来源-原文:https://github.com/leisurelicht/wtfpython-cn#structure-of-the-examples%E7%A4%BA%E4%BE%8B%E7%BB%93%E6%9E%84
为自己整理一下【笔记】
字符串
这些行为是由于 Cpython 在编译优化时, 某些情况下会尝试使用已经存在的不可变对象而不是每次都创建一个新对象. **这种行为被称作字符串的驻留 **
发生驻留之后, 许多变量可能指向内存中的相同字符串对象. (从而节省内存)
隐式驻留的条件:
- 所有长度为 0 和长度为 1 的字符串都被驻留.
- 字符串在编译时被实现 (
'wtf'将被驻留, 但是''.join(['w', 't', 'f']将不会被驻留) - 字符串中只包含字母,数字或下划线时将会驻留. 所以
'wtf!'由于包含!而未被驻留. 可以在这里找到 CPython 对此规则的实现.
>>> a = "some_string"
>>> id(a)
140420665652016
>>> id("some" + "_" + "string") # 注意两个的id值是相同的.
140420665652016
>>> a = "wtf"
>>> b = "wtf"
>>> a is b
True
>>> a = "wtf!"
>>> b = "wtf!"
>>> a is b
False
>>> a, b = "wtf!", "wtf!"
>>> a is b
True
'''当在同一行将 a 和 b 的值设置为 "wtf!" 的时候, Python 解释器会创建一个新对象, 然后同时引用第二个变量. 如果你在不同的行上进行赋值操作, 它就不会“知道”已经有一个 wtf! 对象 (因为 "wtf!" 不是按照上面提到的方式被隐式驻留的). 它是一种编译器优化, 特别适用于交互式环境.'''
>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
True
>>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa'
False
'''
常量折叠(constant folding) 是 Python 中的一种 窥孔优化(peephole optimization) 技术. 这意味着在编译时表达式 'a'*20 会被替换为 'aaaaaaaaaaaaaaaaaaaa' 以减少运行时的时钟周期. 只有长度小于 20 的字符串才会发生常量折叠. (为啥? 想象一下由于表达式 'a'*10**10 而生成的 .pyc 文件的大小). 相关的源码实现在这里.
'''
python 中处理异常实例
def some_func():
try:
return 'from_try'
finally:
return 'from_finally'
== 和 is 的区别
Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
id 内存地址
== :比较.比较左右两侧的值,【内容,存的东西】
is :比较两侧的内存地址
class WTF:
pass
'''
Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
因为如果定义一个空类程序会报错,当你没有想好内容是可以用 pass 填充,使程序可以正常运行'''
Output:
>>> WTF() == WTF() # 两个不同的对象应该不相等
False
>>> WTF() is WTF() # 也不相同
False
>>> hash(WTF()) == hash(WTF()) # 哈希值也应该不同
True
>>> id(WTF()) == id(WTF())
True
'''
当调用 id 函数时, Python 创建了一个 WTF 类的对象并传给 id 函数. 然后 id 函数获取其id值 (也就是内存地址), 然后丢弃该对象. 该对象就被销毁了.
当我们连续两次进行这个操作时, Python会将相同的内存地址分配给第二个对象. 因为 (在CPython中) id 函数使用对象的内存地址作为对象的id值, 所以两个对象的id值是相同的.
综上, 对象的id值仅仅在对象的生命周期内唯一. 在对象被销毁之后, 或被创建之前, 其他对象可以具有相同的id值.
'''
-
那为什么
is操作的结果为False呢? 让我们看看这段代码.class WTF(object): def __init__(self): print("I") def __del__(self): print("D")Output:
>>> WTF() is WTF() I I D D False >>> id(WTF()) == id(WTF()) I D I D True正如你所看到的, 对象销毁的顺序是造成所有不同之处的原因.
>>> a = 256
>>> b = 256
>>> a is b
True
>>> a = 257
>>> b = 257
>>> a is b
False
'''
启动python时,-5到256之间的数值已经分配好了
'''
>>> a = 257; b = 257
>>> a is b
True
>>> a, b = 257, 257
>>> id(a)
140640774013296
>>> id(b)
140640774013296
'''
当 a 和 b 在同一行中被设置为 257 时, Python 解释器会创建一个新对象, 然后同时引用第二个变量. 如果你在不同的行上进行, 它就不会 "知道" 已经存在一个 257 对象了.
'''
>>> [] == []
True
>>> [] is [] # 这两个空列表位于不同的内存地址.
False
is not和 is (not) 和None
>>> 'something' is not None
True
>>> 'something' is (not None)
False
'''
如果操作符两侧的变量指向同一个对象, 则 is not 的结果为 False, 否则结果为 True
'''
None 引用自https://www.cnblogs.com/wangzhao2016/p/6763431.html
'''
在Python中,None、空列表[]、空字典{}、空元组()、0等一系列代表空和无的对象会被转换成False。除此之外的其它对象都会被转化成True。
'''
>>> class Foo(object):
def __eq__(self, other):
return True
>>> f = Foo()
>>> f == None
True
>>> f is None
False
not的使用
x = True
y = False
Output:
>>> not x == y
True
>>> x == not y
File "", line 1
x == not y
^
SyntaxError: invalid syntax
- 运算符的优先级会影响表达式的求值顺序, 而在 Python 中
==运算符的优先级要高于not运算符. - 所以
not x == y相当于not (x == y), 同时等价于not (True == False), 最后的运算结果就是True. - 之所以
x == not y会抛一个SyntaxError异常, 是因为它会被认为等价于(x == not) y, 而不是你一开始期望的x == (not y). - 解释器期望
not标记是not in操作符的一部分 (因为==和not in操作符具有相同的优先级), 但是它在not标记后面找不到in标记, 所以会抛出SyntaxError异常.
for & enumerate
some_string = "wtf"
some_dict = {}
for i, some_dict[i] in enumerate(some_string):
pass
'''
enumerate:提示得到下标和内容
'''
>>> some_dict # 创建了索引字典.
{0: 'w', 1: 't', 2: 'f'}
for i in range(4):
print(i)
i = 10
'''
这里i=10并不影响循环。在每次迭代开始之前, 迭代器(这里指 range(4)) 生成的下一个元素就被解包并赋值给目标列表的变量(这里指 i)了
'''
list count() 返回对象在list中出现的次数
执行时机的差异
array = [1, 8, 15]
g = (x for x in array if array.count(x) > 0)
#上述两个array的值是不一样的
array = [2, 8, 22]
Output:
>>> print(list(g))
[8]
- 在生成器表达式中,
in子句在声明时执行, 而条件子句则是在运行时执行. - 所以在运行前,
array已经被重新赋值为[2, 8, 22], 因此对于之前的1,8和15, 只有count(8)的结果是大于0的, 所以生成器只会生成8.
array_1 = [1,2,3,4]
g1 = (x for x in array_1)#in在声明时执行,引用旧对象
array_1 = [1,2,3,4,5]#新声明,新空间
array_2 = [1,2,3,4]
g2 = (x for x in array_2)
array_2[:] = [1,2,3,4,5]#切片复制,旧空间
Output:
>>> print(list(g1))
[1,2,3,4]
>>> print(list(g2))
[1,2,3,4,5]
关于生成
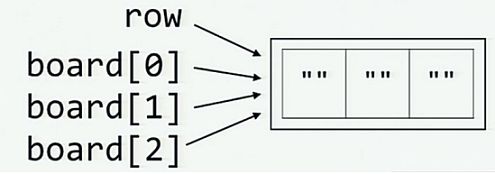
# 我们先初始化一个变量row
row = [""]*3 #row i['', '', '']
# 并创建一个变量board
board = [row]*3
>>> board
[['', '', ''], ['', '', ''], ['', '', '']]
>>> board[0]
['', '', '']
>>> board[0][0]
''
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['X', '', ''], ['X', '', '']]
>>> board = [['']*3 for _ in range(3)]
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['', '', ''], ['', '', '']]
原因:而当通过对 row 做乘法来初始化 board 时, 内存中的情况则如下图所示 (每个元素 board[0], board[1] 和 board[2] 都和 row 一样引用了同一列表.)
麻烦的输出、尾随逗号(略)
日后看
反斜杠
原始字符串
r"c:\news",由r开头引起的字符串就是声明了后面引号里的东西是原始字符串,在里面放任何字符都表示该字符的原始含义。 这种方法在做网站设置和网站目录结构的时候非常有用,使用了原始字符串就不需要转义了。
摘录来自: 齐伟. “跟老齐学Python:从入门到精通”。
repr
来源:https://www.cnblogs.com/itdyb/p/5046415.html
Python 有办法将任意值转为字符串:将它传入repr() 或str() 函数。
函数str() 用于将值转化为适于人阅读的形式,而repr() 转化为供解释器读取的形式。
>>>repr([0,1,2,3])
'[0,1,2,3]'
>>> repr('Hello')
"'Hello'"
>>> str(1.0/7.0)
'0.142857142857'
>>> repr(1.0/7.0)
'0.14285714285714285'
反斜杠转义
>>> print(repr(r"wt\"f")) 'wt\\"f'解释器所做的只是简单的改变了反斜杠的行为, 因此会直接放行反斜杠及后一个的字符. 这就是反斜杠在原始字符串末尾不起作用的原因.
三个引号
Output:
>>> print('wtfpython''')
wtfpython
>>> print("wtfpython""")
wtfpython
>>> # 下面的语句会抛出 `SyntaxError` 异常
>>> # print('''wtfpython')
>>> # print("""wtfpython")
说明:
Python 提供隐式的字符串链接, 例如,
>>> print("wtf" "python")
wtfpython
>>> print("wtf" "") # or "wtf"""
wtf
''' 和 """ 在 Python中也是字符串定界符, Python 解释器在先遇到三个引号的的时候会尝试再寻找三个终止引号作为定界符, 如果不存在则会导致 SyntaxError 异常.