

下游分析
cellranger count 计算的结果只能作为错略观测的结果,如果需要进一步分析聚类细胞,还需要进行下游分析,这里使用官方推荐 R 包(Seurat 3.0)
流程参考官方外周血分析标准流程(https://satijalab.org/seurat/v3.0/pbmc3k_tutorial.html)
Rstudio操作过程:
##安装seurat
install.packages('Seurat')
##载入seurat包
library(dplyr)
library(Seurat)
##读入pbmc数据(文件夹路径不能包含中文,注意“/“的方向不能错误,这里读取的是10x处理的文件,也可以处理其它矩阵文件,具体怎样操作现在还不知道,文件夹中的3个文件分别是:barcodes.tsv,genes.tsv,matrix.mtx,文件的名字不能错,否则读取不到)
pbmc.data <- Read10X(data.dir = "D:/pbmc3k_filtered_gene_bc_matrices/filtered_gene_bc_matrices/hg19/")
##查看稀疏矩阵的维度,即基因数和细胞数
dim(pbmc.data)
pbmc.data[1:10,1:6]
##创建Seurat对象与数据过滤,除去一些质量差的细胞(这里读取的是单细胞 count 结果中的矩阵目录;在对象生成的过程中,做了初步的过滤;留下所有在>=3 个细胞中表达的基因 min.cells = 3;留下所有检测到>=200 个基因的细胞 min.genes = 200。)
pbmc <- CreateSeuratObject(counts = pbmc.data, project = "pbmc3k", min.cells = 3, min.features = 200)
pbmc
##计算每个细胞的线粒体基因转录本数的百分比(%),使用[[ ]] 操作符存放到metadata中,mit-开头的为线粒体基因
pbmc[["percent.mt"]] <- PercentageFeatureSet(pbmc, pattern = "^MT-")
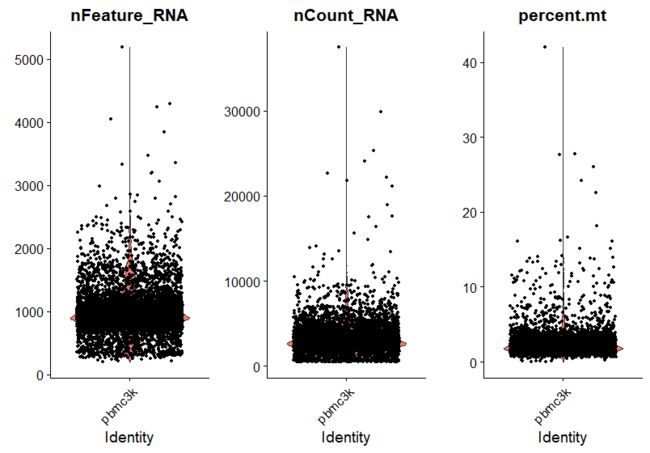
##展示基因及线粒体百分比(这里将其进行标记并统计其分布频率,"nFeature_RNA"为基因数,"nCount_RNA"为细胞数,"percent.mt"为线粒体占比)
VlnPlot(pbmc, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3)
plot1 <- FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "percent.mt")
plot2 <- FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "nFeature_RNA")
CombinePlots(plots = list(plot1, plot2))
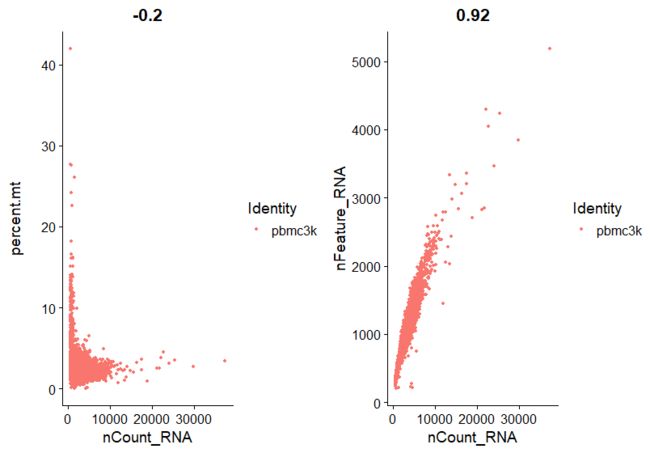
##过滤细胞:根据上面小提琴图中基因数"nFeature_RNA"和线粒体数"percent.mt",分别设置过滤参数,这里基因数 200-2500,线粒体百分比为小于 5%,保留gene数大于200小于2500的细胞;目的是去掉空GEMs和1个GEMs包含2个以上细胞的数据;而保留线粒体基因的转录本数低于5%的细胞,为了过滤掉死细胞等低质量的细胞数据。
pbmc <- subset(pbmc, subset = nFeature_RNA > 200 & nFeature_RNA < 2500 & percent.mt < 5)
##表达量数据标准化,LogNormalize的算法:A = log( 1 + ( UMIA ÷ UMITotal ) × 10000
pbmc <- NormalizeData(pbmc, normalization.method = "LogNormalize", scale.factor = 10000)
#pbmc <- NormalizeData(pbmc) 或者用默认的
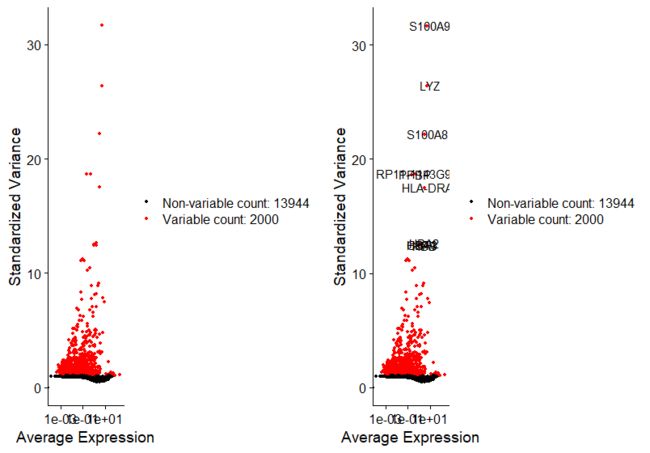
##鉴定表达高变基因(2000个),用于下游分析,如PCA;
pbmc <- FindVariableFeatures(pbmc, selection.method = "vst", nfeatures = 2000)
##提取表达量变化最高的10个基因;
top10 <- head(VariableFeatures(pbmc), 10)
top10
plot1 <- VariableFeaturePlot(pbmc)
plot2 <- LabelPoints(plot = plot1, points = top10)
CombinePlots(plots = list(plot1, plot2))
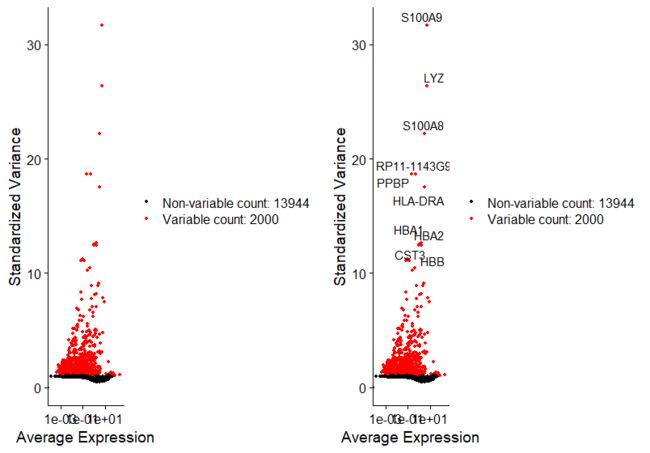
plot1<-VariableFeaturePlot(object=pbmc)
plot2<-LabelPoints(plot=plot1,points=top10,repel=TRUE)
CombinePlots(plots=list(plot1,plot2))
##PCA分析:
#PCA分析数据准备,使用ScaleData()进行数据归一化;默认只是标准化高变基因(2000个),速度更快,不影响PCA和分群,但影响热图的绘制。
#pbmc <- ScaleData(pbmc,vars.to.regress ="percent.mt")
##而对所有基因进行标准化的方法如下:
all.genes <- rownames(pbmc)
pbmc <- ScaleData(pbmc, features = all.genes)
pbmc <- ScaleData(pbmc, vars.to.regress = "percent.mt")
##线性降维(PCA),默认用高变基因集,但也可通过features参数自己指定;
pbmc <- RunPCA(pbmc, features = VariableFeatures(object = pbmc))
##展示 pca 结果(最简单的方法)
DimPlot(object=pbmc,reduction="pca")
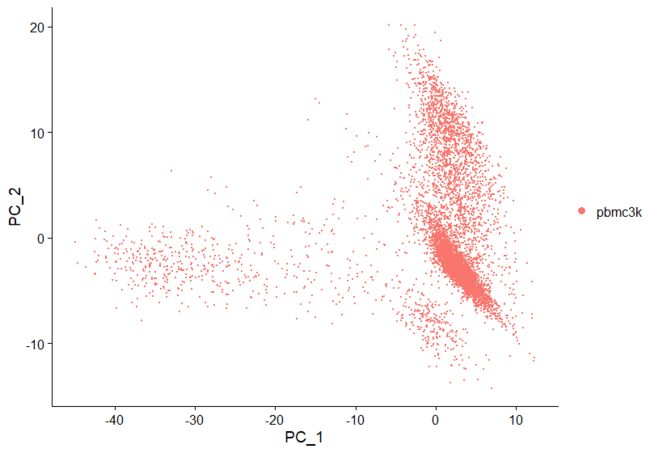
##检查PCA分群结果, 这里只展示前5个PC,每个PC只显示5个基因;
print(pbmc[["pca"]], dims = 1:5, nfeatures = 5)
##PC_ 1
##Positive: RPS27, MALAT1, RPS6, RPS12, RPL13
##Negative: CSTA, FCN1, CST3, LYZ, LGALS2
##PC_ 2
##Positive: NKG7, GZMA, CST7, KLRD1, CCL5
##Negative: RPL34, RPL32, RPL13, RPL39, LTB
##PC_ 3
##Positive: MS4A1, CD79A, BANK1, IGHD, CD79B
##Negative: IL7R, RPL34, S100A12, VCAN, AIF1
##PC_ 4
##Positive: RPS18, RPL39, RPS27, MALAT1, RPS8
##Negative: PPBP, PF4, GNG11, SDPR, TUBB1
##PC_ 5
##Positive: PLD4, FCER1A, LILRA4, SERPINF1, LRRC26
##Negative: MS4A1, CD79A, LINC00926, IGHD, FCER2
##展示主成分基因分值
VizDimLoadings(pbmc, dims = 1:2, reduction = "pca")

##绘制pca散点图
DimPlot(pbmc, reduction = "pca")
##画第1个或15个主成分的热图;
DimHeatmap(pbmc, dims = 1, cells = 500, balanced = TRUE)
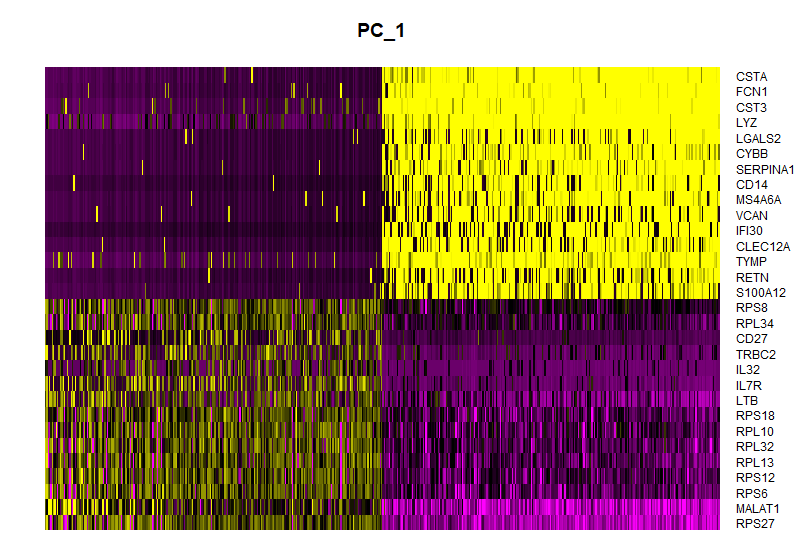
DimHeatmap(pbmc, dims = 1:15, cells = 500, balanced = TRUE)

##确定数据集的分群个数
#鉴定数据集的可用维度,方法1:Jackstraw置换检验算法;重复取样(原数据的1%),重跑PCA,鉴定p-value较小的PC;计算‘null distribution’(即零假设成立时)时的基因scores。虚线以上的为可用维度,也可以调整 dims 参数,画出所有 pca 查看。
#pbmc <- JackStraw(pbmc, num.replicate = 100)
#pbmc <- ScoreJackStraw(pbmc, dims = 1:20)
#JackStrawPlot(pbmc, dims = 1:15)

#方法2:肘部图(碎石图),基于每个主成分对方差解释率的排名。
ElbowPlot(pbmc)
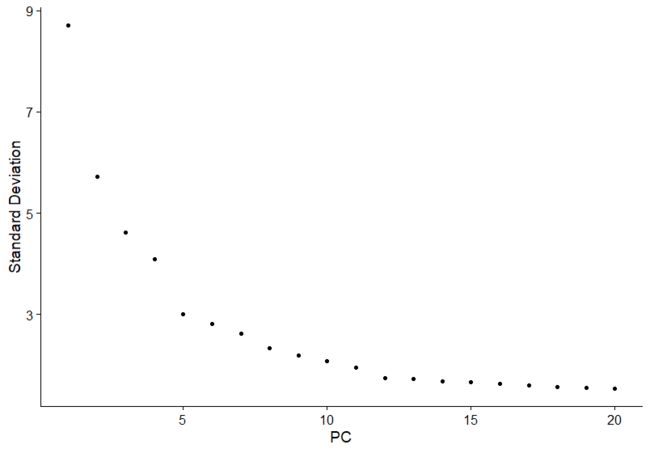
##细胞聚类:分群个数这里选择10,建议尝试选择多个主成分个数做下游分析,对整体影响不大;在选择此参数时,建议选择偏高的数字(为了获取更多的稀有分群,“宁滥勿缺”);有些亚群很罕见,如果没有先验知识,很难将这种大小的数据集与背景噪声区分开来。
##非线性降维(UMAP/tSNE)基于PCA空间中的欧氏距离计算nearest neighbor graph,优化任意两个细胞间的距离权重(输入上一步得到的PC维数)。
pbmc <- FindNeighbors(pbmc, dims = 1:10)
##接着优化模型,resolution参数决定下游聚类分析得到的分群数,对于3K左右的细胞,设为0.4-1.2 能得到较好的结果(官方说明);如果数据量增大,该参数也应该适当增大。
pbmc <- FindClusters(pbmc, resolution = 0.5)
##使用Idents()函数可查看不同细胞的分群;
head(Idents(pbmc), 5)
##结果:AAACCTGAGGTGCTAG AAACCTGCAGGTCCAC AAACCTGCATGGAATA AAACCTGCATGGTAGG AAACCTGCATTGGCGC
1 3 0 10 2
Levels: 0 1 2 3 4 5 6 7 8 9 10 11
##Seurat提供了几种非线性降维的方法进行数据可视化(在低维空间把相似的细胞聚在一起),比如UMAP和t-SNE,运行UMAP需要先安装'umap-learn'包,这里不做介绍,两种方法都可以使用,但不要混用,如果混用,后面的结算结果会将先前的聚类覆盖掉,只能保留一个。
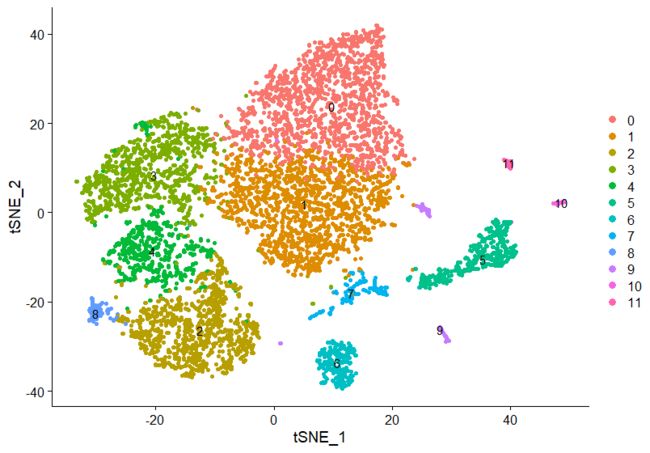
##这里采用基于TSNE的聚类方法。
pbmc <- RunTSNE(pbmc, dims = 1:10)
##用DimPlot()函数绘制散点图,reduction = "tsne",指定绘制类型;如果不指定,默认先从搜索 umap,然后 tsne, 再然后 pca;也可以直接使用这3个函数PCAPlot()、TSNEPlot()、UMAPPlot(); cols,pt.size分别调整分组颜色和点的大小;
DimPlot(pbmc,reduction = "tsne",label = TRUE,pt.size = 1.5)
##这里采用基于图论的聚类方法
pbmc<-RunUMAP(object=pbmc,dims=1:10)
DimPlot(object=pbmc,reduction="umap")
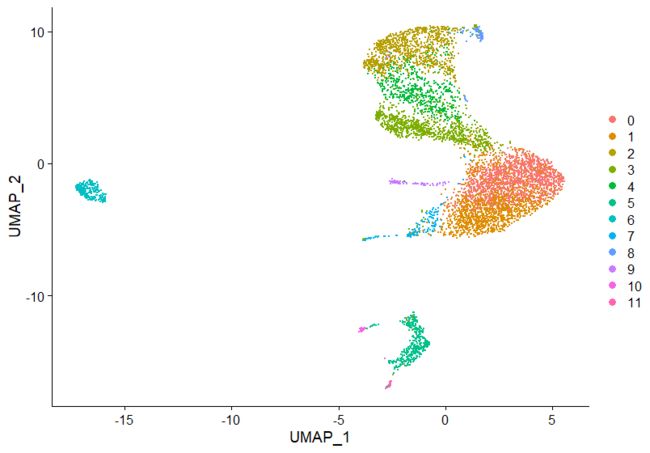
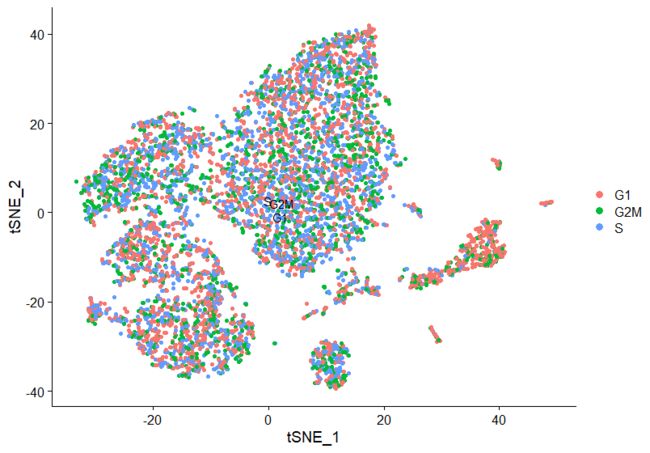
##细胞周期归类
pbmc<- CellCycleScoring(object = pbmc, g2m.features = cc.genes$g2m.genes, s.features = cc.genes$s.genes)
head(x = [email protected])
DimPlot(pbmc,reduction = "tsne",label = TRUE,group.by="Phase",pt.size = 1.5)
##存储结果
saveRDS(pbmc, file = "D:/pbmc_tutorial.rds")
save(pbmc,file="D:/res0.5.Robj")
##寻找cluster 1的marker
cluster1.markers <- FindMarkers(pbmc, ident.1 = 1, min.pct = 0.25)
head(cluster1.markers, n = 5)
##结果: p_val avg_logFC pct.1 pct.2 p_val_adj
MT-CO1 0.000000e+00 -0.6977083 0.985 0.996 0.000000e+00
RPS27 2.182766e-282 0.3076454 1.000 0.999 3.480202e-278
MT-CO3 2.146399e-274 -0.4866429 0.995 0.997 3.422218e-270
DUSP1 2.080878e-247 -1.7621662 0.376 0.745 3.317752e-243
RPL34 8.647733e-244 0.3367755 1.000 0.997 1.378795e-239
##寻找每一cluster的marker
pbmc.markers <- FindAllMarkers(pbmc, only.pos = TRUE, min.pct = 0.25, logfc.threshold = 0.25)
pbmc.markers %>% group_by(cluster) %>% top_n(n = 2, wt = avg_logFC)
# A tibble: 24 x 7
# Groups: cluster [12]
p_val avg_logFC pct.1 pct.2 p_val_adj cluster gene
1 2.29e-123 0.636 0.344 0.097 3.65e-119 0 CD8B
2 7.62e-113 0.487 0.632 0.305 1.22e-108 0 LEF1
3 2.04e- 74 0.483 0.562 0.328 3.25e- 70 1 LEF1
4 1.39e- 61 0.462 0.598 0.39 2.22e- 57 1 ITM2A
5 0. 2.69 0.972 0.483 0. 2 GNLY
6 0. 2.40 0.964 0.164 0. 2 GZMB
7 1.31e-121 0.768 0.913 0.671 2.09e-117 3 JUNB
8 2.06e- 94 0.946 0.426 0.155 3.28e- 90 3 RGS1
9 2.05e-255 1.57 0.586 0.09 3.27e-251 4 GZMK
10 2.94e-140 1.57 0.69 0.253 4.68e-136 4 KLRB1
# ... with 14 more rows
##存储marker
write.table(pbmc.markers,file="D:/allmarker.txt")
##各种绘图
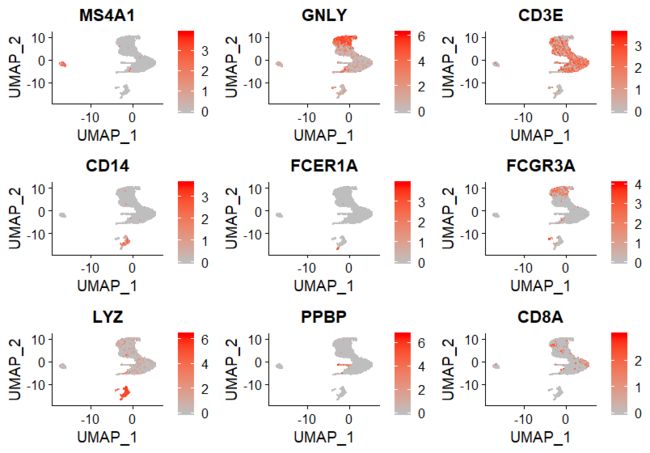
##绘制Marker 基因的tsne图
FeaturePlot(pbmc, features = c("MS4A1", "GNLY", "CD3E", "CD14", "FCER1A", "FCGR3A", "LYZ", "PPBP", "CD8A"),cols = c("gray", "red"))
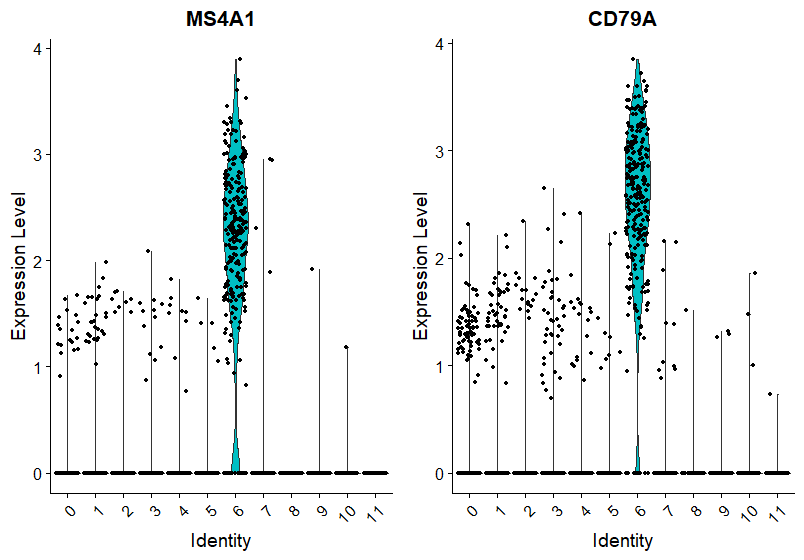
##绘制Marker 基因的小提琴图
VlnPlot(pbmc, features = c("MS4A1", "CD79A"))
VlnPlot(pbmc, features = c("NKG7", "PF4"), slot = "counts", log = TRUE)
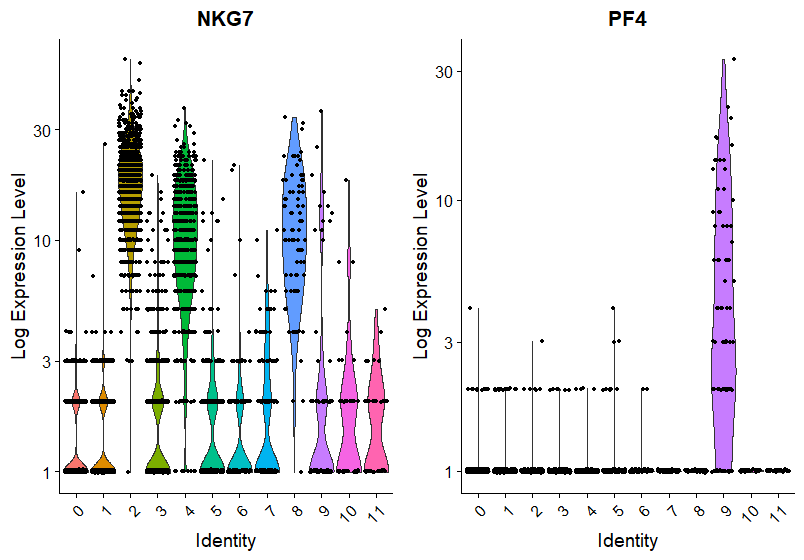
##绘制分cluster的热图
top10 <- pbmc.markers %>% group_by(cluster) %>% top_n(n = 10, wt = avg_logFC)
DoHeatmap(pbmc, features = top10$gene) + NoLegend()
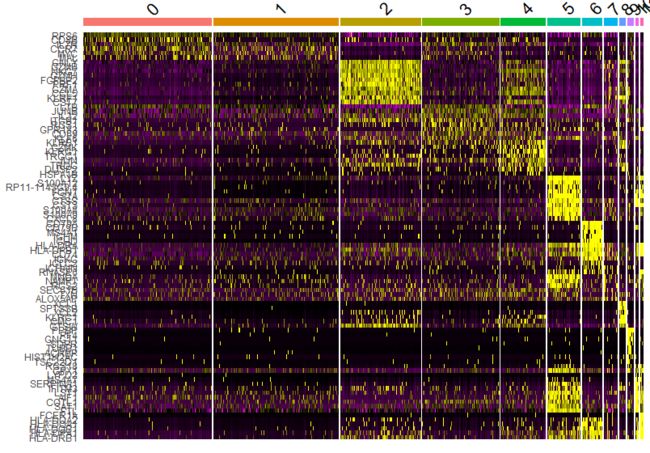
剩下的便是寻找基因 marker 并对细胞类型进行注释(见下回分解)