目录:
Report B1——采集川大公管学院新闻动态信息
1.确定采集内容
2.创建爬取项目
3.定义spider
3.1编写item.py文件
3.2本地编写spiders文件并上传
4.执行爬虫并保存数据
Report B2——采集川大公管学院全职教师信息
5.总结
Report B1——采集川大公管学院新闻动态信息
1.确定采集内容
在进行一项采集任务的时候,我们不能一开始就写代码吧(当然,你想先搭个基本的框架还是可以的)但是要实现内容的爬取,你总不能随便写个路径去爬取吧,所以,首先,你就得明确要爬取的内容,分析网页的内容:
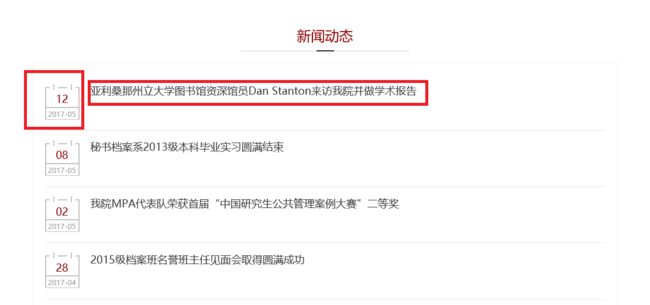
分页列表:

可知,这个爬取的内容涉及到了分页的问题,初步设想是我们需要得到下一页的链接和每一项的链接。
新闻内容详情页:
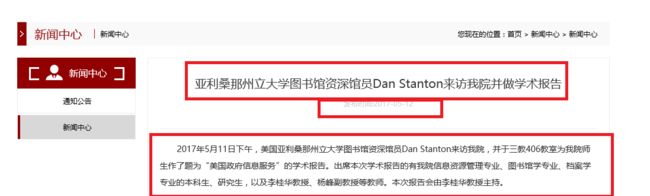
所以,确定采集内容为:标题(title),日期(date),具体内容(details)。
2.创建爬取项目(news为项目名称)
3.定义spider
3.1编写item.py文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
date = scrapy.Field()
details = scrapy.Field()
3.2本地编写spiders文件并上传(因为我期间改了很多次代码,这里只展示了最终版本,关于分页以及页面地址传值的内容已注释在代码之中)
import scrapy
from news.items import NewsItem
class NewsSpider(scrapy.Spider):
"""
name:scrapy唯一定位实例的属性,必须唯一
allowed_domains:允许爬取的域名列表,不设置表示允许爬取所有
start_urls:起始爬取列表
start_requests:它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入
我们自定义的规律的链接
parse:回调函数,处理response并返回处理后的数据和需要跟进的url
"""
# 设置name
name = "nspider"
# 设定域名
allowed_domains = ["ggglxy.scu.edu.cn"]
# 填写爬取地址
start_urls = [
'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1',
]
def parse(self,response):
for href in response.xpath("//ul[@class='newsinfo_list_ul mobile_dn']/li/div/div[@class='news_c fr']/h3/a/@href"):
url = response.urljoin(href.extract())
## 将得到的页面地址传送给单个页面处理函数进行处理 -> parse_details()
yield scrapy.Request(url,callback=self.parse_details)
## 是否还有下一页,如果有的话,则继续
next_page=response.xpath("//div[@class='pager cf tr pt10 pb10 mt30 mobile_dn']/li[last()-1]/a/@href").extract_first()
if next_page is not None:
next_pages = response.urljoin(next_page)
## 将 「下一页」的链接传递给自身,并重新分析
yield scrapy.Request(next_pages, callback = self.parse)
# 编写爬取方法
def parse_details(self, response):
#for line in response.xpath("//ul[@class='newsinfo_list_ul mobile_dn']"):
# 初始化item对象保存爬取的信息
item = NewsItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract()
item['details'] = response.xpath("//div[@class='detail_zy_c pb30 mb30']/p/span/text()").extract()
yield item
参考链接:
SCRAPY爬虫框架入门实例(一)
Scrapy 学习笔记 -- 解决分页爬取的问题
XPath教程
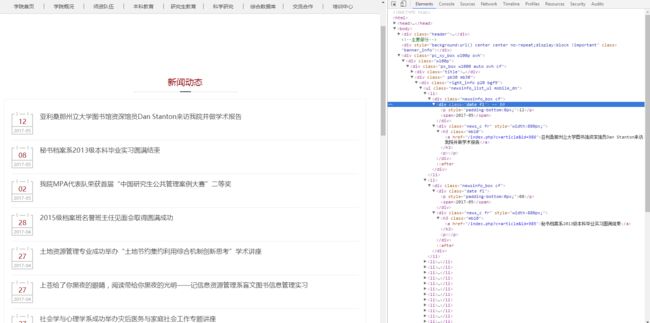
注:在路径的选择时可以采用开发者工具查看网页源码:
4.执行爬虫并保存数据
刚开始执行代码的过程中,出现了一些问题,第一个问题是:
SyntaxError: invalid syntax

表示的意思是其中有中文的输入,按照提示信息,仔细查看news.py文件中的第23行,发现我的单引号是在中文模式下输入的,是说怎么打出来的时候显示出来的感觉很奇怪,在修改了之后又遇到了第二个问题:
IndentationError: unexpected indent
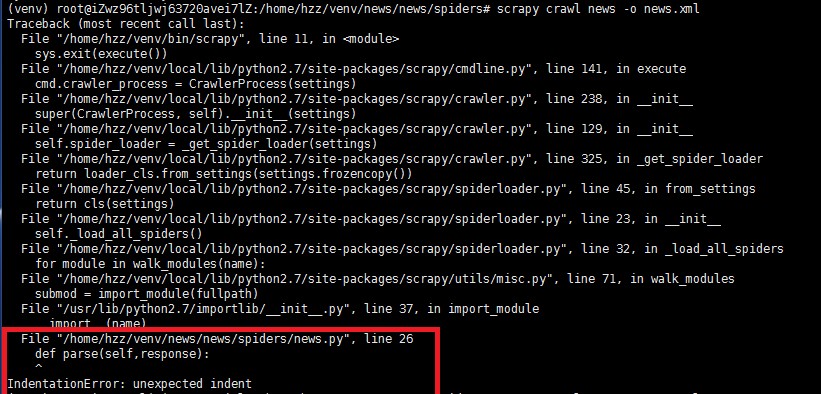
表示的意思是缩进的问题,python是一种对缩进非常敏感的语言,最常见的情况是tab和空格的混用会导致错误,或者缩进不对,我使用的就是最笨的办法,就是一行一行的重新调整。
还出现过:
ImportError: No module named items
这个错误,百度出来说是spiders 目录中的.py文件不能和项目名同名。后来仔细看了一下,发现我确实出现了这个问题,我的项目名称是news,我的spiders 目录中的.py文件也是news.py,这就出现了同名的情况,后来我把.py文件的名字改成了spidernews.py,虽然名字比较长,但是比较直观。
当然,最难的问题是路径的选择,但是由于在做的过程中没有进行记录,而且对于不同的采集任务涉及到的路径选择问题也是不同的,所以也就没有必要进行举例了。一定要记得路径一定要选对!!!
在所有错误解决之后,执行爬虫,保存json文件,执行代码:
scrapy crawl nspider -o news.json
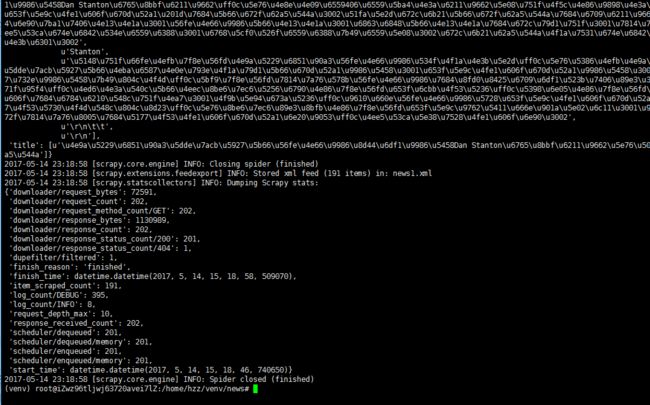
但是一开始保存下来的文件显示不是中文,如图所示:

这是因为,为了更好的传输中文,json进行了Unicode编码。这样一来,我们在解析json之前,就得要先将json数据中的Unicode编码转换为我们使用的中文。有同学反映她们也遇到了这个问题,就尝试了她们说的百度到的方法,执行代码:
scrapy crawl nspider -o news.json -s FEED_EXPORT_ENCODING=utf-8
来实现输出的json格式文件直接显示中文。
参考链接:Scrapy 爬取中文内容后的编码问题
或者在执行爬虫之前在settings.py文件代码行
SPIDER_MODULES = ['news.spiders']
NEWSPIDER_MODULE = 'news.spiders'
之后添加以下代码:
FEED_EXPORT_ENCODING = 'utf-8'
即
SPIDER_MODULES = ['news.spiders']
NEWSPIDER_MODULE = 'news.spiders'
FEED_EXPORT_ENCODING = 'utf-8'
参考链接:Unicode编码转为中文
最后得到理想的结果,一共191条数据。部分截图如下:


Report B2——采集川大公管学院全职教师信息
采集的内容是:教师姓名,职位,简介。
思路同采集新闻动态信息的思路一样。
spiderteachers.py
import scrapy
from teachers.items import TeachersItem
class TeachersSpider(scrapy.Spider):
"""
name:scrapy唯一定位实例的属性,必须唯一
allowed_domains:允许爬取的域名列表,不设置表示允许爬取所有
start_urls:起始爬取列表
start_requests:它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入
我们自定义的规律的链接
parse:回调函数,处理response并返回处理后的数据和需要跟进的url
"""
# 设置name
name = "tspider"
# 设定域名
allowed_domains = ["ggglxy.scu.edu.cn"]
# 填写爬取地址
start_urls = [
'http://ggglxy.scu.edu.cn/index.php?c=article&a=type&tid=18&page_1_page=1',
]
def parse(self,response):
for href in response.xpath("//div[@class='l fl']/a/@href"):
url = response.urljoin(href.extract())
## 将得到的页面地址传送给单个页面处理函数进行处理 -> parse_details()
yield scrapy.Request(url,callback=self.parse_details)
## 是否还有下一页,如果有的话,则继续
next_page=response.xpath("//div[@class='pager cf tc pt10 pb10 mobile_dn']/li[last()-1]/a/@href").extract_first()
if next_page is not None:
next_pages = response.urljoin(next_page)
## 将 「下一页」的链接传递给自身,并重新分析
yield scrapy.Request(next_pages, callback = self.parse)
# 编写爬取方法
def parse_details(self, response):
#for line in response.xpath("//ul[@class='newsinfo_list_ul mobile_dn']"):
# 初始化item对象保存爬取的信息
item = TeachersItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
item['name'] = response.xpath("//div[@class='r fr']/h3/text()").extract()
item['position'] = response.xpath("//div[@class='r fr']/p/text()").extract()
item['details'] = response.xpath("//div[@class='r fr']/div/text()").extract()
yield item
爬取结果部分截图:


共128名全职教师信息。
5.总结
一旦涉及到代码,就一定要仔细啊,认真啊,不然有可能就因为一个数字,或者一个字母就可以让你花几个小时甚至有可能几天都找不出来错误,甚至让你怀疑人生,受尽折磨T_T。
输入的时候记得要在英文模式下输入,英文字母倒是只有英文能够输入,所以要特别注意的就是标点符号什么的。Python的缩进也是个麻烦事,在编写过程中也要记得千万不要空格和tab标签混用了,还有,就是项目名称和.py文件不能同名,虽然遇到了也不是什么大问题,但是一开始注意到这个问题也就省一些麻烦嘛。前面说到的都是些小case,最麻烦的还是爬取路径的问题,那就只有认真、耐心、仔细了。认真学习爬取规则,认真分析爬取路径。