AutoML全称是automated machine learning,下面有一段AutoML不是什么的描述:
AutoML is not automated data science. While there is undoubtedly overlap, machine learning is but one of many tools in the data science toolkit, and its use does not actually factor in to all data science tasks. For example, if prediction will be part of a given data science task, machine learning will be a useful component; however, machine learning may not play in to a descriptive analytics task at all.
大至意思是说不要迷信AutoML,它只是数据科学众多工具中的一种,而且它也只能解决众多数据科学任务中的某些任务。
AutoML可以做如下这些事情:
预处理(preprocess)并清理数据
选择并构造合适的特征(features)
从现有的模型部件中选择合适的模型结构(model family),类似堆积木
优化模型超参数(hyperparameters)
后处理(postprocess)机器学习模型
严格分析模型输出结果
从AutoML可以做的这些事情可以看出,至少针对一些特定的场景,它是能够做到全自动的,即数据清洗、特征选择、建模、超参优化、模型评估等。我们可能关键是要知道automl适合哪些场景,把它做成我们AI的亮点,而不是所有。
在描述本文的AutoML之前,需要看几个概念,即人工智能、机器学习、深度深度之间的关系,下图是从网上找到的:
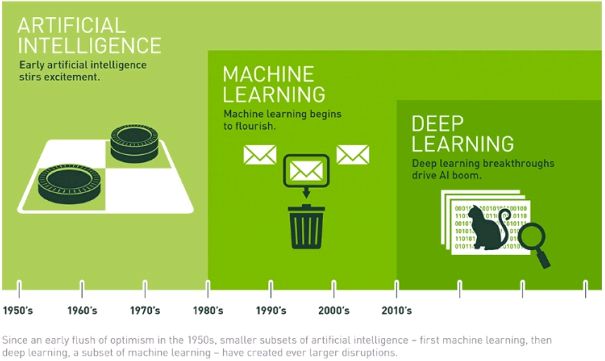
简单的说机器学习是实现人工智能的一种手段,而深度学习是在机器学习的发展过程中,发展出来的一个分支,广义上讲它也是机器学习,但是由于其实现机制和原来的机器学习算法有较大的不同,所以发展为一个独立的领域。机器学习和深度学习都是建模的有效工具,只是它们面向的场景有所不同。
所以,
AutoML也需要分为两个种类,传统的AutoML和深度AutoML。即传统的AutoML是为了解决传统机器学习的建模问题,它面向的是传统机器学习相关算法,如线性回归、逻辑回归、决策树等等。而深度AutoML更多的是面向深度学习中神经网络的建模。
本文主要研究的就是面向深度学习领域的AutoML。
AutoML和神经架构搜索(NAS)是深度学习领域当前最热门的话题。 它们能以快速而有效的方式,只需要做很少的工作,即可为你的机器学习任务构建好网络模型,并获得高精度。 简单有效!
Being able to go from idea to result with the least possible delay is key to doing good research.
将想法快速实现(变成结果)是优秀研究的关键。
AutoML完全改变了整个机器学习领域的游戏规则,因为对于许多应用程序,不需要专业技能和知识。 许多公司只需要深度网络来完成更简单的任务,例如图像分类。 那么他们并不需要雇用一些人工智能专家,他们只需要能够数据组织好,然后交由AutoML来完成即可。
从上面这段话可以看出,AutoML并不是万能的,并不是所有的机器学习问题都能交由它来完成,它是针对特定领域所提供的自动化解决方案,以降低普通公司使用机器学习的门槛及成本。
AutoML是目前比较热门的一个研究领域,主要应用于图像识别,但在其它领域应用的较少。
下面是使用Auto-Keras实现mnist的一个例子,用它来看看AutoML到底在做什么。
1. Auto Keras
它是AutoML的一个实现工具包,google也有自己的automl,但是那个要收费,我就从这个着手,先看看AutoML能做什么,后期再去深入了解其实现原理及机制。
不出意外的情况下,安装auto keras只需要一行命令即可:pip3 install autokeras,如果出现异常情况,比如缺少依赖包,按照异常提示补装上即可。
下面是一个使用auto keras编写的手写数字识别mnist的源码:
from keras.datasets import mnist
import autokeras as ak
if __name__ == '__main__':
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape + (1,))
x_test = x_test.reshape(x_test.shape + (1,))
clf = ak.ImageClassifier(verbose=True, augment=False)
clf.fit(x_train, y_train, time_limit=12 * 60 * 60)
clf.final_fit(x_train, y_train, x_test, y_test, retrain=True)
y = clf.evaluate(x_test, y_test)
print(y * 100)
从上面的代码可以看出它的写法非常简单,一般使用tensorflow构建一个mnist的神经网络模型,可能需要一两百行代码,中间涉及到各个输入输出层的构造;而使用auto keras只需要编写几行代码,它的写法有点类似机器学习工具包scikit-learn,完全隐藏了复杂的神经网络构建过程。
但是我们可以从这段代码的运行日志中看到它大概在做什么:
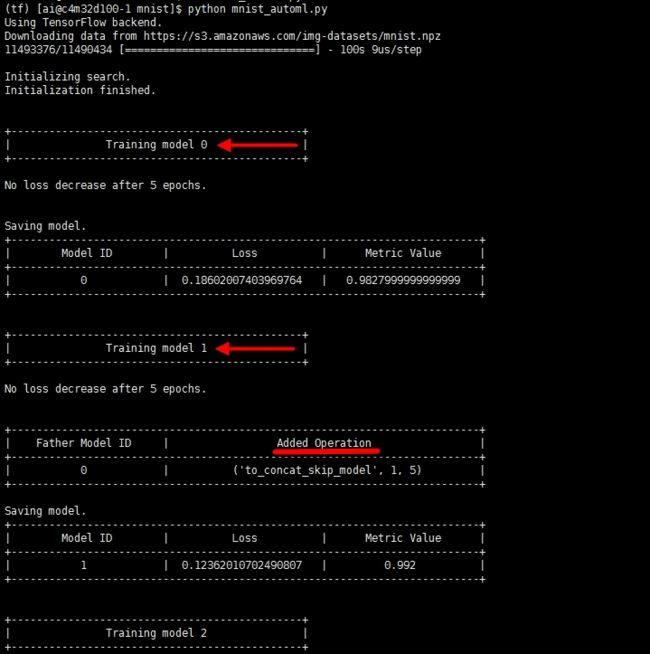
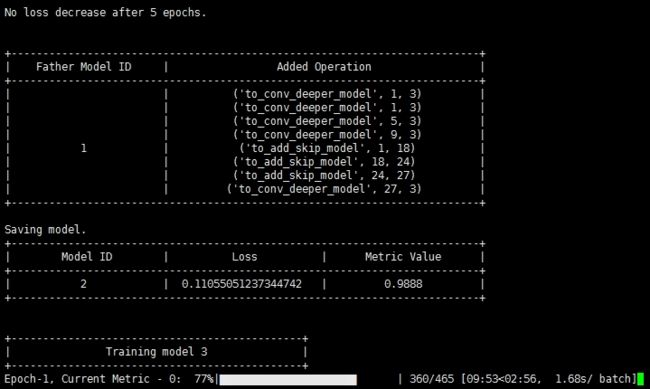
网络结构的构建过程是自动的
训练过程是自动的
它构造了不止一个网络模型,每个模型它都会训练一番
后一个模型似乎是在前一个模型的基础上做了一些调整,继承了前一个模型,并且会加一些操作(调整网络结构)
调整的依据有可能是日志中的
loss以及metric value等,主要应该还是它有自己内部改变各种网络结构的算法。(其实就是ENAS算法)
下面是autokeras官网上的一段说明:
Auto-Keras provides functions to automatically search for architecture and hyperparameters of deep learning models.
也就是说Auto-Keras提供了一些工具包,可以自动搜索神经网络结构,以及自动进行深度学习模型的超参数调整。
从对auto keras的初步了解,可以看出AutoML通过自己的一套算法,把构建网络结构、调整网络结构、调整超参数、模型评估等等过程全部封装起来了,全部自动化完成。将原来可能毫无目的的结构调整、参数调整,通过科学化的算法变成结构有序的调整,降低了机器学习的门槛,缩短了整个建模过程。
2. 其它AutoML产品(工具包)
2.1 AutoWEKA
它是基于WEKA的一种AutoML实现,WEKA好像是一个老牌的数据挖掘工具。AutoWEKA就是针对WEKA的自动模型选择和超参数优化。基于Java的。
2.2 Auto-sklearn
基于scikit-learn的AutoML实现,它主要也是上面提到的,针对传统机器学习而言的自动建模。
该工具包使用15个分类器,14个特征预处理方法和4个数据预处理方法,产生具有110个超参数的结构化假设空间。
它的基本原理可以通过下图看个大概:

核心思想是使用贝叶斯优化!
2.3 H2O AutoML
它是基于H2O平台的一个AutoML实现,该平台主要面向传统机器学习算法,但是也包含了简单的深度学习网络模型,比如DNN。
这是一个非常好的机器学习平台,它综合了机器学习算法、深度学习算法、数据分析、数据可视化、自动超参搜索、以及多种训练指标可视化等,为用户提供了一套完整的人工智能解决方案。
2.4 Google Cloud AutoML
谷歌的AutoML是一个新兴的(alpha阶段)云计算机学习工具软件套件。 它基于谷歌最先进的图像识别研究,称为神经架构搜索(NAS)。NAS基本上是一种算法,根据您的特定数据集,搜索最佳神经网络以在该数据集上执行特定任务。
Google AutoML是一套机器学习工具,可以轻松培训高性能深度网络,无需用户掌握深度学习或AI知识; 所有你需要的是标记数据! Google将使用NAS为您的特定数据集和任务找到最佳网络。并且通过AutoML所找到的最佳网络一般情况下要远远好于人工设计的神经网络!
下图是Google Cloud's AutoML pipeline:

不过Google的这个是要收费的,而且还很贵!
3. AutoML实现原理分析
根据Thomas Elsken的论文介绍,AutoML主要包含三大领域:
NAS:Neural Architecture Search,神经网络结构搜索,即需要通过某种结构及算法,实现神经网络结构的自动生成。Hyper-parameter optimization:超参数优化,针对神经网络中的超参数进行自动优化。meta-learning:元学习,或者叫learning to learn,即学会学习。
3.1 NAS
Neural Architecture Search(NAS),即神经网络结构搜索技术,通过某种结构及算法,实现神经网络结构的自动生成,它主要包含搜索空间,以及搜索策略、性能评估策略等几个维度的知识。
3.1.1 搜索空间
可以简单理解为基于一定的前提和假设,并根据已有的经验,预置一些网络结构单元,就像堆积木一样,预先提供了各种各样的积木,最终的网络结构就是通过搜索空间中的这些原始积木组合成的。
也正是因为如此,通过这种模式生成的最终网络结构其实只是在给定的搜索空间中查找效果最优的模型结构而已,机器只是沿着人类设计好的算法,依据某些评估指标,通过不断的测试从而生成一个比较完美的网络结构。
绝大部分机器学习都不是人工智能,计算机并不是真的具有智能了,也不会无缘无故获得既定目标以外的能力。
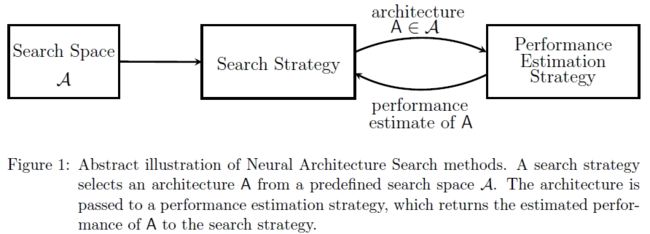
下图是对搜索空间以及空间中各单元之间关系的一个说明:
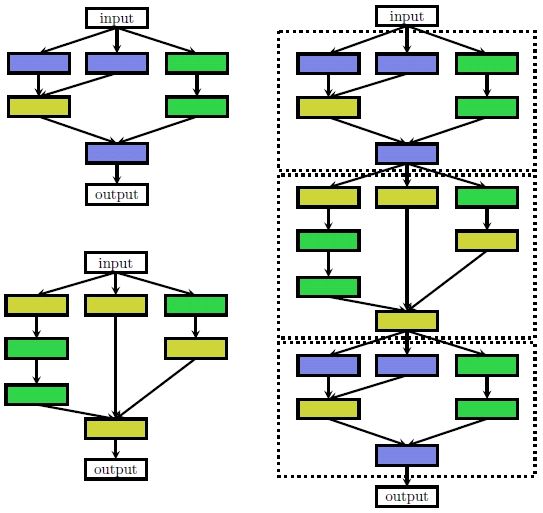
NAS算法所生成的网络结构是基于这样的一个前提:它认为一个大的神经网络结构是由很多小的、重复的单元所组成的。我们在构建整个神经网络时,只需要针对这些小的单元进行搜索,而不是每次针对整个网络结构进行搜索。
如上图左侧上下两张图所示,NAS将这种最小的组件称之为cells或blocks,有两种类型的单元,一种是维持维度的正常单元(normal cell),一种是降低维度的还原/降低单元(reduction cell),然后通过以预定义的方式堆叠这些单元来构建最终的网络架构(右上图右侧部分)。
何为维持维度的单元,何为降低维度的单元,这部分我没有看明白。
以图像识别为例,在Google的NASNet网络中,就将图像识别网络分成如下这些单元(或块):

可以看出这是基于人类在图像识别领域的前期研究经验的,它预置了很多块,如各种维度的卷积层,各种维度的池化层等,这其中还会涉及到的些连接函数(激活函数)。
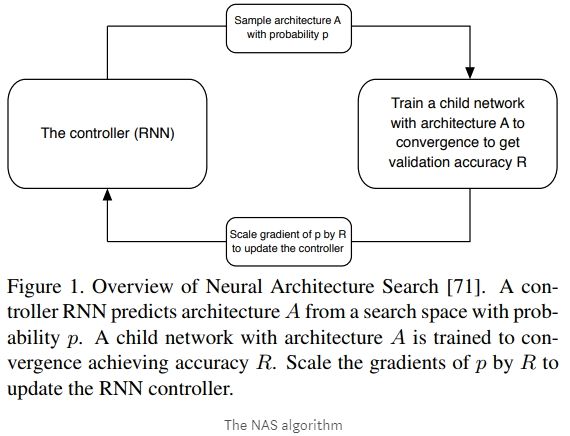
接下来要做的事情就像堆积木一样,拼装出各种各样的网络结构,并对这些结构进行训练评估,使用`RNN``网络做为控制器,来不断的重复这个过程,直接训练出满意的网络结构。如下图所示:
3.1.2 搜索策略
搜索策略详细说明了如何探索搜索空间,它围绕着经典的探索-利用权衡问题,一方面希望能尽快找到性能良好的架构,另一方面,也需要解决如何避免过早收敛到次优架构区域。
何为探索-利用问题?网上找到的一个例子:
假设你家附近有十个餐馆,到目前为止,你在八家餐馆吃过饭,知道这八家餐馆中最好吃的餐馆可以打8分,剩下的餐馆也许会遇到口味可以打10分的,也可能只有2分,如果为了吃到口味最好的餐馆,下一次吃饭你会去哪里?
所谓探索:是指做你以前从来没有做过的事情,以期望获得更高的回报。所谓利用:是指做你当前知道的能产生最大回报的事情。那么,你到底该去哪家呢?这就是探索-利用困境。
搜索策略定义了使用怎样的算法可以快速、准确找到最优的网络结构参数配置。常见的搜索方法包括:随机搜索(random search)、贝叶斯优化(Bayesian optimization)、进化算法(evolutionary methods)、强化学习(reinforcement learning [RL])、基于梯度的算法(gradient-based methods)。其中,2017 年谷歌大脑的那篇强化学习搜索方法将这一研究带成了研究热点,后来 Uber、Sentient、OpenAI、Deepmind 等公司和研究机构用进化算法对这一问题进行了研究,这个 task 算是进化算法一大热点应用。
注:国内有很多家公司在做 AutoML,其中用到的一种主流搜索算法是进化算法。
算法的演进历史
在2000年以前,
进化算法被用在了改进神经网络结构的各种研究上。用进化算法对神经网络超参数进行优化是一种很古老、很经典的解决方案,90 年代的学者用进化算法同时优化网络结构参数和各层之间的权重,因为当时的网络规模非常小,所以还能解决,但后续深度学习模型网络规模都非常大,无法直接优化。从2013年,
贝叶斯优化也在之后获得了一些成功,以及2015年在cifar10上通过该算法生成的网络结构首次超过人类专家设计的。2017年,使用
强化学习算法,在cifar10和Penn上获得了巨大的成功,也是从这时开始,NAS开始变成机器学习中的热门研究话题。但是当时是使用800个GPU,跑了三四周才跑完的。从那以后,开始有越来越多的人研究如何提高NAS算法的性能。其中最出名的就是ENAS算法。
Esteban Real在2018年主导了一项研究,即研究强化学习、进化算法、随机搜索三者的优劣,主要是研究三者在cifar10上的表现。最终研究结果表明,强化学习和进化算法要优于随机搜索,另外在网络规模小的情况下,进化算法表现是最好的。
贝叶斯优化在超参数优化问题上是最为流行的,但是很少有将其应用于NAS上,主要是因为典型的贝叶斯优化工具包是基于高斯过程并专注于低维连续优化问题。
在分层搜索领域,比如结合进化或者基于顺序模型的优化,蒙特卡洛树搜索(Monte Carlo Tree Search)也是研究方向之一。
3.1.3 性能评估策略
NAS的目标就是寻找在未知数据集上有很好预测性能的网络结构模型,性能评估模块就是用来评估这些生成的网络结构的性能。而一种最简单的性能评估方法,就是针对该网络结构,使用数据集进行一次标准的训练和验证,从而评估其性能。但是这种最简单的方法,会带来昂贵的计算开销以及时间开销,从而进一步限制我们能探索到的网络结构数量。
因此,最近的许多研究都集中在开发降低这些性能评估成本的方法上。
性能评估策略中,有一种办法是基于低保真的策略,比如更短的训练时间、使用更少的训练集、使用更低的图片分辨率、或者每层中使用更少的过滤器(filter),这种作法会大大的降低训练开销,但是也会带来一些指标上的偏差,不过这种偏差对最终结果影响不大。
还有一种策略是基于推断法,比如学习曲线推断法,这种思路的核心思想是建议推断初始学习曲线并终止那些预测表现不佳的曲线,以加快架构搜索过程。还有一种推断法是基于代理模型的推断,即通过小的网络模型的性能表现推断出最终的网络模型。
还有一种策略是是基于权重参数迁移的,即将一个已经训练好的模型参数直接应用于当前网络结构,当前网络模型就相当于在一个高起点的情况下进行学习,可以大大缩短训练时间。
还有一种策略叫One-Shot架构搜索,原理没有看明白。网上解释是这种方法将所有架构视作一个 one-shot 模型(超图)的子图,子图之间通过超图的边来共享权重。
3.1.4 NAS未来的方向
目前绝大多数聚焦在NAS上的研究都是针对图像分类的。在其它领域仍然应用较少,如语言建模、音乐建模、图像修复、网络压缩、语义分割等。
另外就NAS的实现原理而言,其搜索空间是完全基于人类经验的,比如针对图像分类领域,我们给搜索空间定义了很多单元,如卷积层、池化层等,而这些基本只能针对图像领域,我们无法将其应用到其它领域中,这种网络结构的搜索,最终也会被限制在这些预定义好的单元之中。NAS未来的一个研究方向就是定义一个更通用、更可扩展的搜索空间。
3.1.5 NAS的演进
由于NAS每次搜索网络结构都需要对其进行一次训练,在Google的NASNet网络上,需要使用450块GPU训练3到4天,这种昂贵的开销注定小公司是消费不起的。
Efficient Neural Architecture Search (ENAS),是目前比较出名的一种nas加强版算法。它的理论基础就是迁移学习和权重共享,ENAS算法强制所有模型共享权重,而不是从头开始训练到收敛。 我们之前在之前模型中尝试过的任何块都将使用之前学过的权重。 因此,我们每次培训新模型时都会进行转移学习,收敛速度更快!
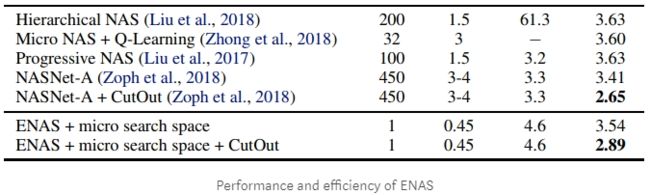
如上图所示,本来需要450块GPU卡跑3,4天的模型,在使用了ENAS之后,只需要一块1080Ti GPU,跑半天即可。
我们最上面的例子中,
auto keras就是使用了enas的算法。
3.2 Hyper-parameter optimization
超参数优化,并不是最近才发展起来的,它一直伴随着机器学习和深度学习。几乎每一种算法,都会涉及到各种各样的超参数,这些超参数设置的好坏直接决定了建模了效率以及效果。而实际建模过程中,很多情况下就是凭经验进行设置,或者进行大量的试错、反复训练。
超参数优化就是通过算法层面,将超参数的设置交给计算机去搜索获得。比较流行的算法主要有:贝叶斯优化、随机搜索、网格搜索。
这其中最有名的应该就是贝叶斯优化算法了,贝叶斯优化是一种近似逼近的方法,用各种代理函数来拟合超参数与模型评价之间的关系,然后选择有希望的超参数组合进行迭代,最后得出效果最好的超参数组合。代理函数中比较有名的就是高斯函数。
贝叶斯优化的核心思想是,通过用户给定的两个X值以及对应的Y值,拟合一个高斯函数,然后根据峰值找下一个可能的x值,其实给我的感觉也是瞎猜,不过猜的比较体面。
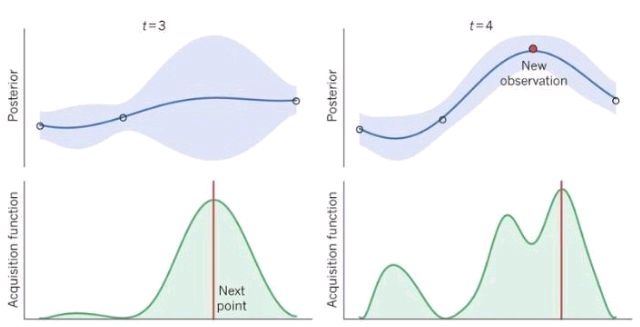
其它两种超参优化算法就比较简单了,随机搜索就是瞎猜,给计算机一个参数取值的范围,让计算机去瞎猜并不断尝试;网格搜索更简单,用户先瞎猜好几个取值,然后让计算机去尝试。
3.3 Meta-Learning
尚未研究。
3.4 算法相关
3.4.1 强化学习
强化学习是一种非常有意思的范式,几乎只要可以提炼出强化学习四要素,原问题就可以用强化学习来求解。
在 NAS 任务中,将架构的生成看成是一个 agent 在选择 action,reward 是通过一个测试集上的效果预测函数来获得(这个函数类似于工程优化问题中的 surrogate model,即代理模型)。这类工作整体的框架都是基于此,不同的点在于策略表示和优化算法。
3.4.2 进化算法
进化算法是一大类算法,大概的框架也基本类似,先随机生成一个种群(N 组解),开始循环以下几个步骤:选择、交叉、变异,直到满足最终条件。最近几年流行一种基于概率模型的进化算法 EDA (Estimation Distribution of Algorithm),基本的思路类似遗传算法,不同的是没有交叉、变异的环节,而是通过 learning 得到一个概率模型,由概率模型来 sample 下一步的种群。
用进化算法对神经网络超参数进行优化是一种很古老、很经典的解决方案,90 年代的学者用进化算法同时优化网络结构参数和各层之间的权重,因为当时的网络规模非常小,所以还能解决,但后续深度学习模型网络规模都非常大,无法直接优化。
3.4.3 贝叶斯优化
贝叶斯优化(Bayesian Optimization)是超参数优化问题的常用手段,尤其是针对一些低维的问题,基于高斯过程(Gaussian Processes)和核方法(kernel trick)。对于高维优化问题,一些工作融合了树模型或者随机森林来解决,取得了不错的效果。
除了常见的三大类方法,一些工作也在研究分层优化的思路,比如将进化算法和基于模型的序列优化方法融合起来,取各种方法的优势。Real 在 2018 年的一个工作对比了强化学习、进化算法和随机搜索三类方法,前两种的效果会更好一些。
4. AutoML应用场景
通过上面的描述可以知道,AutoML其实是针对一些比较成熟的人工智能解决方案,如常规机器学习,以及图像识别、图像分类等,主要用来解决这类场景下,网络模型的自动生成,以及超参数的自动优化。
目前的AutoML并生成不了超出人类思维以外的模型,它其实只是在预先设置好的一堆积木中,按照一定的策略去搭建一个组合的网络,所有的网络单元仍然是人类设置好的。
讲白了就是面对这些场景,科学家们已经知道如何去做,但是编写各种各样的网络模型、调整超参数、训练等,需要耗费大量的时间及金钱。而AutoML可以通过科学化的建模算法,有效的提高建模效率及质量,减少成本。所以针对这些场景使用AutoML是合适的。
而在语言建模、音乐建模、图像修复、网络压缩、语义分割等领域,有可能在这些领域中,还没有形成非常有效的解决方案,那么AutoML也就无从谈起了。
参考材料
https://towardsdatascience.com/auto-keras-or-how-you-can-create-a-deep-learning-model-in-4-lines-of-code-b2ba448ccf5e
解释automl相关知识,以及如何通过auto keras组件包对mnist进行AutoML实现。
https://autokeras.com/
auto keras官网。
https://www.automl.org/automl/
AutoML官网。
[Neural Architecture Search: A Survey](Neural Architecture Search: A Survey)
一篇针对NAS当前发展情况深度解读的文章,文章从三个维度对NAS进行了分析:搜索空间、搜索策略、性能评估策略。
https://towardsdatascience.com/googles-automl-will-change-how-businesses-use-machine-learning-c7d72257aba9
介绍Google AutoML的一篇文章。
https://towardsdatascience.com/everything-you-need-to-know-about-automl-and-neural-architecture-search-8db1863682bf
一篇介绍AutoML和NAS的文章。