内核的文件结构
- task_struct
Linux内核通过一个被称为进程描述符的task_struct结构体来管理进程,这个结构体包含了一个进程所需的所有信息。 - struct file 和 struct files_struct
在nuix 系统中,万物皆为文件,在内核中文件用一个struct file来描述,在用户空间用一个整形的文件描述符来表示,和内核的struct file对应。一个进程中所有的struct file文件用struct files_struct* 组织, struct task_struct 结构体有一个 *struct files_struct files 域描述在这个进程中打开的文件。
kernle 的内存管理
内存区域
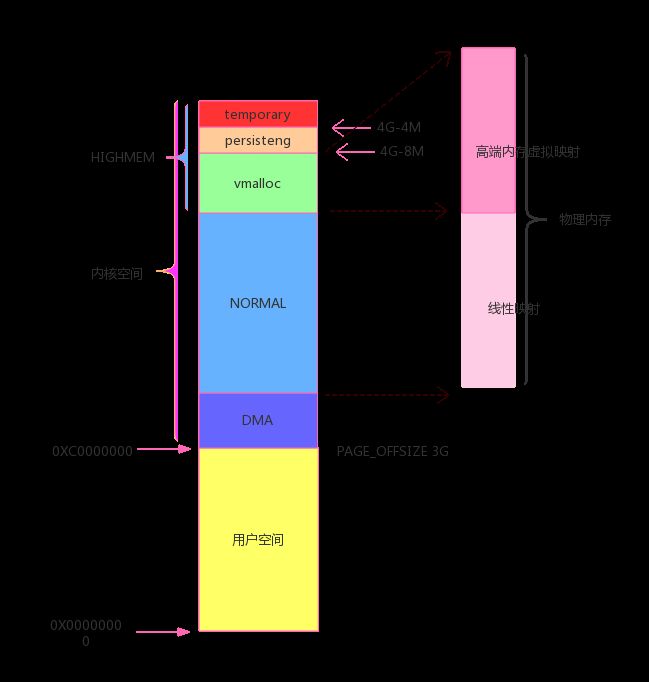
linux 中进程空间地址分为两部分,内核空间地址和用户空间地址。在32位系统上面,Linux的虚拟地址空间为0~4G字节。这4G 字节的空间分为两部分。将最高的1G字节(从虚拟地址0xC0000000 到0xFFFFFFFF),供内核使用,称为“内核空间”。而将较低的3G字节(从虚拟地址0x00000000 到0xBFFFFFFF),供各个进程使用,称为“用户空间”。内核空间被各个进程共享。
根据硬件的特性,其中内核空间地址又可以分为几个区域,主要有:ZONE_DMA, ZONE_NORMAL, ZONE_HIGHEM。在物理内存直接线性映射到内核空间ZONE_NORMAL,理论上如果内存不超过1G,1G线性空间足够映射物理内存了。如果物理内存大于1G,为了使内核空间的1G线性地址可以访问到大于1G的物理内存,把物理内存分为两部分,ZONE_NORMAL 区域的进行直接内存映射,这个区域的大小一般是896MB,也就是说存在一个线性关系:virtual address = physical address + PAGE_OFFSET,这里的PAGE_OFFSET为3G。剩下一个128MB的空间,称为高端内存,这个空间作为一个窗口动态进行映射,这样就可以访问大于1G的内存。ZONE_DMA 主要用于硬件特定的地址访问。
Android X86 模拟器上可以看到:MemTotal HighTotal LowTotal。
generic_x86:/ # cat /proc/meminfo
MemTotal: 1030820 kB
MemFree: 519392 kB
Buffers: 4460 kB
Cached: 325292 kB
SwapCached: 0 kB
Active: 184672 kB
Inactive: 290712 kB
HighTotal: 180104 kB
HighFree: 1132 kB
LowTotal: 850716 kB
LowFree: 518260 kB
mm_struct 和vm_area_struct
mm_struct 用来描述一个进程的虚拟地址空间。进程的 mm_struct 则包含装入 的可执行映像信息以及进程的页目录指针pgd。该结构还包含有指向 vm_area_struct结构的几个指针,每个vm_area_struct代表进程的一个虚拟地址区间。 vm_area_struct结构含有指向vm_operations_struct结构的一个指针, vm_operations_struct描述了在这个区间的操作
Binder 控制数据结构
binder_proc
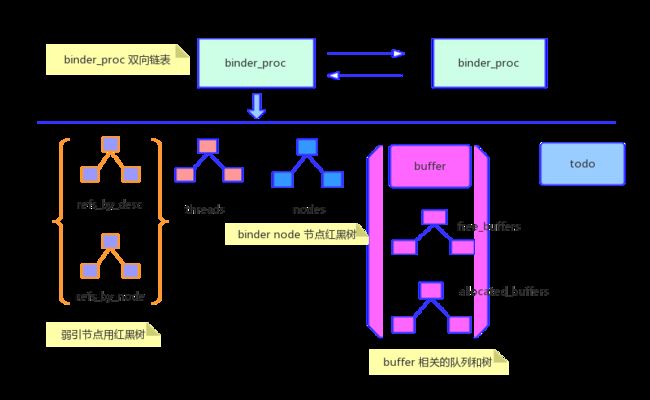
binder_proc和进程相关,用户空间中每个进程中对应一个内核的binder_proc 结构体。所有进程的binder_proc 结构体用双链表组织。在内核中双链表相关的结构体是 hlist_node,具体使用参考相关API
struct binder_proc {
struct hlist_node proc_node;
struct rb_root threads;
struct rb_root nodes;
struct rb_root refs_by_desc;
struct rb_root refs_by_node;
int pid;
struct vm_area_struct *vma;
struct mm_struct *vma_vm_mm;
struct task_struct *tsk;
struct files_struct *files;
struct hlist_node deferred_work_node;
int deferred_work;
void *buffer;
ptrdiff_t user_buffer_offset;
struct list_head buffers;
struct rb_root free_buffers;
struct rb_root allocated_buffers;
size_t free_async_space;
struct page **pages;
size_t buffer_size;
uint32_t buffer_free;
struct list_head todo;
wait_queue_head_t wait;
struct binder_stats stats;
struct list_head delivered_death;
int max_threads;
int requested_threads;
int requested_threads_started;
int ready_threads;
long default_priority;
struct dentry *debugfs_entry;
};
binder_thread
binder_thread 结构体和用户线程相关,用来描述用户空间的线程信息。binder_proc 结构体中有一个 struct rb_root threads 红黑树保存每个进程的线程信息。rb_node 是内核中的红黑树结构。binder_thread 结构体中有一个 struct rb_node rb_node 域,表示自己的在红黑树种的节点。
struct binder_thread {
struct binder_proc *proc;
struct rb_node rb_node;
int pid;
int looper;
struct binder_transaction *transaction_stack;
struct list_head todo;
uint32_t return_error; /* Write failed, return error code in read buf */
uint32_t return_error2; /* Write failed, return error code in read */
/* buffer. Used when sending a reply to a dead process that */
/* we are also waiting on */
wait_queue_head_t wait;
struct binder_stats stats;
};
binder_node
binder_node 在内核中表示一个Binder 服务,代表服务端,也用红黑树的方式组织。
struct binder_node {
int debug_id;
struct binder_work work;
union {
struct rb_node rb_node;
struct hlist_node dead_node;
};
struct binder_proc *proc;
struct hlist_head refs;
int internal_strong_refs;
int local_weak_refs;
int local_strong_refs;
binder_uintptr_t ptr;
binder_uintptr_t cookie;
unsigned has_strong_ref:1;
unsigned pending_strong_ref:1;
unsigned has_weak_ref:1;
unsigned pending_weak_ref:1;
unsigned has_async_transaction:1;
unsigned accept_fds:1;
unsigned min_priority:8;
struct list_head async_todo;
};
binder_ref
binder_ref 也表示内核中Binder 的节点,但是和binder_node不同的是binder_ref 表示的是代理端。binder_node 和 binder_ref 是相互关联的,代表的是一对多的关系,所以在binder_node中,binder_ref 用一个双链表表示 struct hlist_head refs。binder_ref仅仅有一个binder_node的指针,这也和服务端,客户端的关系对应起来。
struct binder_ref {
/* Lookups needed: */
/* node + proc => ref (transaction) */
/* desc + proc => ref (transaction, inc/dec ref) */
/* node => refs + procs (proc exit) */
int debug_id;
struct rb_node rb_node_desc;
struct rb_node rb_node_node;
struct hlist_node node_entry;
struct binder_proc *proc;
struct binder_node *node;
uint32_t desc;
int strong;
int weak;
struct binder_ref_death *death;
};
binder_work
binder_work 代表一个Binder 事物,具体来说,每次ioctl 产生一个binder_work。
struct binder_work {
struct list_head entry;
enum {
BINDER_WORK_TRANSACTION = 1,
BINDER_WORK_TRANSACTION_COMPLETE,
BINDER_WORK_NODE,
BINDER_WORK_DEAD_BINDER,
BINDER_WORK_DEAD_BINDER_AND_CLEAR,
BINDER_WORK_CLEAR_DEATH_NOTIFICATION,
} type;
};
在内核中这些结构如下图:
Binder 传输数据结构
struct binder_write_read
struct binder_write_read 结构体描述了一次 binder ioctl BINDER_WRITE_READ 从用户空间需要copy 的数据和需要从内核空间返回的数据。
/*
* On 64-bit platforms where user code may run in 32-bits the driver must
* translate the buffer (and local binder) addresses appropriately.
*/
struct binder_write_read {
binder_size_t write_size; /* bytes to write */
binder_size_t write_consumed; /* bytes consumed by driver */
binder_uintptr_t write_buffer;
binder_size_t read_size; /* bytes to read */
binder_size_t read_consumed; /* bytes consumed by driver */
binder_uintptr_t read_buffer;
};
Binder 文件操作
通过struct file_operations 结构体的定义binder 一共支持ioctl, mmap , open ,close, poll flush 这几种操作,最终要的是三个 open, ioctl mmap. 这三个函数我们前面已经接触过。
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
binder_open
- kzalloc 申请binder_proc 空间, 初始化 proc->todo 链表,
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
proc = kzalloc(sizeof(*proc), GFP_KERNEL); // 申请binder_proc 内存
if (proc == NULL)
return -ENOMEM;
get_task_struct(current); // 获取当前进程
proc->tsk = current;
proc->vma_vm_mm = current->mm; // mm 代表当前进程的内存管理信息
INIT_LIST_HEAD(&proc->todo); // 初始化 todo 链表
init_waitqueue_head(&proc->wait); // 初始化线程调度队列
proc->default_priority = task_nice(current);
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC); // 内核中记录打开的Binde 驱动次数
hlist_add_head(&proc->proc_node, &binder_procs); //binder_proc 加入到双向链表中
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death); // 初始化delivered_death binder_proc 双向链表
filp->private_data = proc;
binder_unlock(__func__);
if (binder_debugfs_dir_entry_proc) {
char strbuf[11];
snprintf(strbuf, sizeof(strbuf), "%u", proc->pid);
proc->debugfs_entry = debugfs_create_file(strbuf, S_IRUGO,
binder_debugfs_dir_entry_proc, proc, &binder_proc_fops);
}
return 0;
}
binder_stats
binder_stats_created(BINDER_STAT_PROC) 函数中记录binder 打开的次数。内核中有一个binder_stats 结构体,描述了7种binder 状态数量。
enum binder_stat_types {
BINDER_STAT_PROC,
BINDER_STAT_THREAD,
BINDER_STAT_NODE,
BINDER_STAT_REF,
BINDER_STAT_DEATH,
BINDER_STAT_TRANSACTION,
BINDER_STAT_TRANSACTION_COMPLETE,
BINDER_STAT_COUNT
};
struct binder_stats {
int br[_IOC_NR(BR_FAILED_REPLY) + 1];
int bc[_IOC_NR(BC_DEAD_BINDER_DONE) + 1];
int obj_created[BINDER_STAT_COUNT];
int obj_deleted[BINDER_STAT_COUNT];
};
static struct binder_stats binder_stats;
static inline void binder_stats_deleted(enum binder_stat_types type)
{
binder_stats.obj_deleted[type]++;
}
static inline void binder_stats_created(enum binder_stat_types type)
{
binder_stats.obj_created[type]++;
}
binder_mmap
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data; //获取当前进程的binder_proc 结构体
const char *failure_string;
struct binder_buffer *buffer;
if (proc->tsk != current)
return -EINVAL;
if ((vma->vm_end - vma->vm_start) > SZ_4M) // 最多4M 空间
vma->vm_end = vma->vm_start + SZ_4M;
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
if (proc->buffer) { // 已经mmap 返回
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
// 申请虚拟空间地址,指的是逻辑空间,在32 位机子上,高端内存地址空间是动态分配,
64 位不清楚。在这里只分配了地址,物理内存没有分配。
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP); if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
proc->buffer = area->addr; // proc->buffer 赋值,已经分配
// 计算内核空间地址和用户空间地址的偏移量。其实是同一块内存
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
//用于存放内核分配的物理页的页描述指针:struct page *,每个物理页对应这样一个struct page结构
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
//为binder内存的最开始的一个页的地址建立虚拟到物理页的映射,
仅仅一个也,注意传递的参数,第二个参数为1, 第四个和第三个参数差值为PAGE_SIZE
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
// 每个进程分配的buffer 也用双向链表管理
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
//buffer 插入binder_proc 的free_buffer 域的红黑树中
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
return 0;
binder_buffer
binder_buffer 结构体用来描述mmap 的内核空间内存
struct binder_buffer {
struct list_head entry; /* free and allocated entries by address */
struct rb_node rb_node; /* free entry by size or allocated entry */
/* by address */
unsigned free:1;
unsigned allow_user_free:1;
unsigned async_transaction:1;
unsigned debug_id:29;
struct binder_transaction *transaction;
struct binder_node *target_node;
size_t data_size;
size_t offsets_size;
uint8_t data[0];
};
binder_update_page_range
在binder_mmap 函数中,最重要的一个调用是binder_update_page_range,在这个函数中分配真正的物理内存,然后和页表映射,最后映射到逻辑地址。
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
}
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct page **page;
struct mm_struct *mm;
if (end <= start)
return 0;
if (vma)
mm = NULL;
else
mm = get_task_mm(proc->tsk);
if (mm) {
down_write(&mm->mmap_sem);
vma = proc->vma;
if (vma && mm != proc->vma_vm_mm) {
pr_err("%d: vma mm and task mm mismatch\n",
proc->pid);
vma = NULL;
}
}
if (allocate == 0)
goto free_range;
// 注意在上边已经注释过 end - start = PAGE_SIZE 所以这里只有一次循环
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
//分配一个物理页,并将该物理页的struct page指针值存放在proc->pages二维数组中
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
ret = map_kernel_range_noflush((unsigned long)page_addr,PAGE_SIZE, PAGE_KERNEL, page);
flush_cache_vmap((unsigned long)page_addr,(unsigned long)page_addr + PAGE_SIZE);
// 计算用户空间地址, 建立逻辑地址和物理地址的映射
user_page_addr = (uintptr_t)page_addr + proc->user_buffer_offset;
ret = vm_insert_page(vma, user_page_addr, page[0]);
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
return 0;
}
binder_ioctl
binder_ioctl 一共有以下几个命令:
#define BINDER_WRITE_READ _IOWR('b', 1, struct binder_write_read) // binder 读写操作,binder 通信主要用这个命令进行
#define BINDER_SET_IDLE_TIMEOUT _IOW('b', 3, __s64)
#define BINDER_SET_MAX_THREADS _IOW('b', 5, __u32) // 设置最大线程数
#define BINDER_SET_IDLE_PRIORITY _IOW('b', 6, __s32)
#define BINDER_SET_CONTEXT_MGR _IOW('b', 7, __s32) // ServiceManager 使用,标记为ServiceManger binder。
#define BINDER_THREAD_EXIT _IOW('b', 8, __s32) // 线程退出
#define BINDER_VERSION _IOWR('b', 9, struct binder_version) // 版本号
binder_ioctl 从整体上看不复杂,结构还是比较清晰的。在ioctl 最重要的函数是binder_ioctl_write_read,所有的binder 数据传输都在这里完成。这个我们放在后边分析。
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
if (unlikely(current->mm != proc->vma_vm_mm)) {
pr_err("current mm mismatch proc mm\n");
return -EINVAL;
}
trace_binder_ioctl(cmd, arg);
// binder_stop_on_user_error= 0 所以这里不阻塞
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
binder_lock(__func__);
// 获取用户态调用的线程的信息,并且加入到 binder_proc threads 的红黑树中。
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
case BINDER_SET_MAX_THREADS:
if (copy_from_user(&proc->max_threads, ubuf, sizeof(proc->max_threads))) {
ret = -EINVAL;
goto err;
}
break;
case BINDER_SET_CONTEXT_MGR:
ret = binder_ioctl_set_ctx_mgr(filp);
if (ret)
goto err;
break;
case BINDER_THREAD_EXIT:
binder_debug(BINDER_DEBUG_THREADS, "%d:%d exit\n",
proc->pid, thread->pid);
binder_free_thread(proc, thread);
thread = NULL;
break;
case BINDER_VERSION: {
struct binder_version __user *ver = ubuf;
if (size != sizeof(struct binder_version)) {
ret = -EINVAL;
goto err;
}
if (put_user(BINDER_CURRENT_PROTOCOL_VERSION,
&ver->protocol_version)) {
ret = -EINVAL;
goto err;
}
break;
}
default:
ret = -EINVAL;
goto err;
}
ret = 0;
err:
// 标记 thread looper 的状态
if (thread)
thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN;
binder_unlock(__func__);
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret && ret != -ERESTARTSYS)
pr_info("%d:%d ioctl %x %lx returned %d\n", proc->pid, current->pid, cmd, arg, ret);
err_unlocked:
trace_binder_ioctl_done(ret);
return ret;
}
ServiceManger 与驱动的交互
ServiceManger 中一次调用了下面四个函数,前面已经分析了内核中这几个API,那看下这几次调用到底做了什么工作。
- open("/dev/binder", ORDWR | OCLOEXEC)
- ioctl(bs->fd, BINDER_VERSION, &vers)
- mmap(NULL, mapsize, PROTREAD, MAPPRIVATE, bs->fd, 0)
- ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0);
- ioctl(bs->fd, BINDER_WRITE_READ, &bwr); bwr 数据中有 BC_ENTER_LOOPER
- ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
open
open 函数计较简单,在上面的分析中在open 建立 binder_proc 双向链表,初始化进程相关的信息,初始化红黑树。
ioctl BINDER_VERSION
第一次调用 ioctl, 命令字为:BINDER_VERSION
case BINDER_VERSION: {
struct binder_version __user *ver = ubuf;
if (size != sizeof(struct binder_version)) {
ret = -EINVAL;
goto err;
}
if (put_user(BINDER_CURRENT_PROTOCOL_VERSION,
&ver->protocol_version)) {
ret = -EINVAL;
goto err;
}
break;
把内核中的Binder Version 放到传递到内核空间的用户空间地址中。用户空间可以判断下版本号是否一致。
mmap
在 mmap 中分配虚拟空间地址,分配一个页大小的物理空间,建立内核空间地址和用户控件地址的映射
ioctl BINDER_SET_CONTEXT_MGR
case BINDER_SET_CONTEXT_MGR:
ret = binder_ioctl_set_ctx_mgr(filp);
if (ret)
goto err;
break;
binder_ioctl_set_ctx_mgr 干了一件事情, binder_new_node, 注意最后的两个参数是0,0.
- binder_new_node首先在binder_proc 的nodes 函数中寻找合适的插入位置,由于是第一次调用,这时还没有任何的节点插入红黑树。
- kzalloc 分配binder_node 节点
- node 节点插入红黑树,
- node->debug_id = ++binder_last_id; 注意 binder_last_id 为全局静态变量,所以 node->debug_id = 1;
- prt 和cook 域复制,都是0。0代表ServiceManager.
到这里,binder 驱动的第一个binder_node 节点建立起来
static int binder_ioctl_set_ctx_mgr(struct file *filp)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
kuid_t curr_euid = current_euid();
......
binder_context_mgr_node = binder_new_node(proc, 0, 0);
if (binder_context_mgr_node == NULL) {
ret = -ENOMEM;
goto out;
}
binder_context_mgr_node->local_weak_refs++;
binder_context_mgr_node->local_strong_refs++;
binder_context_mgr_node->has_strong_ref = 1;
binder_context_mgr_node->has_weak_ref = 1;
out:
return ret;
}
static struct binder_node *binder_new_node(struct binder_proc *proc,
binder_uintptr_t ptr,
binder_uintptr_t cookie)
{
struct rb_node **p = &proc->nodes.rb_node;
struct rb_node *parent = NULL;
struct binder_node *node;
// 第一调用这个函数, binder_proc 的node 节点为空,还没有node *p== null
while (*p) {
parent = *p;
node = rb_entry(parent, struct binder_node, rb_node);
if (ptr < node->ptr)
p = &(*p)->rb_left;
else if (ptr > node->ptr)
p = &(*p)->rb_right;
else
return NULL;
}
node = kzalloc(sizeof(*node), GFP_KERNEL);
if (node == NULL)
return NULL;
binder_stats_created(BINDER_STAT_NODE);
rb_link_node(&node->rb_node, parent, p);
rb_insert_color(&node->rb_node, &proc->nodes);
node->debug_id = ++binder_last_id;
node->proc = proc;
node->ptr = ptr;
node->cookie = cookie;
node->work.type = BINDER_WORK_NODE;
INIT_LIST_HEAD(&node->work.entry);
INIT_LIST_HEAD(&node->async_todo);
return node;
}
ioctl BINDER_WRITE_READ 和 BC_ENTER_LOOPER
在这次调用中还是来到了我们前面跳过的binder_ioctl_write_read函数。
ServiceManager 调用
首先看下调用的代码,注意bwr.write_buffer 所指区域的数据 readbuf[0] = BC_ENTER_LOOPER;
{
uint32_t readbuf[32];
readbuf[0] = BC_ENTER_LOOPER;
binder_write(bs, readbuf, sizeof(uint32_t));
}
int binder_write(struct binder_state *bs, void *data, size_t len)
{
struct binder_write_read bwr;
int res;
bwr.write_size = len;
bwr.write_consumed = 0;
bwr.write_buffer = (uintptr_t) data;
bwr.read_size = 0;
bwr.read_consumed = 0;
bwr.read_buffer = 0;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
return res;
}
binder_ioctl_write_read
binder ioctl 进入内核,获取当前线程的结构体 binder_thread;
thread = binder_get_thread(proc);
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (bwr.read_size > 0) {
......
}
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
binder_ioctl_write_read 中
- copy_from_user 把binder_write_read 结构体从用户空间copy 进来。
- bwr.write_size > 0 并且 bwr.read_size ==0. 来到了binder_thread_write。
- while 循环,每次从用户空间中读取一个 int 大小的数据,实际是从 调用的 uint32_t readbuf[32] 中读取,只有 readbuf[0]= BC_ENTER_LOOPER。
- 和线程操作相关的cmd 一共三个,所有的操作都是对 binder_thread looper |= 操作。标记对应的线程状态。
- binder_ioctl_write_read 返回, ioctl 返回。所以这一步无阻塞。
binder_thread loop 标记
| cmd | 功能 | loop enum |
|---|---|---|
| BC_REGISTER_LOOPER | 代理线程注册looper | BINDER_LOOPER_STATE_REGISTERED = 0x01 |
| BC_ENTER_LOOPER | 主线程循环 | BINDER_LOOPER_STATE_ENTERED = 0x02 |
| BC_EXIT_LOOPER | 线程退出 | BINDER_LOOPER_STATE_EXITED = 0x04 |
| BINDER_LOOPER_STATE_INVALID = 0x08 | ||
| BINDER_LOOPER_STATE_WAITING = 0x10 | ||
| BINDER_LOOPER_STATE_NEED_RETURN = 0x20 |
binder_thread_write
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
trace_binder_command(cmd);
if (_IOC_NR(cmd) < ARRAY_SIZE(binder_stats.bc)) {
binder_stats.bc[_IOC_NR(cmd)]++;
proc->stats.bc[_IOC_NR(cmd)]++;
thread->stats.bc[_IOC_NR(cmd)]++;
}
switch (cmd) {
......
case BC_REGISTER_LOOPER:
if (thread->looper & BINDER_LOOPER_STATE_ENTERED) {
thread->looper |= BINDER_LOOPER_STATE_INVALID;
} else if (proc->requested_threads == 0) {
thread->looper |= BINDER_LOOPER_STATE_INVALID;
proc->pid, thread->pid);
} else {
proc->requested_threads--;
proc->requested_threads_started++;
}
thread->looper |= BINDER_LOOPER_STATE_REGISTERED;
break;
case BC_ENTER_LOOPER:
if (thread->looper & BINDER_LOOPER_STATE_REGISTERED) {
thread->looper |= BINDER_LOOPER_STATE_INVALID;
}
thread->looper |= BINDER_LOOPER_STATE_ENTERED;
break;
case BC_EXIT_LOOPER:
thread->looper |= BINDER_LOOPER_STATE_EXITED;
break;
......
default:
return -EINVAL;
}
*consumed = ptr - buffer;
}
return 0;
}
总结: ioctl BC_ENTER_LOOPER 就是标记红黑树中的binder_thread 的状态。
ioctl(bs->fd, BINDER_WRITE_READ, &bwr)
ServiceManger 调用
再看下这步的调用代码, (binder_write 里面好像定义过binder_write_read,这段代码是不是可以复用呢,总是能看到这样需要改进的神奇代码), 这次binder_write_read的bwr.read_size > 0 进入了读模式。
struct binder_write_read bwr;
uint32_t readbuf[32];
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
readbuf[0] = BC_ENTER_LOOPER;
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) {
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
binder_ioctl_write_read
binder_ioctl-> binder_ioctl_write_read -> binder_thread_read
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
if (bwr.write_size > 0) {
......
}
if (bwr.read_size > 0) {
// 调用open 的时候没有设置O_NONBLOCK 标记,filp->f_flags & O_NONBLOCK == 0
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
if (!list_empty(&proc->todo))
wake_up_interruptible(&proc->wait);
if (ret < 0) {
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
out:
return ret;
}
binder_thread_read
binder_thread_read 阻塞 wait_event_freezable_exclusive, 这时候ServiceManager 进入阻塞状态
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
int ret = 0;
int wait_for_proc_work;
if (*consumed == 0) {
if (put_user(BR_NOOP, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
}
retry:
// 第一次进来 transaction_stack == null, todo链表也为空,wait_for_proc_work = true
wait_for_proc_work = thread->transaction_stack == NULL &&
list_empty(&thread->todo);
// 线程状态
thread->looper |= BINDER_LOOPER_STATE_WAITING;
// ready_threads 计数加一 这里是1, 表示一个等待线程
if (wait_for_proc_work)
proc->ready_threads++;
binder_unlock(__func__);
if (wait_for_proc_work) {
if (!(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED))) {
proc->pid, thread->pid, thread->looper);
wait_event_interruptible(binder_user_error_wait,
binder_stop_on_user_error < 2);
}
binder_set_nice(proc->default_priority);
if (non_block) {
if (!binder_has_proc_work(proc, thread))
ret = -EAGAIN;
} else
// 代码会来到这里阻塞 ,binder_has_proc_work 判断 todo 队列是否为空,为空则阻塞
ret = wait_event_freezable_exclusive(proc->wait, binder_has_proc_work(proc, thread));
} else {
if (non_block) {
if (!binder_has_thread_work(thread))
ret = -EAGAIN;
} else
ret = wait_event_freezable(thread->wait, binder_has_thread_work(thread));
}
......
}
