urllib库是Python中一个最基本的网络请求库。可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据
urlopen函数
在Python3的urllib库中,所有和网络请求相关的方法,都被集到urllib.request模块下面了
urlopen函数基本的使用
- url:请求的url
- data:请求的data,如果设置了这个值,那么将变成post请求
- 返回值:返回值是一个http.client.HTTPResponse对象,这个对象是一个类文件句柄对象,有read(size)、readline、readlines以及getcode等方法
from urllib import request
resp = request.urlopen('http://www.baidu.com')
print(resp.read())
- 这个时候,通过浏览器访问百度,右击检查源代码,会发现和打印的数据是一样的
urlretrieve函数
这个函数可以方便的将网页上的一个文件保存到本地,把百度首页保存在本地
from urllib import request
request.urlretrieve('http://www.baidu.com/','baidu.html')
或者想下载百度上的图片,直接复制图片地址,第二个参数是在本地的名字
urlencode函数和parse_qs函数
- 用浏览器发送请求的时候,如果url中包含了中文或者其他特殊字符,那么浏览器会自动的给我们进行编码。而如果使用代码发送请求,那么就必须手动的进行编码,这时候就应该使用urlencode函数来实现。
urlencode可以把字典数据转换为URL编码的数据 - 可以将经过编码后的url参数进行解码
from urllib import request,parse
data = {'name':'爬虫','age':18,'text':'hello world'}
qs = parse.urlencode(data) # 编码
print(qs)
print(parse.parse_qs(qs)) # 解码
# name=%E7%88%AC%E8%99%AB&age=18&text=hello+world
# {'name': ['爬虫'], 'age': ['18'], 'text': ['hello world']}
- 比如在百度上搜索
https://www.baidu.com/s?wd=李宗盛,这直接复制到地址栏就可以了,但是使用python请求的话,中文就得手动编码
# https://www.baidu.com/s?wd=李宗盛
url = 'https://www.baidu.com/s'
params = {'wd':'李宗盛'}
qs = parse.urlencode(params)
url = url + '?' + qs
print(url)
# https://www.baidu.com/s?wd=%E6%9D%8E%E5%AE%97%E7%9B%9B
resp = request.urlopen(url)
print(resp.read()) # 这样就获取到了源代码
# 把这个复制到地址栏也可以进行搜索,因为浏览器自动编码解码,
# 若想到这是什么意思,我们可以手动的解码
print(parse.parse_qs(url))
# {'https://www.baidu.com/s?wd': ['李宗盛']}
urlparse和urlsplit
有时候拿到一个url,想要对这个url中的各个组成部分进行分割,那么这时候就可以使用urlparse或者是urlsplit来进行分割
from urllib import request,parse
url = 'https://study.163.com/course/courseLearn.htm?courseId=378003#/learn/video?lessonId=495018&courseId=378003'
result1 = parse.urlsplit(url)
result2 = parse.urlparse(url)
print(result1)
# SplitResult(scheme='https', netloc='study.163.com', path='/course/courseLearn.htm', query='courseId=378003', fragment='/learn/video?lessonId=495018&courseId=378003')
print(result2)
# ParseResult(scheme='https', netloc='study.163.com', path='/course/courseLearn.htm', params='', query='courseId=378003', fragment='/learn/video?lessonId=495018&courseId=378003')
# 想获取某一个属性
print('协议:'+result1.scheme)
print('网址:'+result1.netloc)
print('路径:'+result1.path)
print('参数:'+result1.query)
-
urlparse和urlsplit基本上是一模一样的。唯一不一样的地方是,urlparse里面多了一个params属性,而urlsplit没有这个params属性 - 比如有一个url为:
url = 'http://www.baidu.com/s;hello?wd=python&username=abc#1',
那么urlparse可以获取到hello,而urlsplit不可以获取到。url中的params也用得比较少
request.Request类
如果想要在请求的时候增加一些请求头,那么就必须使用request.Request类来实现。比如要增加一个User-Agent
from urllib import request,parse
url = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
# lagou用普通的方法获取不到数据
resp = request.urlopen(url)
print(resp.read())
- 在这里加入浏览器标识
#encoding: utf-8
from urllib import request,parse
url = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
}
req = request.Request(url,headers=headers)
# 这里传入的是加入标识的
resp = request.urlopen(req)
print(resp.read())
- 此时就可以获取到这一页的数据了
模拟拉钩,查询一页信息
因为拉钩网用的是Ajax,所以还要进行分析,例如搜索python,首先找到后台请求Ajax的,然后分析它的网址,请求方式,以及Form Data
拉钩一页.gif
#encoding: utf-8
from urllib import request,parse
# 对应的Ajax请求的地址
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 添加一些信息头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36',
'Referer':'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
}
# 要传递的数据,看着上面的写
data = {
'first':'true',
'pn':1,
'kd':'python'
}
# 注意,此时的data数据要进行编码,然后转化为utf-8
req = request.Request(url,headers=headers,data=parse.urlencode(data).encode('utf-8'),method='POST')
resp = request.urlopen(req)
# 对得到的数据进行解码
print(resp.read().decode('utf-8'))
-
此时的Request()方法中传入的参数分别是,url,信息头,经过编码的数据,以及请求方式
拉钩一页的数据.gif
ProxyHandler处理器(代理设置)
我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取,urllib中通过ProxyHandler来设置使用代理服务器
-
https://httpbin.org/get查看自己请求的参数 - 在代码中使用代理
- 使用ProxyHandler,传入一个代理的ip,建立handler,这个代理是一个字典
- 使用上面的handler,以及
request.build_opener构建一个opener - 使用opener去发送一个请求,调用open函数
- 代理IP:
https://www.kuaidaili.com
#encoding: utf-8
from urllib import request
# 没有使用代理
# resp = request.urlopen('http://httpbin.org/get')
# print(resp.read().decode('utf-8'))
# 使用代理
# 1.使用ProxyHandler,传入一个代理的ip,建立handler
handler = request.ProxyHandler({'http':'117.90.5.152:9000'})
# 2.使用上面的handler构建一个opener
opener = request.build_opener(handler)
req = request.Request('http://httpbin.org/ip')
# 3.使用opener去发送一个请求
resp = opener.open(req)
print(resp.read())
cookie实现模拟登陆
- 什么是cokie
- 在网站中,http请求是无状态的。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户
- cookie的出现就是为了解决这个问题,第一次登录后服务器返回一些数据(cookie)给浏览器,然后浏览器保存在本地,当该用户发送第二次请求的时候,就会自动的把上次请求存储的cookie数据自动的携带给服务器,服务器通过浏览器携带的数据就能判断当前用户是哪个了
- cookie存储的数据量有限,不同的浏览器有不同的存储大小,但一般不超过4KB。因此使用cookie只能存储一些小量的数据
- cookie的格式
Set-Cookie: NAME=VALUE;Expires/Max-age=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE- NAME:cookie的名字
- VALUE:cookie的值
- Expires:cookie的过期时间
- Path:cookie作用的路径
- Domain:cookie作用的域名
- SECURE:是否只在https协议下起作用
第一种方案 简单粗暴
- 这里以人人网为例。人人网中,要访问某个人的主页,必须先登录才能访问,就是要有cookie信息,那么如果我们想要用代码的方式访问,就必须要有正确的cookie信息才能访问
- 如何获取cookie信息呢,这个时候我们时候浏览器登陆,然后找到cookie信息,复制下
#encoding: utf-8
from urllib import request,parse
# 写入我们复制的cookie信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36',
'Cookie': 'anonymid=jfs1i5li-ie82t9; depovince=ZGQT; _r01_=1; ick_login=b6e8ac34-2089-49fe-9340-3fe1e935b755; t=44d166666e938d4fe0a618f857412aaa3; societyguester=44d166666e938d4fe0a618f857412aaa3; id=963676363; xnsid=56399218; jebecookies=df0c1ec4-5568-4b34-bd2d-d2f069f2e109|||||; JSESSIONID=abcm3bFI8F05W6t2MXPkw; ch_id=10016; wp_fold=0'
}
# 打开想要进入的主页
url = 'http://www.renren.com/880151247/profile'
req = request.Request(url,headers=headers)
resp = request.urlopen(req)
# 把获取到的主页写入到html中
# 这里指定的utf-8是文件打开的格式
with open('renren.html','w',encoding='utf-8') as fp:
fp.write(resp.read().decode('utf-8'))
- 注意:
- 此时文件是指定的utf-8打开
- 由于此时write必须写入一个String类型的数据,resp.read()返回的是一个bytes类型的,所以到使用decode('utf-8')
- 字符的转换
- bytes -- > decode -- > str
- str -- > encode -- > bytes
- 但是每次在访问需要cookie的页面都要从浏览器中复制cookie比较麻烦
第二种方案 使用http.cookiejar和request.HTTPCookieProcessor模块
Cookie 是指网站服务器为了辨别用户身份和进行Session跟踪,而储存在用户浏览器上的文本文件,Cookie可以保持登录信息到用户下次与服务器的会话
-
http.cookiejar模块主要作用是提供用于存储cookie的对象,该模块主要的类有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar- CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失
- FileCookieJar (filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问访问文件,即只有在需要时才读取文件或在文件中存储数据
- MozillaCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与Mozilla浏览器 cookies.txt兼容的FileCookieJar实例
- LWPCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与libwww-perl标准的 Set-Cookie3 文件格式兼容的FileCookieJar实例
-
request.HTTPCookieProcessor处理器主要作用是处理这些cookie对象,并构建handler对象 - 使用这种方式登陆人人网
-
首先分析网页,得到登陆时数据传递的网址
 登陆时的网址.png
登陆时的网址.png -
分析要传递的数据
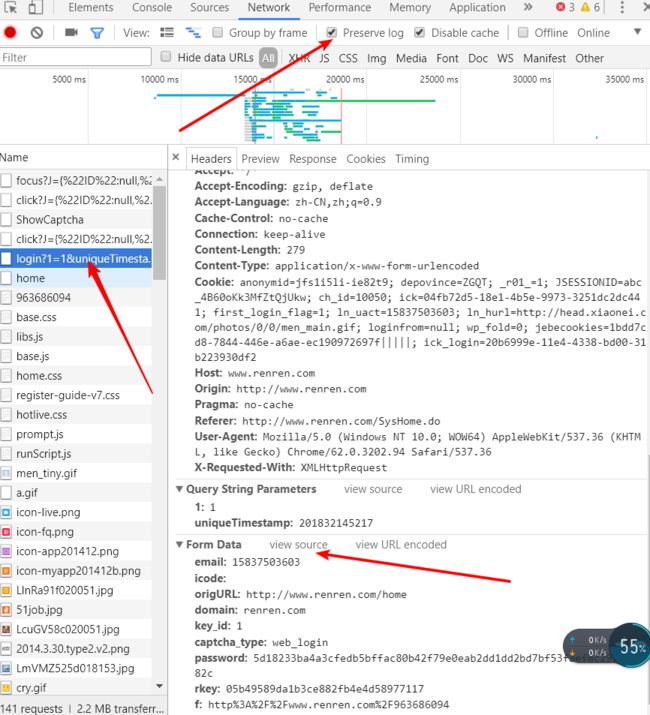 查看登陆时候的参数.png
查看登陆时候的参数.png
-
#encoding: utf-8
from urllib import request,parse
from http.cookiejar import CookieJar
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
}
url = 'http://www.renren.com/880151247/profile'
def get_opener():
cookiejar = CookieJar()
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
return opener
def login_renren(opener):
data = {'email':'15837503603','password':'2110198860'}
data = parse.urlencode(data).encode('utf-8')
login_url = 'http://www.renren.com/PLogin.do'
req = request.Request(login_url,headers=headers,data=data)
opener.open(req)
def visit_profile(opener):
url = 'http://www.renren.com/880151247/profile'
req = request.Request(url,headers=headers)
resp = opener.open(req)
with open('renren.html','w',encoding='utf-8') as fp:
fp.write(resp.read().decode('utf-8'))
if __name__ == '__main__':
opener = get_opener()
login_renren(opener)
visit_profile(opener)
- 这样就可以获取到源码了