分析网页
通过浏览器查看网页源代码,未能找到职位信息,因此需要打开F12开发者工具抓包分析职位数据使怎样被加载到网页的。抓包后发现职位数据是通过js异步加载的,数据存在于XHR的json数据中。因此可以分析ajax请求,得到其头部信息,从而进行抓取。
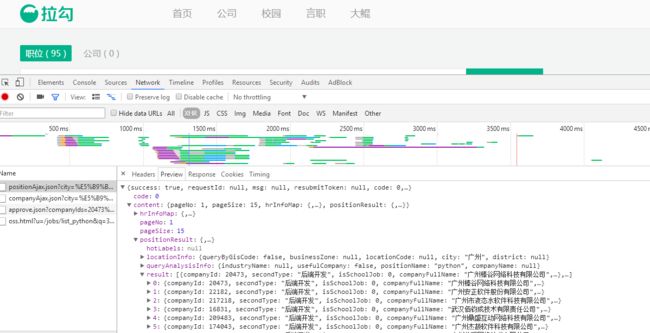
抓包截图
爬取思路
- 通过抓包获取头部信息,再用requests获取返回的json数据,然后观察处理后得到职位信息
- 将抓取的信息写入Excel表保存
代码实现
- 通过抓包获取头部信息,再用requests获取返回的json数据,然后观察处理后得到职位信息
def get_job_list(data):
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&' \
'needAddtionalResult=false&isSchoolJob=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko)' \
'Chrome/50.0.2661.102 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_python?'\
'city=%E5%B9%BF%E5%B7%9E&cl=false&fromSearch=true&labelWords=&suginput=',
'Cookie': 'user_trace_token=20170828211503-'\
'e7456f80-8bf2-11e7-8a6b-525400f775ce;' \
'LGUID=20170828211503-e74571a4-8bf2-11e7-8a6b-525400f775ce; '\
'index_location_city=%E5%B9%BF%E5%B7%9E; '\
'Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1503926479,1503926490,'\
'1503926505,1505482427; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6'\
'=1505482854; LGRID=20170915214052-7da8c649-9a1b-11e7-94ae-525400f775ce;'\
' _ga=GA1.2.1531463847.1503926105; _gid=GA1.2.1479848580.1505482430;'\
'Hm_lvt_9d483e9e48ba1faa0dfceaf6333de846=1503926253,1503926294,'\
'1503926301,1505482781; Hm_lpvt_9d483e9e48ba1faa0dfceaf6333de846='\
'1505482855; TG-TRACK-CODE=search_code; '\
'JSESSIONID=ABAAABAACBHABBIEDE54BE195ADCD6F900E8C2AE4DE5008; '\
'SEARCH_ID=1d353f6b121b419eaa0e511784e0042e'
}
response = requests.post(url,data=data,headers=headers)
jobs=response.json()['content']['positionResult']['result']
return jobs
- 将抓取的信息写入Excel表
def excel_write(wb,style,jobs,name):
ws = wb.add_sheet(name)
headdata = ['positionName','salary','city','district','workYear','education',
'companyFullName']
datadict = {0:'positionName',1:'salary',2:'city',3:'district',
4:'workYear',5:'education',6:'companyFullName'}
for i in range(7):
ws.write(0, i, headdata[i], style)
index=1
for i in jobs:
for j in range(7):
ws.write(index, j, i[datadict[j]])
index += 1
- 爬取源码
# !/usr/bin/env python3.6
# coding:utf-8
# @Author : Natsume
# @Filename : lagoujob.py
'''
@Description:
拉勾网职位信息爬虫,修改post的data相关参数可以爬取任何职位的相关信息
'''
import requests
import xlwt
import time
# 获取json数据,并处理得到职位信息
def get_job_list(data):
url = 'https://www.lagou.com/jobs/positionAjax.json?'\
'city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko)' \
'Chrome/50.0.2661.102 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_python?'\
'city=%E5%B9%BF%E5%B7%9E&cl=false&fromSearch=true&labelWords=&suginput=',
'Cookie': 'user_trace_token=20170828211503-'\
'e7456f80-8bf2-11e7-8a6b-525400f775ce;' \
'LGUID=20170828211503-e74571a4-8bf2-11e7-8a6b-525400f775ce; '\
'index_location_city=%E5%B9%BF%E5%B7%9E; '\
'Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1503926479,1503926490,'\
'1503926505,1505482427; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6'\
'=1505482854; LGRID=20170915214052-7da8c649-9a1b-11e7-94ae-525400f775'\
' ce;_ga=GA1.2.1531463847.1503926105; _gid=GA1.2.1479848580.1505482430;'\
'Hm_lvt_9d483e9e48ba1faa0dfceaf6333de846=1503926253,1503926294,'\
'1503926301,1505482781; Hm_lpvt_9d483e9e48ba1faa0dfceaf6333de846='\
'1505482855; TG-TRACK-CODE=search_code; '\
'JSESSIONID=ABAAABAACBHABBIEDE54BE195ADCD6F900E8C2AE4DE5008; '\
'SEARCH_ID=1d353f6b121b419eaa0e511784e0042e' } # 设置请求头部信息
response = requests.post(url,data=data,headers=headers)
jobs=response.json()['content']['positionResult']['result'] # 处理得到职位信息
return jobs
#将抓取的职位信息写入Excel表
def excel_write(wb,style,jobs,name):
ws = wb.add_sheet(name)
headdata = ['positionName','salary','city','district','workYear','education',
'companyFullName']
datadict = {0:'positionName',1:'salary',2:'city',3:'district',
4:'workYear',5:'education',6:'companyFullName'}
for i in range(7): # 写入表头
ws.write(0, i, headdata[i], style)
index=1
for i in jobs: #
for j in range(7):
ws.write(index, j, i[datadict[j]])
index += 1
#设置写入字体样式
def set_style():
style = xlwt.XFStyle()
font = xlwt.Font()
font.bold = True
font.italic = False
font.name = '宋体'
style.font = font
return style
# 设置post请求的头部数据
def get_data(i,x):
data = {
'first': 'false',
'pn':str(i),
'kd':x
}
return data
# 爬虫执行入口
if __name__ == '__main__':
wb = xlwt.Workbook(encoding='utf-8')
for i in range(1,9):
kd = 'python'
data = get_data(i,kd)
jobs = get_job_list(data)
style = set_style()
excel_write(wb,style,jobs,data['kd']+str(i))
time.sleep(1)
print(i)
savepath = 'D:/pythonjob/{}拉勾网.xls'.format(kd)
wb.save(savepath)
爬取结果
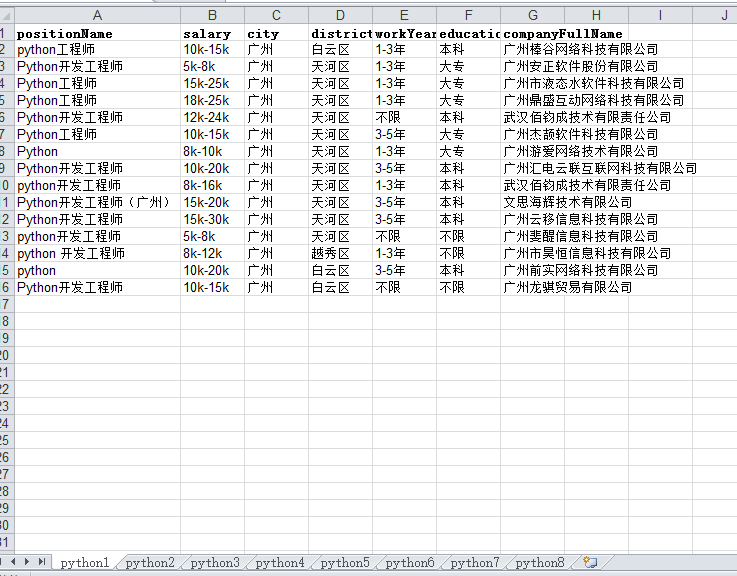
爬取结果