
print(A)
#t
迭代器
可迭代对象,基本上,就是序列观念的通用化。
Python中所谓的迭代协议:有__next__方法的对象会前进到下一个结果,而在一系列结果的末尾时,则会引发StopIteration。在Python中,任何这类对象都认为是可迭代的。任何这类对象也能以for循环或其他迭代工具遍历,因为所有迭代工具内部工作起来都是在每次迭代中调用__next__,并且捕捉StopIteration异常来确定合适离开。
L = [1,2,3]
I = iter(L)
print(I.__next__())
#1
print(I.__next__())
#2
print(next(I))
#3
print(next(I))
#Traceback (most recent call last):
#StopIteration
自动迭代和手动迭代
L = [1, 2, 3]
for X in L: # Automatic iteration
print(X ** 2, end=' ') # Obtains iter, calls __next__, catches exceptions
#1 4 9
I = iter(L) # Manual iteration: what for loops usually do
while True:
try: # try statement catches exceptions
X = next(I) # Or call I.__next__ in 3.X
except StopIteration:
break
print(X ** 2, end=' ')
#1 4 9
多个迭代器和单个迭代器
多个迭代器,例如range,它不是自己的迭代器(手动迭代时,需要使用iter产生一个迭代器)。它支持在其结果上的多个迭代器,这些迭代器会记住它们各自的位置。与之相反,例如zip,它不支持多个迭代器。
R = range(3) # range allows multiple iterators
next(R)
#TypeError: 'range' object is not an iterator
I1 = iter(R)
print(next(I1))
#0
print(next(I1))
#1
I2 = iter(R)
print(next(I2))
#0
Z = zip((1, 2, 3), (10, 11, 12))
I1 = iter(Z)
I2 = iter(Z) # Two iterators on one zip
print(next(I1))
#(1, 10)
print(next(I1))
#(2, 11)
print(next(I2)) # (3.X) I2 is at same spot as I1!
#(3, 12)
变量域

内置作用域仅仅是一个名为builtins的内置模块,但是必须要导入(即import builtins)之后才能使用内置作用域。
import builtins
print(dir(builtins))
闭合(closure)或工厂函数
一个能够记住嵌套作用域的变量值的函数,尽管那个作用域已经不存在了。
其实,闭包指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。函数是不是匿名的没有关系,关键是它能访问定义体之外定义的非全局变量。
def maker(N):
def action(X): # Make and return action
return X ** N # action retains N from enclosing scope
return action
f = maker(2)
print(f)
#.action at 0x0000019C3FCE6620>
print(f(3))
#9
这是函数式编程常用的方式。
在大多数情况下,给内层的lambda函数通过默认参数传递值没什么必要。例如
def func1():
x = 4
action = (lambda n: x ** n) # x remembered from enclosing def
return action
def func2():
x = 4
action = (lambda n, x=x: x ** n) # Pass x in manually
return action
f1 = func1()
f2 = func2()
print(f1(2))
#16
print(f2(2))
#16
但是,如果嵌套在一个循环中,并且嵌套的函数引用了一个上层作用域的变量,该变量被循环所改变,所有在这个循环中产生的函数将会有相同的值——在最后一次循环中完成时被引用变量的值。
def makeActions():
acts = []
for i in range(5): # Tries to remember each i
acts.append(lambda x: i ** x) # But all remember same last i!
return acts
acts = makeActions()
print(acts[0](2))
#16
print(acts[1](2))
#16
def makeActions():
acts = []
for i in range(5): # Tries to remember each i
acts.append(lambda x, i=i: i ** x) # But all remember same last i!
return acts
acts = makeActions()
print(acts[0](2))
#0
print(acts[1](2))
#1
例子:average.py:计算移动平均值的高阶函数
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
测试示例
>>> avg = make_averager()
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(12)
11.0

例子:一个简单的装饰器,输出函数的运行时间
import time
def clock(func):
def clocked(*args):
t0 = time.time()
result = func(*args)
elapsed = time.time() - t0
name = func.__name__
arg_str = ', '.join(repr(arg) for arg in args)
print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked
使用 clock 装饰器
import time
from clockdeco import clock
@clock
def snooze(seconds):
time.sleep(seconds)
@clock
def factorial(n):
return 1 if n < 2 else n*factorial(n-1)
if __name__=='__main__':
print('*' * 40, 'Calling snooze(.123)')
snooze(.123)
print('*' * 40, 'Calling factorial(6)')
print('6! =', factorial(6))
输出结果如下
$ python3 clockdeco_demo.py
**************************************** Calling snooze(123)
[0.12405610s] snooze(.123) -> None
**************************************** Calling factorial(6)
[0.00000191s] factorial(1) -> 1
[0.00004911s] factorial(2) -> 2
[0.00008488s] factorial(3) -> 6
[0.00013208s] factorial(4) -> 24
[0.00019193s] factorial(5) -> 120
[0.00026107s] factorial(6) -> 720
6! = 720
上述实现的 clock 装饰器有几个缺点:不支持关键字参数,而且遮盖了被装饰函数的 __name__ 和 __doc__ 属性。我们使用functools.wraps 装饰器把相关的属性从 func 复制到 clocked 中。此外,这个新版还能正确处理关键字参数。
例子:改进后的 clock 装饰器
import time
import functools
def clock(func):
@functools.wraps(func)
def clocked(*args, **kwargs):
t0 = time.time()
result = func(*args, **kwargs)
elapsed = time.time() - t0
name = func.__name__
arg_lst = []
if args:
arg_lst.append(', '.join(repr(arg) for arg in args))
if kwargs:
pairs = ['%s=%r' % (k, w) for k, w in sorted(kwargs.items())]
arg_lst.append(', '.join(pairs))
arg_str = ', '.join(arg_lst)
print('[%0.8fs] %s(%s) -> %r ' % (elapsed, name, arg_str, result))
return result
return clocked
nonlocal语句
nonlocal语句只在一个函数内有意义。当执行nonlocal语句的时候,nonlocal中列出的名称必须在一个嵌套的def中提前定义过,否则将会产生一个错误。
def tester(start):
state = start # Each call gets its own state
def nested(label):
nonlocal state # Remembers state in enclosing scope
print(label, state)
state += 1 # Allowed to change it if nonlocal
return nested
F = tester(0)
F('spam')
#spam 0
F('eggs')
#eggs 1
例子:计算移动平均值的高阶函数,不保存所有历史值,但有
缺陷
def make_averager():
count = 0
total = 0
def averager(new_value):
count += 1
total += new_value
return total / count
return averager
>>> avg = make_averager()
>>> avg(10)
Traceback (most recent call last):
...
UnboundLocalError: local variable 'count' referenced before assignment
问题是,当 count 是数字或任何不可变类型时,count += 1 语句的作用其实与 count = count + 1 一样。因此,我们在 averager 的定义体中为 count 赋值了,这会把 count 变成局部变量。total 变量也受这个问题影响。
之前的示例没遇到这个问题,因为我们没有给 series 赋值,我们只是调用 series.append,并把它传给 sum 和 len。也就是说,我们利用了列表是可变的对象这一事实。
但是对数字、字符串、元组等不可变类型来说,只能读取,不能更新。如果尝试重新绑定,例如 count = count + 1,其实会隐式创建局部变量 count。这样,count 就不是自由变量了,因此不会保存在闭包中。
为了解决这个问题,Python 3 引入了 nonlocal 声明。它的作用是把变量标记为自由变量,即使在函数中为变量赋予新值了,也会变成自由变量。
def make_averager():
count = 0
total = 0
def averager(new_value):
nonlocal count, total
count += 1
total += new_value
return total / count
return averager
标准库中的装饰器
- 使用functools.lru_cache做备忘
functools.lru_cache 是非常实用的装饰器,它实现了备忘(memoization)功能。这是一项优化技术,它把耗时的函数的结果保存起来,避免传入相同的参数时重复计算。
例子:使用缓存实现生成第 n 个斐波纳契数
import functools
#注意,必须像常规函数那样调用 lru_cache。这一行中有一对括号:@functools.lru_cache()。
@functools.lru_cache()
#这里叠放了装饰器:@lru_cache() 应用到 @clock 返回的函数上。
@clock
def fibonacci(n):
if n < 2:
return n
return fibonacci(n-2) + fibonacci(n-1)
fibonacci(6)
#[0.00000000s] fibonacci(0) -> 0
#[0.00000000s] fibonacci(1) -> 1
#[0.00000000s] fibonacci(2) -> 1
#[0.00000000s] fibonacci(3) -> 2
#[0.00000000s] fibonacci(4) -> 3
#[0.00000000s] fibonacci(5) -> 5
#[0.00000000s] fibonacci(6) -> 8
- 单分派泛函数 —— functools.singledispatch
使用@singledispatch 装饰的普通函数会变成泛函数(generic function):根据第一个参数的类型,以不同方式执行相同操作的一组函数。
from decimal import Decimal
from functools import singledispatch
@singledispatch
def fun(arg, verbose=False):
if verbose:
print("Let me just say,", end=" ")
print(arg)
@fun.register(int)
def _(arg, verbose=False):
if verbose:
print("Strength in numbers, eh?", end=" ")
print(arg)
@fun.register(list)
def _(arg, verbose=False):
if verbose:
print("Enumerate this:")
for i, elem in enumerate(arg):
print(i, elem)
@fun.register(float)
@fun.register(Decimal)
def fun_num(arg, verbose=False):
if verbose:
print("Half of your number:", end=" ")
print(arg / 2)
def nothing(arg, verbose=False):
print("Nothing.")
fun.register(type(None), nothing)
fun("Hello, world.")
#Hello, world.
fun("test.", verbose=True)
#Let me just say, test.
fun(42, verbose=True)
#Strength in numbers, eh? 42
fun(['spam', 'spam', 'eggs', 'spam'], verbose=True)
#Enumerate this:
#0 spam
#1 spam
#2 eggs
#3 spam
fun(None)
#Nothing.
fun(1.23)
#0.615
参数化装饰器
创建一个装饰器工厂函数,把参数传给它,返回一个装饰器,然后再把它应用到要装饰的函数上。
例子:参数化clock装饰器(为了简单起见,基于最初实现的clock)
import time
DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}'
#clock 是参数化装饰器工厂函数
def clock(fmt=DEFAULT_FMT):
#decorate 是真正的装饰器
def decorate(func):
#clocked 包装被装饰的函数
def clocked(*_args):
t0 = time.time()
#_result 是被装饰的函数返回的真正结果
_result = func(*_args)
elapsed = time.time() - t0
name = func.__name__
args = ', '.join(repr(arg) for arg in _args)
result = repr(_result)
#这里使用 **locals() 是为了在 fmt 中引用 clocked 的局部变量
print(fmt.format(**locals()))
#clocked 会取代被装饰的函数,因此它应该返回被装饰的函数返回的值
return _result
return clocked
return decorate
@clock('{name}({args}) dt={elapsed:0.3f}s')
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
#snooze(0.123) dt=0.124s
#snooze(0.123) dt=0.124s
#snooze(0.123) dt=0.124s
递归函数
def sumtree(L):
tot = 0
for x in L: # For each item at this level
if not isinstance(x, list):
tot += x # Add numbers directly
else:
tot += sumtree(x) # Recur for sublists
return tot
L = [1, [2, [3, 4], 5], 6, [7, 8]] # Arbitrary nesting
print(sumtree(L)) # Prints 36
函数内省
由于函数是对象,我们可以用常规的对象工具来处理函数。内省工具允许我们探索实现的细节。
def func(a):
b = 'spam'
return b * a
print(func.__name__)
print(dir(func))
reduce函数
它接受一个迭代器来处理,返回一个单个的结果。
from functools import reduce
print(reduce((lambda x, y: x + y), [1, 2, 3, 4]))
#10
def myreduce(function, sequence):
tally = sequence[0]
for next in sequence[1:]:
tally = function(tally, next)
return tally
print(myreduce((lambda x, y: x + y), [1, 2, 3, 4, 5]))
#15
生成器
- 生成器函数
- 生成器表达式
生成器函数
它与常规函数之间的主要代码不同在于,生成器yields一个值,而不是返回一个值。yield语句挂起该函数并向调用者发送回一个值,但是,保留足够的状态以使得函数能够从它离开的地方继续。当继续时,函数在上一个yield返回后立即继续执行。
可迭代的对象定义了一个__next__方法,它要么返回迭代中的下一项,或者引发一个特殊的StopIteration异常来终止迭代。一个对象的迭代器用iter内置函数接收。生成器函数,编写为包含yield语句的def语句,自动地支持迭代协议。
生成器函数和生成器表达式自身都是迭代器,因此是单迭代对象。
包导入模式

类的内省工具
一个简单的内省工具
class AttrDisplay:
"""
Provides an inheritable display overload method that shows
instances with their class names and a name=value pair for
each attribute stored on the instance itself (but not attrs
inherited from its classes). Can be mixed into any class,
and will work on any instance.
"""
def gatherAttrs(self):
attrs = []
for key in sorted(self.__dict__):
attrs.append('%s=%s' % (key, getattr(self, key)))
return ', '.join(attrs)
def __repr__(self):
return '[%s: %s]' % (self.__class__.__name__, self.gatherAttrs())
class TopTest(AttrDisplay):
count = 0
def __init__(self):
self.attr1 = TopTest.count
self.attr2 = TopTest.count+1
TopTest.count += 2
class SubTest(TopTest):
pass
X, Y = TopTest(), SubTest() # Make two instances
print(X) # Show all instance attrs
#[TopTest: attr1=0, attr2=1]
print(Y) # Show lowest class name
#[SubTest: attr1=2, attr2=3]
列出类树中每个对象的属性
显示根据属性所在的类来分组的属性,它遍历了整个类树,在此过程中显示了附加到每个对象上的属性。
它这个遍历继承树:从一个实例的__class__到其类,然后递归地从类的_bases__到其所有超类,一路扫描对象的__dict__。
def tester(listerclass, sept=False):
class Super:
def __init__(self): # Superclass __init__
self.data1 = 'spam' # Create instance attrs
def ham(self):
pass
class Sub(Super, listerclass): # Mix in ham and a __str__
def __init__(self): # Listers have access to self
Super.__init__(self)
self.data2 = 'eggs' # More instance attrs
self.data3 = 42
def spam(self): # Define another method here
pass
instance = Sub() # Return instance with lister's __str__
print(instance) # Run mixed-in __str__ (or via str(x))
if sept: print('-' * 80)
class ListTree:
"""
Mix-in that returns an __str__ trace of the entire class tree and all
its objects' attrs at and above self; run by print(), str() returns
constructed string; uses __X attr names to avoid impacting clients;
recurses to superclasses explicitly, uses str.format() for clarity;
"""
def __attrnames(self, obj, indent):
spaces = ' ' * (indent + 1)
result = ''
for attr in sorted(obj.__dict__):
if attr.startswith('__') and attr.endswith('__'):
result += spaces + '{0}\n'.format(attr)
else:
result += spaces + '{0}={1}\n'.format(attr, getattr(obj, attr))
return result
def __listclass(self, aClass, indent):
dots = '.' * indent
if aClass in self.__visited:
return '\n{0}\n'.format(
dots,
aClass.__name__,
id(aClass))
else:
self.__visited[aClass] = True
here = self.__attrnames(aClass, indent)
above = ''
for super in aClass.__bases__:
above += self.__listclass(super, indent+4)
return '\n{0}\n'.format(
dots,
aClass.__name__,
id(aClass),
here, above,
dots)
def __str__(self):
self.__visited = {}
here = self.__attrnames(self, 0)
above = self.__listclass(self.__class__, 4)
return ''.format(
self.__class__.__name__,
id(self),
here, above)
tester(ListTree)
上述结果显示为
.Sub.spam at 0x000001DE25B91AE8>
.........Super.ham at 0x000001DE25B919D8>
............
........>
........
_ListTree__listclass=
__dict__
__doc__
__module__
__str__
__weakref__
............
........>
....>
>
类接口技术
class Super:
def method(self):
print('in Super.method') # Default behavior
def delegate(self):
self.action() # Expected to be defined
class Inheritor(Super): # Inherit method verbatim
pass
class Replacer(Super): # Replace method completely
def method(self):
print('in Replacer.method')
class Extender(Super): # Extend method behavior
def method(self):
print('starting Extender.method')
Super.method(self)
print('ending Extender.method')
class Provider(Super): # Fill in a required method
def action(self):
print('in Provider.action')
for klass in (Inheritor, Replacer, Extender):
print('\n' + klass.__name__ + '...')
klass().method()
print('\nProvider...')
x = Provider()
x.delegate()
#Inheritor...
#in Super.method
#Replacer...
#in Replacer.method
#Extender...
#starting Extender.method
#in Super.method
#ending Extender.method
#Provider...
#in Provider.action
用户定义迭代器
Python中所有的迭代环境都会先尝试__iter__方法,再尝试__getitem__。
从技术角度来说,迭代环境是通过调用内置函数iter去尝试寻找__iter__方法来实现,而这种方法应该返回一个迭代器对象。如果已经提供了,Python就会重复调用这个迭代器对象的next方法,直到发生StopIteration异常。如果没有找到这类__iter__方法,Python会改用__getitem__机制,就像之前那样通过偏移量重复索引,直到引发InderError异常。
class Squares:
def __init__(self, start, stop): # Save state when created
self.value = start - 1
self.stop = stop
def __iter__(self): # Get iterator object on iter
return self
def __next__(self): # Return a square on each iteration
if self.value == self.stop: # Also called by next built-in
raise StopIteration
self.value += 1
return self.value ** 2
for i in Squares(1,5):
print(i, end=' ')
#1 4 9 16 25
上述的列子里,迭代器对象就是实例self,self里实现了__next__方法。要注意的是__iter__只循环一次,而不是多次。
sq = Squares(1,5)
print([n for n in sq])
#[1, 4, 9, 16, 25]
print([n for n in sq])
#[]
属性引用:__getattr__和__setattr__
__getattr__方法是拦截未定义(不存在)属性点号运算。如果Python可通过其继承树搜索流程找到这个属性,该方法就不会被调用。
class Empty:
def __getattr__(self, attrname): # On self.undefined
if attrname == 'age':
return 40
else:
raise AttributeError(attrname)
X = Empty()
print(X.age)
#40
而__setattr__会拦截所有属性的赋值语句。如果定义了这个方法,self.attr=value会变成self.__setattr__('attr',value)。这一点技巧性很高,因为在__setattr__中对任何self属性做赋值,都会再调用__setattr__,导致了无穷递归循环。如果想要使用这个方法,要确定是通过对属性字典做索引运算来赋值,也就是说,是使用self.__dict__['name'] = x,而不是self.name=x。
class Accesscontrol:
def __setattr__(self, attr, value):
if attr == 'age':
self.__dict__[attr] = value + 10 # Not self.name=val or setattr
else:
raise AttributeError(attr + ' not allowed')
X = Accesscontrol()
X.age = 40
print(X.age)
#50
委托(delegation)
委托通常是以__getattr__钩子方法实现的。
class Wrapper:
def __init__(self, object):
self.wrapped = object # Save object
def __getattr__(self, attrname):
print('Trace: ' + attrname) # Trace fetch
return getattr(self.wrapped, attrname) # Delegate fetch
x = Wrapper([1,2,3])
x.append(4)
#Trace: append
print(x.wrapped)
#[1, 2, 3, 4]
slots实例
将字符串属性名称顺序赋值为特殊的__slots__类属性,能够优化内存和速度性能。
使用slots的时候,实例通常没有一个属性字典。
class C:
__slots__ = ['a', 'b']
X = C()
X.a = 1
print(X.a)
#1
print(X.__dict__)
#AttributeError: 'C' object has no attribute '__dict__'
可以通过在__slots__中包含__dict__,仍然可以容纳额外的属性,从而考虑到一个属性空间字典的需求。下面这个例子中,两种储存机制都用到了。
class D:
__slots__ = ['a', 'b', '__dict__'] # Name __dict__ to include one too
c = 3 # Class attrs work normally
def __init__(self):
self.d = 4 # d stored in __dict__, a is a slot
X = D()
X.a = 1
X.b = 2
print(X.d)
#4
print(X.c)
#3
for attr in list(getattr(X, '__dict__', [])) + getattr(X, '__slots__', []):
print(attr, '=>', getattr(X, attr))
#d => 4
#a => 1
#b => 2
#__dict__ => {'d': 4}
静态方法和类方法
使用类方法统计每个类的实例
class Spam:
numInstances = 0
def count(cls): # Per-class instance counters
cls.numInstances += 1 # cls is lowest class above instance
def __init__(self):
self.count() # Passes self.__class__ to count
count = classmethod(count)
class Sub(Spam):
numInstances = 0
def __init__(self): # Redefines __init__
Spam.__init__(self)
class Other(Spam): # Inherits __init__
numInstances = 0
x = Spam()
y1, y2 = Sub(), Sub()
z1, z2, z3 = Other(), Other(), Other()
print(Spam.numInstances, Sub.numInstances, Other.numInstances)
#1 2 3
异常
异常基础——捕获异常
在try语句内,自行捕捉异常。
def fetcher(obj, index):
return obj[index]
x = 'spam'
def catcher():
try:
fetcher(x, 4)
except IndexError:
print('got exception')
print('continuing')
catcher()
#got exception
#continuing
异常基础——引发异常
要手动触发异常,直接执行raise语句。
try:
raise IndexError
except IndexError:
print('got exception!')
#got exception!
终止行为
try/finally的组合,可以定义一定会在最后执行时的收尾行为,无论try代码块中是否发生了异常。
try:
fetcher(x, 3)
finally:
print('after fetch!')
#after fetch!
try语句分句

with/as环境管理器

文件对象有环境管理器,可在with代码块后自动关闭文件,无论是否引发异常。
with语句实际的工作方式
- 计算表达式,所得到的对象称为环境管理器,它必须有__enter__和__exit__方法。
- 环境管理器的__enter__方法会被调用。如果as子句存在,其返回值会赋值为as子句中的变量,否则直接丢弃。
- 代码块中嵌套的代码会执行。
- 如果with代码块引发异常,__exit__(type, value, traceback)方法就会被调用。如果此方法返回值为假,则异常会重新引发。否则,异常会终止。正常情况下异常是应该被重新引发,这样的话才能传递到with语句之外。
- 如果with代码块没有引发异常,__exit__方法依然会被调用,其type、value以及traceback参数都会以None传递。
class TraceBlock:
def message(self, arg):
print('running ' + arg)
def __enter__(self):
print('starting with block')
return self
def __exit__(self, exc_type, exc_value, exc_tb):
if exc_type is None:
print('exited normally\n')
else:
print('raise an exception! ' + str(exc_type))
return False # Propagate
with TraceBlock() as action:
action.message('test 1')
print('reached')
#starting with block
#running test 1
#reached
#exited normally
内置Exception类
- BaseException—— 异常的顶级根类,它不能由用户定义的类直接继承。
- Exception —— 与应用相关的异常的顶层根超类。这是BaseException的一个直接子类,并且是所有其他内置异常的超类。
管理属性
- __getattr__和__setattr__方法,把未定义的属性获取和所有的属性赋值指向通用的处理器方法
- __getattribute__方法,把所有属性获取都指向一个泛型处理器方法
- property内置函数,把特定属性访问定位到get和set处理器函数,也叫特性
- 描述符协议,把特定属性访问定位到具体任意get和set处理器方法
特性
特性协议允许我们把一个特定属性的get和set操作指向我们提供的函数或方法,使得我们能够插入在属性访问的时候自动运行代码。
class Person:
def __init__(self, name):
self._name = name
@property
def name(self): # name = property(name)
"name property docs"
print('fetch...')
return self._name
@name.setter
def name(self, value): # name = name.setter(name)
print('change...')
self._name = value
@name.deleter
def name(self): # name = name.deleter(name)
print('remove...')
del self._name
bob = Person('Bob Smith') # bob has a managed attribute
print(bob.name) # Runs name getter (name 1)
#fetch...
#Bob Smith
bob.name = 'Robert Smith' # Runs name setter (name 2)
#change...
print(bob.name)
#fetch...
#Robert Smith
描述符
描述符提供了拦截属性访问的一种替代方法。实际上,特性是描述符的一种——从技术上讲,property内置函数只是创建一个特定类型的描述符的一种简化方式,而这种描述符在属性访问时运行方法函数。
从功能上讲,描述符协议允许我们把一个特定属性的get和set操作指向我们提供的一个单独类对象的方法:它们提供了一种方式来插入在访问属性的时候自动运行的代码。
描述符作为独立的类创建,它提供了一种更为通用的解决方案。

class Name:
"name descriptor docs"
def __get__(self, instance, owner):
print('fetch...')
return instance._name
def __set__(self, instance, value):
print('change...')
instance._name = value
def __delete__(self, instance):
print('remove...')
del instance._name
class Person:
def __init__(self, name):
self._name = name
name = Name() # Assign descriptor to attr
bob = Person('Bob Smith') # bob has a managed attribute
print(bob.name) # Runs Name.__get__
#fetch...
#Bob Smith
bob.name = 'Robert Smith' # Runs Name.__set__
#change...
print(bob.name)
#fetch...
#Robert Smith
描述符可以使用实例状态和描述符状态,或者两者的任何组合
- 描述符状态用来管理内部用于描述符工作的数据
- 实例状态记录了和客户类相关的信息
class DescState: # Use descriptor state
def __init__(self, value):
self.value = value
def __get__(self, instance, owner): # On attr fetch
print('DescState get')
return self.value * 10
def __set__(self, instance, value): # On attr assign
print('DescState set')
self.value = value
# Client class
class CalcAttrs:
X = DescState(2) # Descriptor class attr
Y = 3 # Class attr
def __init__(self):
self.Z = 4 # Instance attr
obj = CalcAttrs()
print(obj.X, obj.Y, obj.Z) # X is computed, others are not
#DescState get
#20 3 4
obj.X = 5 # X assignment is intercepted
#DescState set
obj.Y = 6
obj.Z = 7
print(obj.X, obj.Y, obj.Z)
#DescState get
#50 6 7
__getattr__和__getattribute__
属性获取拦截表现为两种形式,可用两种不同的方法来编写:
- __getattr__针对未定义的属性运行
- __getattribute__针对每个属性,因此,当使用它的时候,必须小心避免通过把属性访问传递给超类而导致递归循环

避免属性拦截方法中的循环。要解决这个问题,把获取指向一个更高的超类,而不是跳过这个层级的版本——object类总是一个超类,并且它在这里可以很好地起作用。
def __getattribute__(self, name):
x = object.__getattribute__(self, 'other') # Force higher to avoid me
对于__setattr__,情况是类似的。在这个方法内赋值任何属性,都会再次触发__setattr__并创建一个类似的循环。要解决这个问题,把属性作为实例的__dict__命名空间字典中的一个键赋值。这样就避免了直接的属性赋值。
def __setattr__(self, name, value):
self.__dict__['other'] = value # Use atttr dict to avoid me
尽管这种方法比较少用到,但__setattr__也可以把自己的属性赋值传递给一个更高的超类而避免循环,就像__getattribute__一样。
def __setattr__(self, name, value):
object.__setattr__(self, 'other', value) # Force higher to avoid me
相反,我们不能使用__dict__技巧在__getattribute__中避免循环。
def __getattribute__(self, name):
x = self.__dict__['other'] # LOOPS!
获取__dict__属性本身会再次触发__getattribute__,导致一个递归循环。很奇怪,但确实如此。
例子:比较两种get方法
class GetAttr:
attr1 = 1
def __init__(self):
self.attr2 = 2
def __getattr__(self, attr): # On undefined attrs only
print('get: ' + attr) # Not on attr1: inherited from class
if attr == 'attr3': # Not on attr2: stored on instance
return 3
else:
raise AttributeError(attr)
X = GetAttr()
print(X.attr1)
#1
print(X.attr2)
#2
print(X.attr3)
#get: attr3
#3
print('-' * 20)
class GetAttribute(object): # (object) needed in 2.X only
attr1 = 1
def __init__(self):
self.attr2 = 2
def __getattribute__(self, attr): # On all attr fetches
print('get: ' + attr) # Use superclass to avoid looping here
if attr == 'attr3':
return 3
else:
return object.__getattribute__(self, attr)
X = GetAttribute()
print(X.attr1)
#get: attr1
#1
print(X.attr2)
#get: attr2
#2
print(X.attr3)
#get: attr3
#3
示例:属性验证
- 方法一:使用特性来验证
要理解这段代码,关键是要注意到,__init__构造函数方法内部的属性赋值也触发了特性的setter方法。例如,当这个方法分配给self.name时,它自动调用setName方法,该方法转换值并将其赋给一个叫做__name的实例属性,以便它不会与特性的名称冲突。
class CardHolder:
acctlen = 8 # Class data
retireage = 59.5
def __init__(self, acct, name, age, addr):
self.acct = acct # Instance data
self.name = name # These trigger prop setters too!
self.age = age # __X mangled to have class name
self.addr = addr # addr is not managed
# remain has no data
def getName(self):
return self.__name
def setName(self, value):
value = value.lower().replace(' ', '_')
self.__name = value
name = property(getName, setName)
def getAge(self):
return self.__age
def setAge(self, value):
if value < 0 or value > 150:
raise ValueError('invalid age')
else:
self.__age = value
age = property(getAge, setAge)
def getAcct(self):
return self.__acct[:-3] + '***'
def setAcct(self, value):
value = value.replace('-', '')
if len(value) != self.acctlen:
raise TypeError('invald acct number')
else:
self.__acct = value
acct = property(getAcct, setAcct)
def remainGet(self): # Could be a method, not attr
return self.retireage - self.age # Unless already using as attr
remain = property(remainGet)
def printholder(who):
print(who.acct, who.name, who.age, who.remain, who.addr, sep=' / ')
bob = CardHolder('1234-5678', 'Bob Smith', 40, '123 main st')
printholder(bob)
#12345*** / bob_smith / 40 / 19.5 / 123 main st
bob.name = 'Bob Q. Smith'
bob.age = 50
bob.acct = '23-45-67-89'
printholder(bob)
#23456*** / bob_q._smith / 50 / 9.5 / 123 main st
sue = CardHolder('5678-12-34', 'Sue Jones', 35, '124 main st')
printholder(sue)
#56781*** / sue_jones / 35 / 24.5 / 124 main st
try:
sue.age = 200
except:
print('Bad age for Sue')
#Bad age for Sue
try:
sue.remain = 5
except:
print("Can't set sue.remain")
#Can't set sue.remain
try:
sue.acct = '1234567'
except:
print('Bad acct for Sue')
#Bad acct for Sue
方法二:使用描述符验证
要理解这段代码,注意__init__构造函数方法内部的属性赋值触发了描述符的__set__操作符方法,这一点还是很重要。例如,当构造函数方法分配给self.name时,它自动调用Name.__set__()方法,该方法转换值,并且将其赋给了叫做name的一个描述符属性。
class CardHolder:
acctlen = 8 # Class data
retireage = 59.5
def __init__(self, acct, name, age, addr):
self.acct = acct # Instance data
self.name = name # These trigger __set__ calls too!
self.age = age # __X not needed: in descriptor
self.addr = addr # addr is not managed
# remain has no data
class Name(object):
def __get__(self, instance, owner): # Class names: CardHolder locals
return self.name
def __set__(self, instance, value):
value = value.lower().replace(' ', '_')
self.name = value
name = Name()
class Age(object):
def __get__(self, instance, owner):
return self.age # Use descriptor data
def __set__(self, instance, value):
if value < 0 or value > 150:
raise ValueError('invalid age')
else:
self.age = value
age = Age()
class Acct(object):
def __get__(self, instance, owner):
return self.acct[:-3] + '***'
def __set__(self, instance, value):
value = value.replace('-', '')
if len(value) != instance.acctlen: # Use instance class data
raise TypeError('invald acct number')
else:
self.acct = value
acct = Acct()
class Remain(object):
def __get__(self, instance, owner):
return instance.retireage - instance.age # Triggers Age.__get__
def __set__(self, instance, value):
raise TypeError('cannot set remain') # Else set allowed here
remain = Remain()
def printholder(who):
print(who.acct, who.name, who.age, who.remain, who.addr, sep=' / ')
bob = CardHolder('1234-5678', 'Bob Smith', 40, '123 main st')
printholder(bob)
#12345*** / bob_smith / 40 / 19.5 / 123 main st
bob.name = 'Bob Q. Smith'
bob.age = 50
bob.acct = '23-45-67-89'
printholder(bob)
#23456*** / bob_q._smith / 50 / 9.5 / 123 main st
sue = CardHolder('5678-12-34', 'Sue Jones', 35, '124 main st')
printholder(sue)
#56781*** / sue_jones / 35 / 24.5 / 124 main st
try:
sue.age = 200
except:
print('Bad age for Sue')
#Bad age for Sue
try:
sue.remain = 5
except:
print("Can't set sue.remain")
#Can't set sue.remain
try:
sue.acct = '1234567'
except:
print('Bad acct for Sue')
#Bad acct for Sue
**方法三:使用__getattr__来验证
对于这个例子的特性和描述符版本,注意__init__构造函数方法中的属性赋值触发了类的__setattr__方法,这还是很关键的。例如,当这个方法分配给self.name时,它自动地调用__setattr__方法,该方法转换值,并将其分配给一个名为name的实例属性。通过在该实例上存储name,它确保了未来的访问不会触发__getattr__。相反,acct存储为_acct,因此随后对acct的访问会调用__getattr__。
class CardHolder:
acctlen = 8 # Class data
retireage = 59.5
def __init__(self, acct, name, age, addr):
self.acct = acct # Instance data
self.name = name # These trigger __setattr__ too
self.age = age # _acct not mangled: name tested
self.addr = addr # addr is not managed
# remain has no data
def __getattr__(self, name):
if name == 'acct': # On undefined attr fetches
return self._acct[:-3] + '***' # name, age, addr are defined
elif name == 'remain':
return self.retireage - self.age # Doesn't trigger __getattr__
else:
raise AttributeError(name)
def __setattr__(self, name, value):
if name == 'name': # On all attr assignments
value = value.lower().replace(' ', '_') # addr stored directly
elif name == 'age': # acct mangled to _acct
if value < 0 or value > 150:
raise ValueError('invalid age')
elif name == 'acct':
name = '_acct'
value = value.replace('-', '')
if len(value) != self.acctlen:
raise TypeError('invald acct number')
elif name == 'remain':
raise TypeError('cannot set remain')
self.__dict__[name] = value # Avoid looping (or via object)
方法四:使用__getattribute__验证
注意,由于每个属性获取都指向了__getattribute__,所以这里我们不需要压缩名称以拦截它们(acct存储为acct)。另一方面,这段代码必须负责把未压缩的属性获取指向一个超类以避免循环。
class CardHolder:
acctlen = 8 # Class data
retireage = 59.5
def __init__(self, acct, name, age, addr):
self.acct = acct # Instance data
self.name = name # These trigger __setattr__ too
self.age = age # acct not mangled: name tested
self.addr = addr # addr is not managed
# remain has no data
def __getattribute__(self, name):
superget = object.__getattribute__ # Don't loop: one level up
if name == 'acct': # On all attr fetches
return superget(self, 'acct')[:-3] + '***'
elif name == 'remain':
return superget(self, 'retireage') - superget(self, 'age')
else:
return superget(self, name) # name, age, addr: stored
def __setattr__(self, name, value):
if name == 'name': # On all attr assignments
value = value.lower().replace(' ', '_') # addr stored directly
elif name == 'age':
if value < 0 or value > 150:
raise ValueError('invalid age')
elif name == 'acct':
value = value.replace('-', '')
if len(value) != self.acctlen:
raise TypeError('invald acct number')
elif name == 'remain':
raise TypeError('cannot set remain')
self.__dict__[name] = value # Avoid loops, orig names
装饰器
装饰是为函数和类指定管理代码的一种方式。装饰器本身的形式是处理其他的可调用对象的可调用的对象(如函数)。
- 函数装饰器
- 类装饰器
简而言之,装饰器提供了一种方法,在函数和类定义语句的末尾插入自动运行代码——对于函数装饰器,在def的末尾;对于类装饰器,在class的末尾。这样的代码可以扮演不同的角色。
管理函数和类
- 函数装饰器也可以用来管理函数对象,而不是随后对它们的调用——例如,把一个函数注册到一个API。
- 类装饰器也可以用来直接管理类对象,而不是实例创建调用——例如,用新的方法扩展类。
为了支持函数和方法,嵌套函数的替代方法工作得更好。

Python何时执行装饰器
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行。这通常是在导入时(即 Python 加载模块时)。
例子:registration.py 模块
registry = [] # registry will hold references to functions decorated by @register.
def register(func): # register takes a function as argument.
print('running register(%s)' % func)
registry.append(func)
return func
@register
def f1():
print('running f1()')
@register
def f2():
print('running f2()')
def f3():
print('running f3()')
def main(): # main displays the registry, then calls f1(), f2(), and f3().
print('running main()')
print('registry ->', registry)
f1()
f2()
f3()
if __name__=='__main__':
main()
把 registration.py 当作脚本运行得到的输出如下
$ python3 registration.py
running register()
running register()
running main()
registry -> [, ]
running f1()
running f2()
running f3()
如果导入 registration.py 模块(不作为脚本运行),输出如下
>>> import registration
running register()
running register()
函数装饰器在导入模块时立即执行,而被装饰的函数只在明确调用时运行。这突出了 Python 程序员所说的导入时和运行时之间的区别。
用bisect来管理已排序的序列
bisect 模块包含两个主要函数,bisect 和 insort,两个函数都利用二分查找算法来在有序序列中查找或插入元素。
例子:在有序序列中用 bisect 查找某个元素的插入位置
import bisect
HAYSTACK = [1, 4, 5, 6, 8, 12, 15, 20, 21, 23, 23, 26, 29, 30]
NEEDLES = [0, 1, 2, 5, 8, 10, 22, 23, 29, 30, 31]
ROW_FMT = '{0:2d} @ {1:2d} {2}{0:<2d}'
def demo(bisect_fn):
for needle in reversed(NEEDLES):
# 用特定的 bisect 函数来计算元素应该出现的位置。
position = bisect_fn(HAYSTACK, needle)
# 利用该位置来算出需要几个分隔符号。
offset = position * ' |'
# 把元素和其应该出现的位置打印出来。
print(ROW_FMT.format(needle, position, offset))
bisect_fn = bisect.bisect
#把选定的函数在抬头打印出来。
print('DEMO:', bisect_fn.__name__)
print('haystack ->', ' '.join('%2d' % n for n in HAYSTACK))
demo(bisect_fn)
#DEMO: bisect
#haystack -> 1 4 5 6 8 12 15 20 21 23 23 26 29 30
#31 @ 14 | | | | | | | | | | | | | |31
#30 @ 14 | | | | | | | | | | | | | |30
#29 @ 13 | | | | | | | | | | | | |29
#23 @ 11 | | | | | | | | | | |23
#22 @ 9 | | | | | | | | |22
#10 @ 5 | | | | |10
# 8 @ 5 | | | | |8
# 5 @ 3 | | |5
# 2 @ 1 |2
# 1 @ 1 |1
# 0 @ 0 0
bisect 函数其实是 bisect_right 函数的别名,后者还有个姊妹函数叫 bisect_left。它们的区别在于,bisect_left 返回的插入位置是原序列中跟被插入元素相等的元素的位置,也就是新元素会被放置于它相等的元素的前面,而 bisect_right 返回的则是跟它相等的元素之后的位置。
bisect 可以用来建立一个用数字作为索引的查询表格,比如说把分数
和成绩。
def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
i = bisect.bisect(breakpoints, score)
return grades[i]
print([grade(score) for score in [33, 99, 77, 70, 89, 90, 100]])
#['F', 'A', 'C', 'C', 'B', 'A', 'A']
排序很耗时,因此在得到一个有序序列之后,我们最好能够保持它的有序。bisect.insort 就是为了这个而存在的。insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq的升序顺序。
例子:insort 可以保持有序序列的顺序
import random
SIZE = 7
random.seed(1729)
my_list = []
for i in range(SIZE):
new_item = random.randrange(SIZE*2)
bisect.insort(my_list, new_item)
print('%2d ->' % new_item, my_list)
#10 -> [10]
# 0 -> [0, 10]
# 6 -> [0, 6, 10]
# 8 -> [0, 6, 8, 10]
# 7 -> [0, 6, 7, 8, 10]
# 2 -> [0, 2, 6, 7, 8, 10]
#10 -> [0, 2, 6, 7, 8, 10, 10]
数组
如果我们需要一个只包含数字的列表,那么 array.array 比 list 更高效。数组支持所有跟可变序列有关的操作,包括 .pop、.insert 和.extend。另外,数组还提供从文件读取和存入文件的更快的方法,如.frombytes 和 .tofile。
from array import array
floats = array('d', (random.random() for i in range(10**7)))
print(floats[-1])
#0.5963321947530882
内存视图
memoryview 是一个内置类,它能让用户在不复制内容的情况下操作同一个数组的不同切片。
>>> numbers = array.array('h', [-2, -1, 0, 1, 2])
>>> memv = memoryview(numbers)
>>> len(memv)
5
>>> memv[0]
-2
>>> memv_oct = memv.cast('B')
>>> memv_oct.tolist()
[254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
>>> memv_oct[5] = 4
队列
collections.deque 类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。而且如果想要有一种数据类型来存放“最近用到的几个元素”,deque 也是一个很好的选择。
>>> from collections import deque
>>> dq = deque(range(10), maxlen=10)
>>> dq
deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.rotate(3)
>>> dq
deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
>>> dq.rotate(-4)
>>> dq
deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
>>> dq.appendleft(-1)
>>> dq
deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.extend([11, 22, 33])
>>> dq
deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
>>> dq.extendleft([10, 20, 30, 40])
>>> dq
deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)
可散列的数据类型
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现__hash__() 方法。另外可散列对象还要有__qe__() 方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的。
原子不可变数据类型(str、bytes 和数值类型)都是可散列类
型,frozenset 也是可散列的。元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。
处理字典中找不到的键
- 利用setdefault
my_dict.setdefault(key, []).append(new_value)
相当于
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
- 利用defaultdict
from collections import defaultdict
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = defaultdict(list)
for k, v in s:
d[k].append(v)
print(sorted(d.items()))
#[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]
所有的映射类型在处理找不到的键的时候,都会牵扯到__missing__方法。
例子:当有非字符串的键被查找的时候,StrKeyDict0 是如何
在该键不存在的情况下,把它转换为字符串的
class StrKeyDict0(dict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys()
>>> d = StrKeyDict0([('2', 'two'), ('4', 'four')])
>>> d['2']
'two'
>>> d[1]
Traceback (most recent call last):
...
KeyError: '1'
>>> d.get('2')
'two'
>>> d.get(4)
'four'
>>> d.get(1, 'N/A')
'N/A'
>>> 2 in d
True
>>> 1 in d
False
字典的变种
- collections.OrderedDict
- collections.ChainMap —— 该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。
import builtins
pylookup = ChainMap(locals(), globals(), vars(builtins))
- collections.Counter —— 这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。
>>> ct = collections.Counter('abracadabra')
>>> ct
Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.update('aaaaazzz')
>>> ct
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.most_common(2)
[('a', 10), ('z', 3)]
- collections.UserDict —— 更倾向于从 UserDict 而不是从 dict 继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题。
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item
不可变映射类型:MappingProxyType
types 模块中引入了一个封装类名叫MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
>>> from types import MappingProxyType
>>> d = {1: 'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'})
>>> d_proxy[1]
'A'
>>> d_proxy[2] = 'x'
Traceback (most recent call last):
File "", line 1, in
TypeError: 'mappingproxy' object does not support item assignment
>>> d[2] = 'B'
>>> d_proxy
mappingproxy({1: 'A', 2: 'B'})
>>> d_proxy[2]
'B'
获取关于函数参数的信息
使用 inspect 模块
例子:clip函数
def clip(text, max_len=80):
"""Return text clipped at the last space before or after max_len
"""
end = None
if len(text) > max_len:
space_before = text.rfind(' ', 0, max_len)
if space_before >= 0:
end = space_before
else:
space_after = text.rfind(' ', max_len)
if space_after >= 0:
end = space_after
if end is None: # no spaces were found
end = len(text)
return text[:end].rstrip()
from inspect import signature
sig = signature(clip)
print(sig)
#(text, max_len=80)
for name, param in sig.parameters.items():
print(param.kind, ':', name, '=', param.default)
#POSITIONAL_OR_KEYWORD : text =
#POSITIONAL_OR_KEYWORD : max_len = 80
支持函数式编程的包——operator模块
Python 的目标不是变成函数式编程语言,但是得益于operator和functools等包的支持,函数式编程风格也可以信手拈来。
operator 模块为多个算术运算符提供了对应的函数。
例子:使用 reduce 和 operator.mul 函数计算阶乘
from functools import reduce
from operator import mul
def fact(n):
return reduce(mul, range(1, n+1))
operator 模块中还有一类函数,能替代从序列中取出元素或读取对象
属性的 lambda 表达式:因此,itemgetter 和 attrgetter 其实会自行构建函数。
例子:使用 itemgetter 排序一个元组列表
metro_data = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
from operator import itemgetter
for city in sorted(metro_data, key=itemgetter(1)):
print(city)
#('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833))
#('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889))
#('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
#('Mexico City', 'MX', 20.142, (19.433333, -99.133333))
#('New York-Newark', 'US', 20.104, (40.808611, -74.020386))
methodcaller它的作用与 attrgetter 和 itemgetter 类似,它会自行创建函数。methodcaller 创建的函数会在对象上调用参数指定的方法。
>>> from operator import methodcaller
>>> s = 'The time has come'
>>> upcase = methodcaller('upper')
>>> upcase(s)
'THE TIME HAS COME'
>>> hiphenate = methodcaller('replace', ' ', '-')
>>> hiphenate(s)
'The-time-has-come'
支持函数式编程的包——functools模块
functools 模块提供了一系列高阶函数,其中最为人熟知的或许是
reduce。
functools.partial 这个高阶函数用于部分应用一个函数。部分应用是指,基于一个函数创建一个新的可调用对象,把原函数的某些参数固定。使用这个函数可以把接受一个或多个参数的函数改编成需要回调的API,这样参数更少。
>>> from operator import mul
>>> from functools import partial
>>> triple = partial(mul, 3)
>>> triple(7)
21
>>> list(map(triple, range(1, 10)))
[3, 6, 9, 12, 15, 18, 21, 24, 27]
classmethod与staticmethod
classmethod 最常见的用途是定义备选构造方法。staticmethod静态方法就是普通的函数,只是碰巧在类的定义体中,而不是在模块层定义。
标准库中的抽象基类
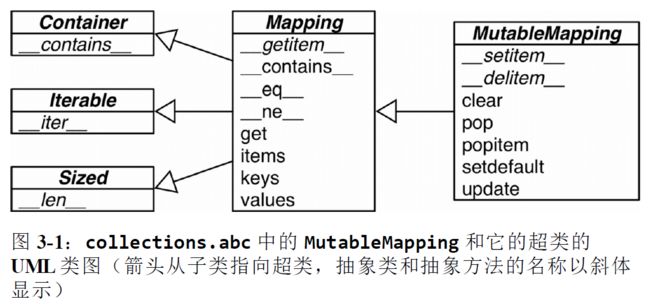
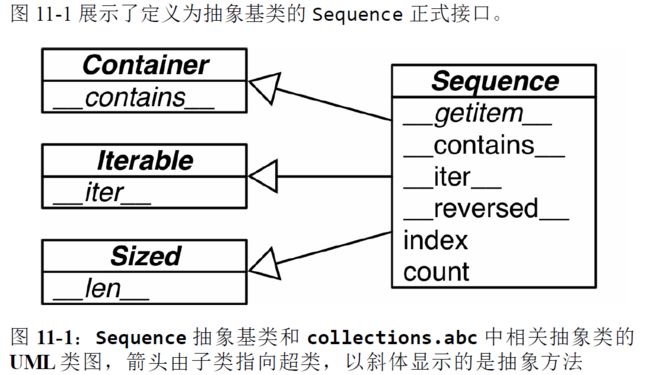
ABC中的抽象基类
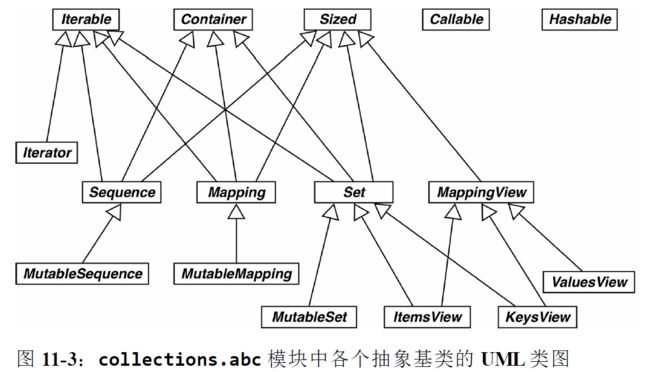
抽象基类的数字塔——numbers包
其中 Number 是位于最顶端的超类,随后是 Complex 子类,依次往下,最底端是 Integral类:
- Number
- Complex
- Real
- Rational
- Integral
如果想检查一个数是不是整数,可以使用 isinstance(x, numbers.Integral),这样代码就能接受 int、bool(int 的子类)
接口:从协议到抽象基类
接口在动态类型语言中是怎么运作的呢?首先,基本的事实是,Python语言没有 interface 关键字,而且除了抽象基类,每个类都有接口:类实现或继承的公开属性(方法或数据属性),包括特殊方法,如__getitem__ 或 __add__。
协议是接口,但不是正式的(只由文档和约定定义),因此协议不能像正式接口那样施加限制。
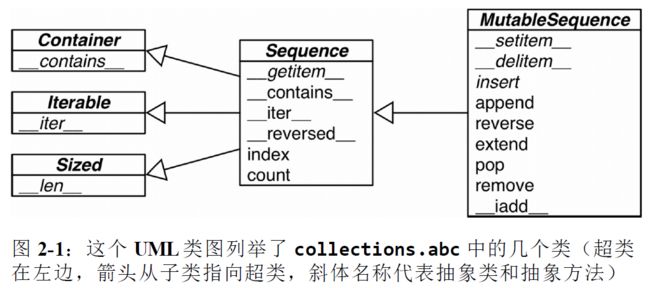
序列协议是 Python 最基础的协议之一。即便对象只实现了那个协议最基本的一部分,解释器也会负责任地处理。
这里简单介绍序列接口的情况。
示例中的 Foo 类。它没有继承 abc.Sequence,而且只实现了序列协议的一个方法:__getitem__ (没有实现 __len__ 方法)。
例子:定义 __getitem__ 方法,只实现序列协议的一部分,这样足够访问元素、迭代和使用 in 运算符了。
class Foo:
def __getitem__(self, pos):
return range(0, 30, 10)[pos]
f = Foo()
for i in f:
print(i)
#0
#10
#20
print(20 in f)
#True
虽然没有 __iter__ 方法,但是 Foo 实例是可迭代的对象,因为发现有__getitem__ 方法时,Python 会调用它,传入从 0 开始的整数索引,尝试迭代对象(这是一种后备机制)。尽管没有实现 __contains__ 方法,但是 Python 足够智能,能迭代 Foo 实例,因此也能使用 in 运算符:Python 会做全面检查,看看有没有指定的元素。
综上,鉴于序列协议的重要性,如果没有 __iter__ 和 __contains__方法,Python 会调用 __getitem__ 方法,设法让迭代和 in 运算符可用。
另一个例子:实现序列协议的 FrenchDeck 类
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
猴子补丁
上述FrenchDeck 类有个重大缺陷:无法洗牌。
>>> from random import shuffle
>>> from frenchdeck import FrenchDeck
>>> deck = FrenchDeck()
>>> shuffle(deck)
Traceback (most recent call last):
File "", line 1, in
File ".../python3.3/random.py", line 265, in shuffle
x[i], x[j] = x[j], x[i]
TypeError: 'FrenchDeck' object does not support item assignment
因为,shuffle 函数要调换集合中元素的位置,而 FrenchDeck 只实现了不可变的序列协议。可变的序列还必须提供 __setitem__ 方法。
例子:为FrenchDeck 打猴子补丁,把它变成可变的,让
random.shuffle 函数能处理
from random import shuffle
deck = FrenchDeck()
def set_card(deck, position, card):
deck._cards[position] = card
FrenchDeck.__setitem__ = set_card
shuffle(deck)
print(deck[:5])
#[Card(rank='2', suit='spades'), Card(rank='9', suit='spades'), Card(rank='9', suit='hearts'), Card(rank='5', suit='diamonds'), Card(rank='3', suit='clubs')]
这里的关键是,set_card 函数要知道 deck 对象有一个名为 _cards 的属性,而且 _cards 的值必须是可变序列。然后,我们把 set_card 函数赋值给特殊方法 __setitem__,从而把它依附到 FrenchDeck 类上。这种技术叫猴子补丁:在运行时修改类或模块,而不改动源码。
白鹅类型
白鹅类型指,只要 cls 是抽象基类,即 cls 的元类是abc.ABCMeta,就可以使用 isinstance(obj, cls)。
其实,抽象基类的本质就是几个特殊方法。
然而,即便是抽象基类,也不能滥用 isinstance 检查,用得多了可能导致代码异味,即表明面向对象设计得不好。在一连串 if/elif/elif中使用 isinstance 做检查,然后根据对象的类型执行不同的操作,通常是不好的做法;此时应该使用多态,即采用一定的方式定义类,让解释器把调用分派给正确的方法,而不使用 if/elif/elif 块硬编码分派逻辑。
定义抽象基类的子类。例子:FrenchDeck2,collections.MutableSequence的子类
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck2(collections.MutableSequence):
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
#为了支持洗牌,只需实现__setitem__方法
def __setitem__(self, position, value):
self._cards[position] = value
#但是继承MutableSequence的类必须实现__delitem__方法,这是MutableSequence 类的一个抽象方法。
def __delitem__(self, position):
del self._cards[position]
#此外,还要实现insert方法,这是MutableSequence类的第三个抽象方法。
def insert(self, position, value):
self._cards.insert(position, value)
参考文献
- Python学习手册
- Python Cookbook
- Fluent Python