一 . 从GEO数据库中下载表达矩阵文件
GSE112996_merged_fpkm_table.txtGSE112996_series_matrix.txt,把GSE112996_series_matrix.txt解压,得到如下两个文件,把这两个文件放到对应的project文件夹内(备注:GSE112996_merged_fpkm_table是这个数据集的补充表达矩阵,不是所有数据集都有这个格式的)
image.png
二 . 读取这两个文件
2.1读取表达矩阵
rm(list=ls())
a <- read.table('GSE112996_merged_fpkm_table.txt.gz',
header = T,
row.names=1)#读取已经下载好的补充的表达矩阵压缩文件
a[1:4,1:4]

a.png
可以看到读取的表达矩阵,第一列是基因名
raw_data<- a[,-1]

raw_data.png
去掉基因名,得到纯粹的表达矩阵raw_data
2.2读取表型信息
###读取表型信息
pheno <- read.csv(file = 'GSE112996_series_matrix.txt')

pheno .png
pheno <- data.frame(num1 = strsplit(as.character(pheno[42,]),split='\t')[[1]][-1],
num2 = gsub('patient: No.','P',strsplit(as.character(pheno[51,]),split='\t')[[1]][-1]))

可以看到第42行的pheno数据里面含了标本名称,且之间用\t隔开

把上面这串数据,用\t做拆分,得到标本名称

去掉第一个没有用的,得到标本名称

可以看到第51行含有样本编号,用\t隔开

和上面同样的方法处理之后,得到样本编号

去掉每个编号前面繁杂的patient: No.,用p代替
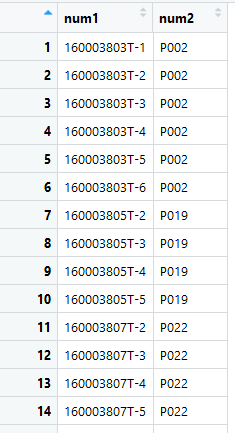
最终得到pheo
三处理两个文件
####数据过滤,把表达量和为0的基因去掉(去O)
data<- a[!apply(raw_data,1,sum)==0,]
####去除重复基因名的行,归一化
data$median=apply(data[,-1],1,median)#计算每行的中位数,添加到 data数据中
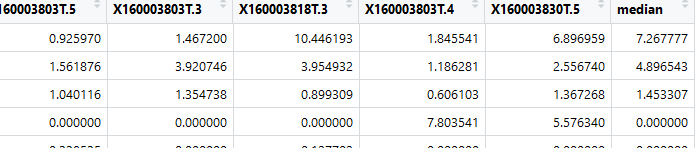
image.png
data=data[order(data$GeneName,data$median,decreasing = T),]#排序
data=data[!duplicated(data$GeneName),]#去除重复的基因名
rownames(data)=data$GeneName#把基因名变成行名
uni_matrix <- data[,grep('\\d+',colnames(data))]
#grep('\\d+',colnames(data))识别有数字的位置,然后挑出来
uni_matrix <- log2(uni_matrix+1)#把表达矩阵log
colnames(uni_matrix)<- gsub('X','',gsub('\\.','\\-',colnames(uni_matrix)))#处理行名
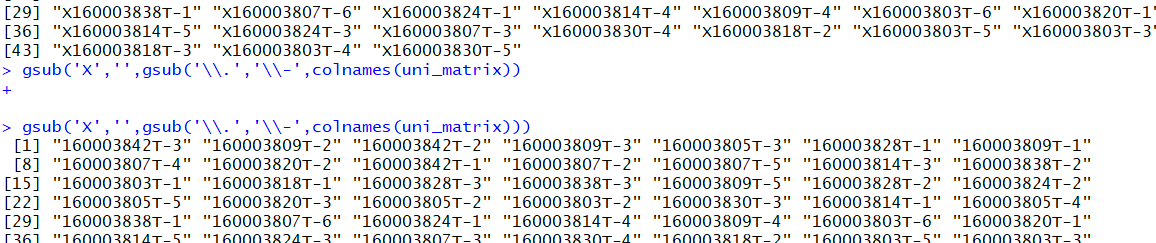
image.png
uni_matrix<- uni_matrix[,order(colnames(uni_matrix))]#根据行名排序表达矩阵
save(uni_matrix,pheno,file = 'uni_matrix.Rdata')##把处理好的数据存好
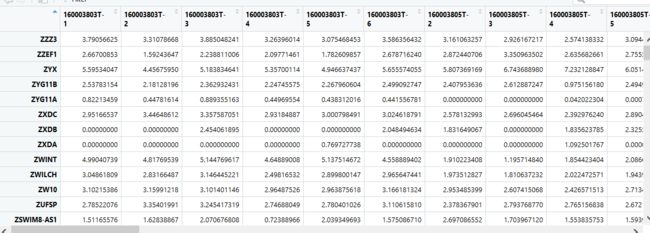
得到和pheo样本名一样的表达矩阵
四、进行ssGSEA分析
4.1加载包载入数据
rm(list=ls())
加载包
{
library(genefilter)
library(GSVA)
library(Biobase)
library(stringr)
}
##载入数据
load('uni_matrix.Rdata')
4.2读取基因列表,得到免疫细胞对应的特异的基因
gene_set<- read.csv('geneji.csv',
header = T)##读取已经下载好的免疫细胞和对应基因列表,来源见文献附件
gene_set<-gene_set[, 1:2]#选取特异基因和对应的免疫细胞两行
head(gene_set)
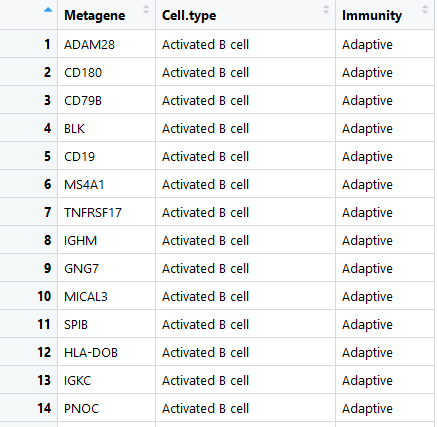
image.png
list<- split(as.matrix(gene_set)[,1], gene_set[,2])

list.png

list.png
得到每种免疫细胞对应的基因
4.3评估Estimates GSVA enrichment scores.
gsva_matrix<- gsva(as.matrix(uni_matrix), list,method='ssgsea',kcdf='Gaussian',abs.ranking=TRUE)

得到对应的富集分数
4.4把富集分数画热图
library(pheatmap)
gsva_matrix1<- t(scale(t(gsva_matrix)))#归一化
gsva_matrix1[gsva_matrix1< -2] <- -2
gsva_matrix1[gsva_matrix1>2] <- 2
anti_tumor <- c('Activated CD4 T cell', 'Activated CD8 T cell', 'Central memory CD4 T cell', 'Central memory CD8 T cell', 'Effector memeory CD4 T cell', 'Effector memeory CD8 T cell', 'Type 1 T helper cell', 'Type 17 T helper cell', 'Activated dendritic cell', 'CD56bright natural killer cell', 'Natural killer cell', 'Natural killer T cell')
pro_tumor <- c('Regulatory T cell', 'Type 2 T helper cell', 'CD56dim natural killer cell', 'Immature dendritic cell', 'Macrophage', 'MDSC', 'Neutrophil', 'Plasmacytoid dendritic cell')
anti<- gsub('^ ','',rownames(gsva_matrix1))%in%anti_tumor
pro<- gsub('^ ','',rownames(gsva_matrix1))%in%pro_tumor
non <- !(anti|pro)##设定三种基因
gsva_matrix1<- rbind(gsva_matrix1[anti,],gsva_matrix1[pro,],gsva_matrix1[non,])#再结合起来,使图分成三段
normalization<-function(x){
return((x-min(x))/(max(x)-min(x)))}#设定normalization函数
nor_gsva_matrix1 <- normalization(gsva_matrix1)
annotation_col = data.frame(patient=pheno$num2)#加上病人编号
rownames(annotation_col)<-colnames(uni_matrix)#使编号能互相对应
bk = unique(c(seq(0,1, length=100)))#设定热图参数
pheatmap(nor_gsva_matrix1,
show_colnames = F,
cluster_rows = F,cluster_cols = F,
annotation_col = annotation_col,
breaks=bk,cellwidth=5,cellheight=5,
fontsize=5,gaps_row = c(12,20),
filename = 'ssgsea.pdf',width = 8)#画热图
save(gsva_matrix,gsva_matrix1,pheno,file = 'score.Rdata')

image.png
五ggplot2绘图
rm(list=ls())
anti_tumor <- c('Activated CD4 T cell', 'Activated CD8 T cell', 'Central memory CD4 T cell', 'Central memory CD8 T cell', 'Effector memeory CD4 T cell', 'Effector memeory CD8 T cell', 'Type 1 T helper cell', 'Type 17 T helper cell', 'Activated dendritic cell', 'CD56bright natural killer cell', 'Natural killer cell', 'Natural killer T cell')
pro_tumor <- c('Regulatory T cell', 'Type 2 T helper cell', 'CD56dim natural killer cell', 'Immature dendritic cell', 'Macrophage', 'MDSC', 'Neutrophil', 'Plasmacytoid dendritic cell')
load('score.Rdata')
anti<- as.data.frame(gsva_matrix1[gsub('^ ','',rownames(gsva_matrix1))%in%anti_tumor,])
pro<- as.data.frame(gsva_matrix1[gsub('^ ','',rownames(gsva_matrix1))%in%pro_tumor,])
anti_n<- apply(anti,2,sum)
pro_n<- apply(pro,2,sum)
patient <- pheno$num2[match(colnames(gsva_matrix1),pheno$num1)]
library(ggplot2)
data <- data.frame(anti=anti_n,pro=pro_n,patient=patient)
anti_pro<- cor.test(anti_n,pro_n,method='pearson')
gg<- ggplot(data,aes(x = anti, y = pro),color=patient) +
xlim(-20,15)+ylim(-15,10)+
labs(x="Anti-tumor immunity", y="Pro-tumor suppression") +
geom_point(aes(color=patient),size=3)+geom_smooth(method='lm')+
annotate("text", x = -5, y =7.5,label=paste0('R=',round(anti_pro$estimate,4),'\n','p<0.001'))
ggsave(gg,filename = 'cor.pdf', height = 6, width = 8)
画相关图,原理和上面差不多
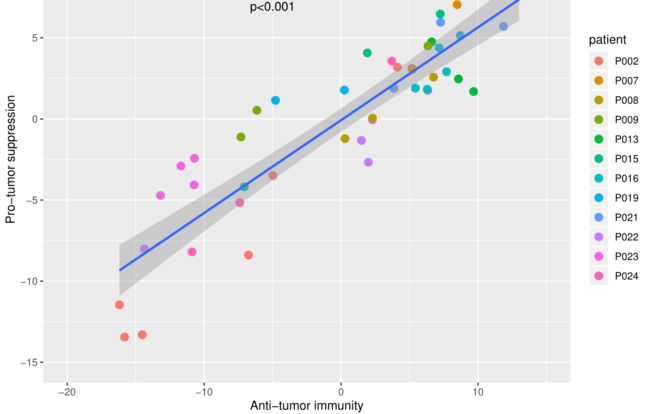
image.png