上一篇文章,总结了在利用xpath爬取前程无忧职位信息遇到的问题,经过大神@逆水寒的亲自修改。问题完美解决。
上完整代码:
# coding:utf-8
from lxml import etree
import requests
import xlwt
class JobData(object):
def __init__(self):
self.count = 1
self.f = xlwt.Workbook() # 创建工作薄
self.sheet1 = self.f.add_sheet(u'任务列表', cell_overwrite_ok=True) # 创建工作表
self.rowTitle = [u'编号', u'职位名', u'工作地点', u'公司名', u'待遇', u'招聘网址']
for i in range(0, len(self.rowTitle)):
self.sheet1.write(0, i, self.rowTitle[i])
self.f.save('51job.xlsx')
def set_style(self, name, height, bold = False ):
style = xlwt.XFStyle # 初始化样式
font = xlwt.Font() # 创建字体
font.name = name
font.bold = bold
font.colour_index = 2
font.height = height
style.font = font
return style
def getUrl(self):
for i in range(50):
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,java,2,{}.html?'.format(i+1)
self.spiderPage(url)
def spiderPage(self, url):
if url is None:
return None
try:
proxies = {
'http': 'http://125.46.0.62:53281',
}
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4295.400'
headers = {'User_Agent': user_agent}
response = requests.get(url, headers=headers, proxies=proxies) # 获取整个网页
response.encoding = 'gbk'
selector = etree.HTML(response.text) # 将页面转换成xptah
trs = selector.xpath('//*[@id="resultList"]/div')
for tr in trs:
data = []
title = tr.xpath('./p/span/a/text()')
work = tr.xpath('./span[2]/text()')
company = tr.xpath('./span[1]/a/text()')
treatment = tr.xpath('./span[3]/text()')
href = tr.xpath('./p/span/a/@href')
title = title[0].strip() if len(title) > 0 else ''
work = work[0] if len(work) > 0 else ''
company = company[0] if len(company) > 0 else ''
treatment = treatment[0] if len(treatment) > 0 else ''
href = href[0] if len(href) > 0 else ''
print title.strip(), company.strip(), work.strip(), treatment.strip(), href.strip()
if title.strip() and work.strip() and treatment.strip() and href.strip():
"""
拼装成一个集合
"""
data.append(self.count) # 插入序号
data.append(title) # 插入职位
data.append(work) # 工作地点
data.append(company) # 插入公司
data.append(treatment) # 待遇
data.append(href) # 招聘网址
self.count += 1 # 增加记录行数
for i in range(len(data)):
self.sheet1.write(data[0], i, data[i]) # 将数据写入到excel
self.f.save('51job.xlsx')
except Exception, e:
print '出错', e.message
if '_main_':
Job = JobData()
Job.getUrl()
爬取的效果:
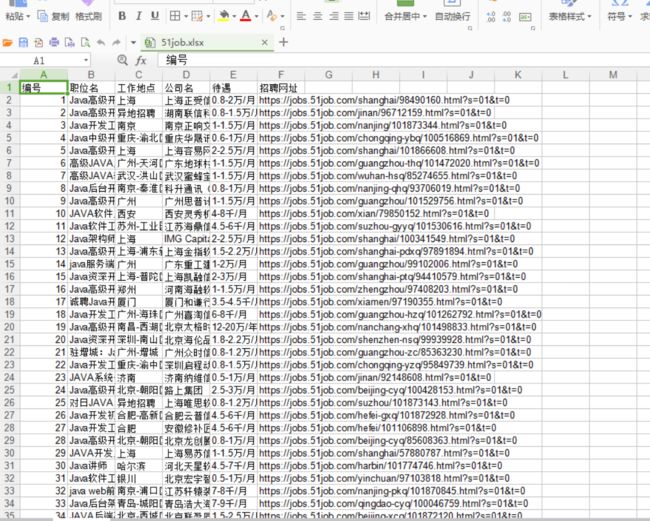
职位信息
上篇提的问题解决方法
问题一
取值有空格,前面提到用normalize-space函数,没有解决问题。寒大用strip()解决了这个问题,瞬间震惊了我,那么基础的知识点,我尽然忘记了。看来还要好好看基础。寒大的批复:不熟练,需要多多练习。
问题二
取值空字符的问题。加一个判断if判断
if title.strip() and work.strip() and company.strip() 这一句的意思是判断这三个字段一个为空放弃插入数据。
所以前三行不符,从第四行开始插入。不多不说大神的就是经验丰富,聪明绝顶。
代码如下图

strip()
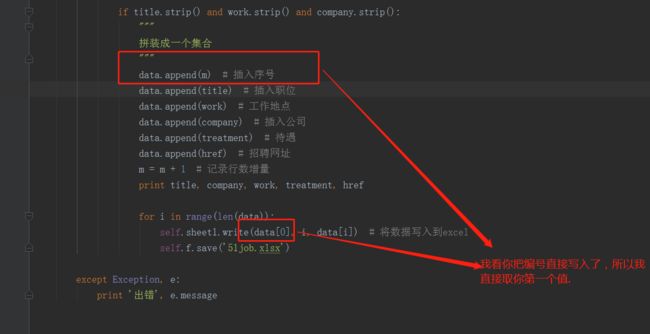
精简代码
代码交回我手中,又出现了一个问题,控制台打印正常,但是数据存入excel中只有50个数据。问题出在了,m定义在了spiderpage()函数中。精简代码图片里m = m+1 #增加记录的行数。如果把m定义在spiderPage内,导致没抓取一个页面。会重新赋值,覆盖了上一页的数据。解决办法就是将m定义成全局变量,每抓取一条增加新的一行。新的一页继续累加。

定义全局变量
增加记录行数

增加记录的行数