使用 scrapy 开发爬虫的整个过程
这一次以实际的小项目来学习 scrapy 的用法。还是以招聘网站https://www.zhipin.com/c101280100/h_101280100为例。
爬取这个网站,然后提取所需要的数据信息,比如:招聘的职位(job_title)、工资待遇(salary)、招聘公司(company)、工作详细链接(url)、工作地点(work_addr)、
行业(industry)、公司规模(company_size)、招聘人(recruiter)、招聘信息发布时间(publish_date)。
使用 scrapy 的核心步骤
在设计代码之前,需要知道使用 scrapy 开发的核心步骤有三步:
- 定义items类:Items类是数据传输对象,由它定义需要爬取的数据信息,如:招聘职位(job_title)、工资待遇(salary)等均在这里面定义。
- 开发spider类:蜘蛛,核心步骤。它的作用是使用CSS选择器或XPath从页面中提取需要的数据信息,然后使用这些信息来封闭Item对象,并传输到pipeline文件中。
- pipeline文件:负责处理spider获取的Item对象。简单点说就是保存着spider从页面中提取到的数据信息,在这里可以将信息保存到文件中或保存到数据库中。
三个核心步骤的具体运用
Item类的定义
item类仅仅用于定义项目需要爬取的 n 个属性(数据信息),这些数据信息属于Field()类。如在这里面定义:招聘职位、工资待遇、工作地点、行业类型、公司规模等信息。
当创建一个爬虫项目后,文件夹中自动会生成一个名为items.py的文件,打开该文件,发现有如下默认的代码样式:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhipinspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
其中自动生成一个名为 ZhipinspiderItem 的类,它是根据项目名自动生成的,而且继承于 scrapy.Item 类,属于子类。
这个类中有默认的代码片段 name = scrapy.Field(),它用于定义项目中所需要爬取的数据信息的属性,name 表示信息名称,在这个项目中表示职位、工资待遇等。
coding: utf - 8 表示该文件需要以 utf - 8 的格式保存。
当知道需要从这个网站中爬取的数据信息后,就可以在Items.py文件中定义这些信息:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhipinspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 定义项目需要爬取的 n 个属性。Items的主要作用就是定义爬取所需要的属性类。
# 这些属性均属于 scrapy.Field()对象
# 工作名称
job_title = scrapy.Field()
# 工资待遇
salary = scrapy.Field()
# 招聘公司
company = scrapy.Field()
# 工作详细链接
url = scrapy.Field()
# 工作地点
work_addr = scrapy.Field()
# 行业类型
industry = scrapy.Field()
# 公司规模
company_size = scrapy.Field()
# 招聘人
recruiter = scrapy.Field()
# 招聘信息发布时间
publish_date = scrapy.Field()
将这个文件以 utf - 8 的格式保存,这样就定义好需要爬取的属性,这些属性在蜘蛛spider中可以提取到。
Spider类
定义好 Item 类后就可以编写蜘蛛爬虫了。蜘蛛爬虫文件是放在项目中 spiders 文件夹下的,创建蜘蛛有两种方法:
- 第一种,创建空文件,然后编写爬虫代码,然后将其放在 spiders 文件下。
- 第二种,在 spiders 文件下使用命令 “scrapy genspider 爬虫文件名”来创建爬虫。如:scrapy genspider zhipinSpider
在这里,本人就用命令的方式在 spiders 文件下创建名为 zhipinSpider 的爬虫文件来爬取页面中的数据信息:
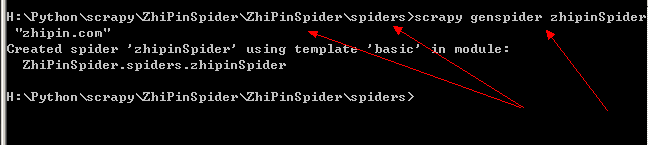
当显示上面的内容后说明该文件已经在 spiders 文件下创建成功,然后打开该文件,可以发现已有默认的几行代码存在:

其中,类名可以自定义,它必须继承一个蜘蛛类,如scrapy.Spider。name 表示蜘蛛的名字,这个是可以自定义的,定义须谨慎,运行蛛蛛文件时需要使用命令 scrapy crawl 蜘蛛名,如:scrapy crawl zhipinSpider 来爬取页面。
allowed_domains 是固定格式,它表示限制爬虫爬取的域名,也就是说爬虫只爬取规定的域名。
start_urls 也是固定格式,它表示爬虫需要爬取的页面的URL,可以设置多个。
parse 函数里就是需要定义的爬虫,用来爬取页面内容,然后使用XPath或CSS选择器提取需要的数据信息。
从这个模板可以看出,蜘蛛需要继承 scrapy.Spider,然后需要重写 parse(self, response)方法。我们无法看到发送请求、获取响应的代码,这正是 scrapy 的强大和魅力所在。
只需要将爬取的 URL 传递给 start_urs 列表中,scrapy 的下载中间件就会负责从网络上下载数据,然后将这些数据传递给parse(self, response)
方法的 response 参数,最后可以通过这个参数得到想要的数据信息。
因此可以总结出,在编写 Spider 蜘蛛文件时,只需要做两步工作:
- 将需要爬取的 URL 编写到 start_urls 列表中。
- 编写parse方法来提取需要的数据信息。
Spider 源码参考
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
源码分析:
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
class scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
_init_() : 初始化爬虫名字和start_urls列表
start_requests() 调用make_requests_from url():生成Requests对象交给Scrapy下载并返回response
parse() : 解析response,并返回Item或Requests(需指定回调函数)。Item传给Item pipline持久化 , 而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
主要属性和方法:
name:定义spider名字的字符串。例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
allowed_domains:包含了spider允许爬取的域名(domain)的列表,可选。
start_urls:初始URL元祖/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。
start_requests(self):该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取(默认实现是使用 start_urls 的url)的第一个Request。当spider启动爬取并且未指定start_urls时,该方法被调用。
parse(self, response):当请求url返回网页没有指定回调函数时,默认的Request对象回调函数。用来处理网页返回的response,以及生成Item或者Request对象。
log(self, message[, level, component]):使用 scrapy.log.msg() 方法记录(log)message。 更多数据请参见 logging
蜘蛛编写
在编写爬虫文件前,需要好好地分析招聘页面,从招聘页面中大致浏览需要提取的数据信息:
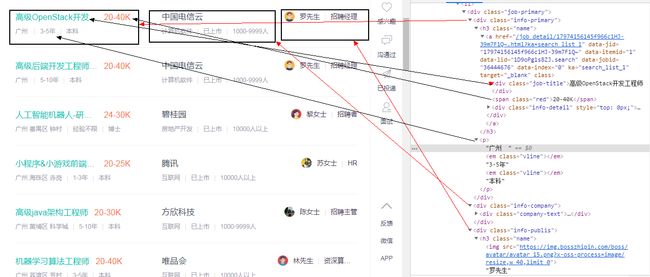
通过分析整个HTML文档结构可以发现,所有公司的招聘信息在文档中的格式是相似的,它们均在 从图中可以知道,只要获取到 class 为 job-primary 的 div 标记,就可以从中提取到需要的数据信息。提取的方式可以使用XPath,也可以使用CSS选择器。 而且,每个公司都有属于自己的 job-primary,在这个 job-primary 中,又分为三个部分:info-primary(职位要求)、info-company(公司相关)、info-publis(招聘人信息)。 通过分析HTML文档就可以编写蜘蛛文件了: 从上面例子可以看到几个关键点: 1、导入 items 模块时需要添加前缀即:项目文件名 + items文件名,如:ZhiPinSpider.items,然后导入 items 文件中的类,这样才能引用定义的属性。 程序最后,Spider 蜘蛛将 item 返回给 scrapy 引擎后,引擎将 item 对象传给 pipeline 文件,这个文件用于存入爬取的数据信息,同时,可以在这个文件中设置将爬取到的数据信息存放在文件中还是数据库内。 scrapy 引擎将 item 对象传给 pipeline 文件中,此时就可以在里面设置爬取到的相关数据信息了。 可以看出,pipeline 类主要实现 process_itme 方法,这个方法专门收集 scrapy 引擎传过来的 item 对象,并逐个传递。 此时爬虫文件基本完成,但还需要一步。 在使用 scrapy shell 调试命令时发现,此招聘网https://www.zhipin.com/c101280100/h_101280100/具有反爬虫机制。 打开项目中已经默认创建好的 setting.py 文件,然后将一些注释去掉,添加以下代码: 到此这里,爬虫程序正式编写完毕,再次总结 scrapy 开发爬虫的三个核心步骤: 运行蜘蛛使用命令:scrapy crawl 蜘蛛名。如:scrapy crawl zhipinSpider。 在这里,运行蜘蛛有两种方式: 1、直接使用 cmd 命令模式运行 首先,回到项目文件的根目录,然后使用 cmd 命令打开命令模式: 然后,如下输入命令 scrapy crawl zhipinSpider,蜘蛛运行,需要的数据即可爬取成功: 2、如果使用 PyCharm 软件开发爬虫 首先,打开 PyCharm 软件左下角的 Terminal 选项,然后使用命令 cd 依次打开项目文件到其根目录,最后输入运行命令: PyCharm 中的爬取结果: 在这里,本人建议使用 PyCharm 来运行蜘蛛,因此不仅方便,更重要的是,如果爬取数据过多的话,cmd 命令模式中会省略掉前面的内容,这样观察数据不方便, 上面的例子的只是爬取了第一页的内容,或者说只爬取了一页的内容。而作为爬虫工程师,爬取的数据远远不止这些,甚至需要爬取整个网站的数据信息。 因此,接下来需要爬取其它页面的招聘信息。 首先,需要判断该网站是否还有“下一页”存在,即找到表示下一页的 HTML 元素节点: 可以看到,这个招聘还有其它页面的招聘内容。那么接下来先观察当点击下一页后,域名栏中的变化情况: 可以看到第二页域名的变化只是在域名后面添加了 ?page=2&ka=page-2 这个固定格式,点击第三页时也是这样的格式。此时再将后面的 &ka=page-2去掉,发现页面不变。 那么获取下一页数据的步骤可以总结为: 因此,可以在蜘蛛文件中的 parse() 方法后面添加以下代码: 当然,对于判断 URL 是否有效,上面的代码也可以替换为: 最后运行蜘蛛:scrapy crawl zhipinSpider,发现爬取到的数据比先前多了许多,正是后面数页的数据。 最后,附上该例子的完整代码: 爬虫项目开发的过程当此已算是结束。当然,作为真正的爬虫工程师,这个过程还不算完整,最后可能需要将爬取到的数据存入在数据库中,如:mySql、MongoDB等数据库。
包括:职位、工资、公司、公司规模、行业等,分析HTML文档:
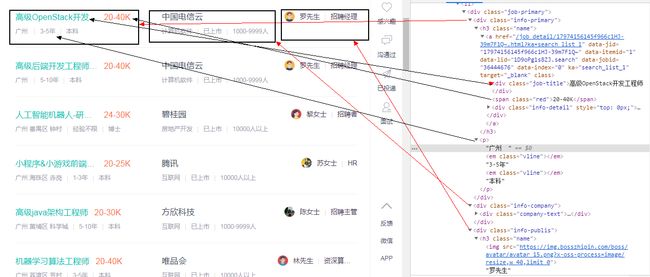
也就是说,只要使用XPath或CSS选择器定位到这三部分内容,就能够提取数据信息了。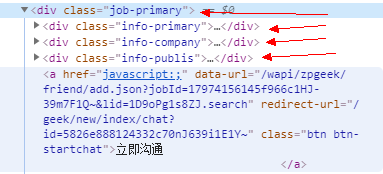
# -*- coding: utf-8 -*-
import scrapy
# 关键点1:从项目文件中的 items模块中导入ZhipinspiderItem类
from ZhiPinSpider.items import ZhipinspiderItem
class ZhipinspiderSpider(scrapy.Spider):
# 蜘蛛名,唯一标识,运行蜘蛛时需要
name = 'zhipinSpider'
# 限制爬取的域名列表,可选
allowed_domains = ['zhipin.com']
# 初始URL列表,当没有制定allowed_domains时,就从该列表中爬取URL
start_urls = ['https://www.zhipin.com/c101280100/h_101280100/']
# parse用于提取保存在response中的数据信息
# response表示下载器从start_urls中的URL中下载得到的响应
def parse(self, response):
# 爬取所有类名为job-primary的div元素
# 它包含公司招聘的所有信息
# 使用XPath提取这些信息
job_primarys = response.xpath("//div[@class='job-primary']")
# 使用for循环提取第一个名为 job-primary 的 div 元素
for job_primary in job_primarys:
# 实例化items,让实例化对象拥有itme类中的成员属性
item = ZhipinspiderItem()
# 爬取职位要求的 div(info-primary),并提取其下面的数据信息:职位、工资、工作地点、地点链接
# 当前节点下,class 属性为 info-primary 的 div 元素节点
# ./表示以当前节点为根节点
info_primary = job_primary.xpath("./div[@class='info-primary']")
# 提取具体信息,获取 items 类中定义的属性的具体内容
# 提取职位,使用text()获取文本节点
item["title"] = info_primary.xpath("./h3/a/div[@class='job-title']/text()").extract_first()
# 提取工资待遇
item["salary"] = info_primary.xpath("./h3/a/span[@class='red']/text()").extract_first()
# 提取工作地点
item["work_addr"] = info_primary.xpath("./p/text()").extract_first()
# 提取工作链接
item["url"] = info_primary.xpath("./h3/a/@href").extract_first()
# 爬取关于公司的数据信息,如:公司名称、行业类型、公司规模
# 提取节点 div (job-primary) 下的节点 div (info-company) 下的节点 div (company-text)
company_text = job_primary.xpath("./div[@class='info-company']" + "/div[@class='company-text']")
# 提取公司名
item["company"] = company_text.xpath("./h3/a/text()").extract_first()
# 提取公司行业、是否上市、规模等信息
company_info = company_text.xpath("./p/text()").extract()
# 行业选项在列表中第一个元素(下标为0),因此先判断列表长度是否大于0,如果大于则提取行业
if company_info and len(company_info) > 0:
item["industry"] = company_info[0]
# 公司规模数据在列表中第三个元素(下标为2),因此先判断列表长度是否大于2,如果大于则提到规模
if company_info and len(company_info) > 2:
item["company_size"] = company_info[2]
"""
提取招聘人数据信息,如:招聘人名、职位、招聘信息发布时间。
选取节点 div (job-primary) 下的节点 div (info-publis)
"""
info_publis = job_primary.xpath("./div[@class='info-publis']")
# 提取招聘人
item["recruiter"] = info_publis.xpath("./h3/text()").extract_first()
# 提取招聘信息发布时间
item["publish_date"] = info_publis.xpath("./p/text()").extract_first()
# 使用 yield 创建生成器,将 item 对象返回给 scrapy 引擎。
# scrapy 引擎将 item 对象收集起来传给项目的 pipeline 文件。
# 此处不能使用 return ,return 会将parse方法返回,导致循环不能继续执行。
yield item
2、yield 作用是创建生成器,程序最后用它返回 item 对象,且它还能暂停当前的运行状态,等待下一次继续执行。如果使用 return,会返回整个方法,循环结束。
3、特别注意 HTML 文档中各个元素节点的嵌套。pipeline 文件编写
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class ZhipinspiderPipeline(object):
def process_item(self, item, spider):
# 该文件收集了 scrapy 引擎传递过来的 item 对象,也就是需要爬取到的数据信息。
print("工作:", item["title"])
print("工资:", item['salary'])
print("工作地点:", item['work_addr'])
print("详情链接:", item['url'])
print("公司:", item['company'])
print("行业:", item['industry'])
print("公司规模:", item['company_size'])
print("招聘人:", item['recruiter'])
print("发布日期:", item['publish_date'])
因此,此方法只需处理单个 item 对象即可,如:item["title"]、item["salary"]等。setting 文件配置
之前我使用模拟浏览器的方式(重新设置了发送请求的头部信息User-Agent)才访问到这个网站,因此在这里也需要设置发送请求头部信息来模拟浏览器访问。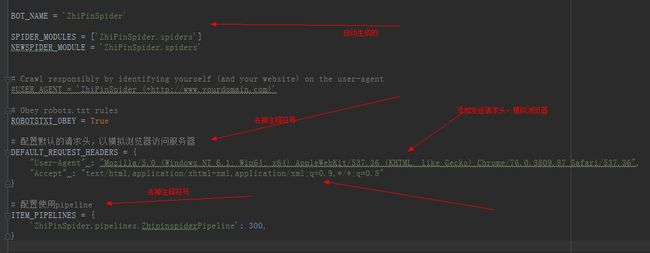
1、items类:定义爬虫所需要爬取的属性。这些属性均是 itmes 类的子类。
2、编写 spider 爬虫:在编写前,需要引入 itmes 模块中的类,格式:from 项目文件名 + itmes文件名 import 类名
3、当 scrapy 引擎将 item 对象传给 pipeline 文件后,就可以编写 pipeline。此时 itme 对象已经是爬取到的数据信息了。可以存放在文件内,也可以存放在数据库中。运行蜘蛛 scrapy crawl 蜘蛛名
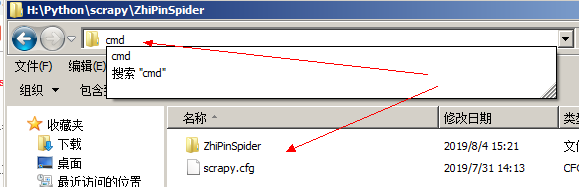
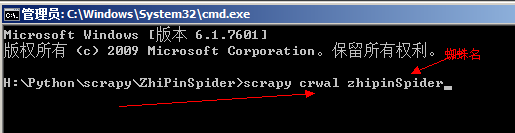
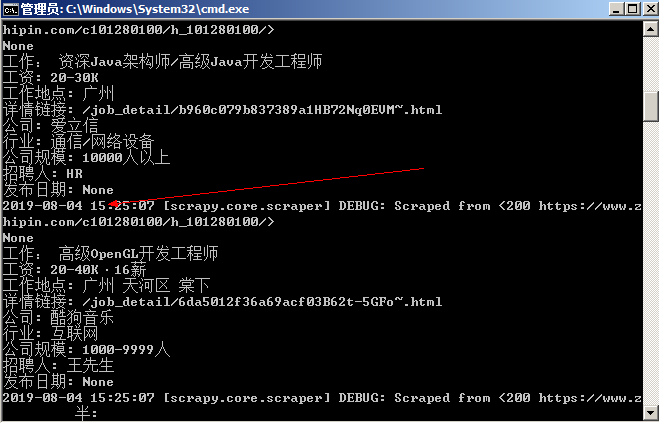
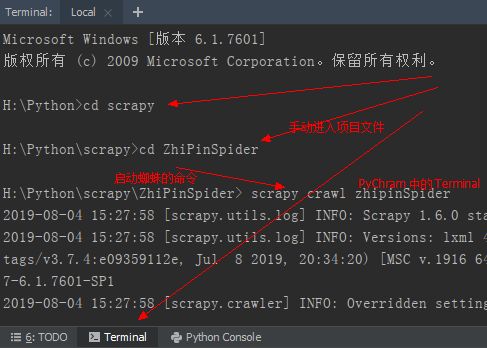
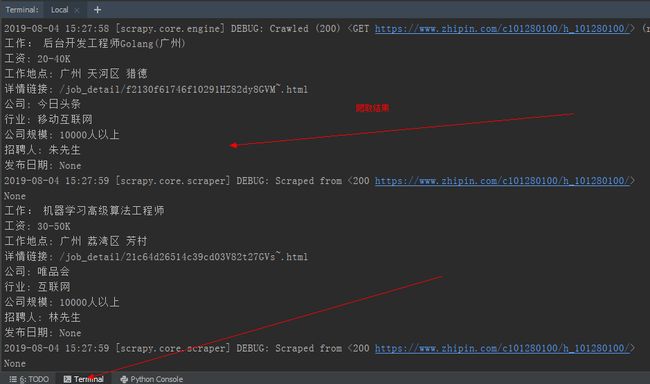
而 PyCharm 会将所有爬取的数据全部显示。判断下一页,爬取所有页面数据
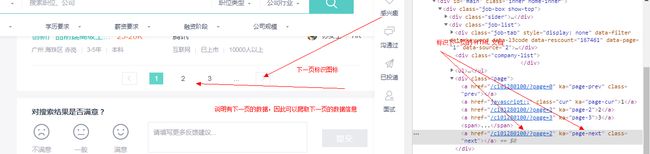
![]()
从这里说明,表示下一页的固定格式就是在域名 https://www.zhipin.com 后面添加 ?page=2,?page=2 可以通过 XPath 在 HTML 文档获取。![]()
1、获取表示下一页的URL。
2、判断该 URL 是否有效。
3、如果有效,使用 scrapy.Requst() 方法访问,并再次使用 parse() 方法爬取数据。 """
上面只是爬取一页的数据内容,而开发程序员是要爬取所有页面的招聘信息内容的。
所以在这里还需要爬取下一页、再下一页、还下一页的数据。
因此,首先需要判断是否还有下一页,如果有则将下下一页的 URL 传递给 scrapy.Request() 方法,并继续执行 parse 方法。
"""
# 判断是否还有下一页的URL
# 打到表示下一页的元素节点
# 获取表示下一页的 a 链接的 href 属性
page_next = response.xpath("//div[@class='page']/a[@class='next']/@href").extract()
# 判断表示下一页的链接是否有效,如果有则可以传递
if page_next and len(page_next) > 0:
page_next = page_next[0]
# 再次发送请求获取下一页数据
yield scrapy.Request("https://www.zhipin.com" + page_next, callback=self.parse)
page_next = response.xpath("//div[@class='page']/a[@class='next']/@href").extract_first()
# 判断表示下一页的链接是否有效,如果有则可以传递
if page_next is not None:
page_next = page_next
# 再次发送请求获取下一页数据
yield scrapy.Request("https://www.zhipin.com" + page_next, callback=self.parse)
# -*- coding: utf-8 -*-
import scrapy
# 关键点1:从项目文件中的 items模块中导入ZhipinspiderItem类
from ZhiPinSpider.items import ZhipinspiderItem
class ZhipinspiderSpider(scrapy.Spider):
# 蜘蛛名,唯一标识,运行蜘蛛时需要
name = 'zhipinSpider'
# 限制爬取的域名列表,可选
allowed_domains = ['zhipin.com']
# 初始URL列表,当没有制定allowed_domains时,就从该列表中爬取URL
start_urls = ['https://www.zhipin.com/c101280100/h_101280100/']
# parse用于提取保存在response中的数据信息
# response表示下载器从start_urls中的URL中下载得到的响应
def parse(self, response):
# 爬取所有类名为job-primary的div元素
# 它包含公司招聘的所有信息
# 使用XPath提取这些信息
job_primarys = response.xpath("//div[@class='job-primary']")
# 使用for循环提取第一个名为 job-primary 的 div 元素
for job_primary in job_primarys:
# 实例化items,让实例化对象拥有itme类中的成员属性
item = ZhipinspiderItem()
# 爬取职位要求的 div(info-primary),并提取其下面的数据信息:职位、工资、工作地点、地点链接
# 当前节点下,class 属性为 info-primary 的 div 元素节点
# ./表示以当前节点为根节点
info_primary = job_primary.xpath("./div[@class='info-primary']")
# 提取具体信息,获取 items 类中定义的属性的具体内容
# 提取职位,使用text()获取文本节点
item["title"] = info_primary.xpath("./h3/a/div[@class='job-title']/text()").extract_first()
# 提取工资待遇
item["salary"] = info_primary.xpath("./h3/a/span[@class='red']/text()").extract_first()
# 提取工作地点
item["work_addr"] = info_primary.xpath("./p/text()").extract_first()
# 提取工作链接
item["url"] = info_primary.xpath("./h3/a/@href").extract_first()
# 爬取关于公司的数据信息,如:公司名称、行业类型、公司规模
# 提取节点 div (job-primary) 下的节点 div (info-company) 下的节点 div (company-text)
company_text = job_primary.xpath("./div[@class='info-company']" + "/div[@class='company-text']")
# 提取公司名
item["company"] = company_text.xpath("./h3/a/text()").extract_first()
# 提取公司行业、是否上市、规模等信息
company_info = company_text.xpath("./p/text()").extract()
# 行业选项在列表中第一个元素(下标为0),因此先判断列表长度是否大于0,如果大于则提取行业
if company_info and len(company_info) > 0:
item["industry"] = company_info[0]
# 公司规模数据在列表中第三个元素(下标为2),因此先判断列表长度是否大于2,如果大于则提到规模
if company_info and len(company_info) > 2:
item["company_size"] = company_info[2]
"""
提取招聘人数据信息,如:招聘人名、职位、招聘信息发布时间。
选取节点 div (job-primary) 下的节点 div (info-publis)
"""
info_publis = job_primary.xpath("./div[@class='info-publis']")
# 提取招聘人
item["recruiter"] = info_publis.xpath("./h3/text()").extract_first()
# 提取招聘信息发布时间
item["publish_date"] = info_publis.xpath("./p/text()").extract_first()
# 使用 yield 创建生成器,将 item 对象返回给 scrapy 引擎。
# scrapy 引擎将 item 对象收集起来传给项目的 pipeline 文件。
# 此处不能使用 return ,return 会将parse方法返回,导致循环不能继续执行。
yield item
"""
上面只是爬取一页的数据内容,而开发程序员是要爬取所有页面的招聘信息内容的。
所以在这里还需要爬取下一页、再下一页、还下一页的数据。
因此,首先需要判断是否还有下一页,如果有则将下下一页的 URL 传递给 scrapy.Request() 方法,并继续执行 parse 方法。
"""
# 判断是否还有下一页的URL
# 打到表示下一页的元素节点
# 获取表示下一页的 a 链接的 href 属性
page_next = response.xpath("//div[@class='page']/a[@class='next']/@href").extract()
# 判断表示下一页的链接是否有效,如果有则可以传递
if page_next and len(page_next) > 0:
page_next = page_next[0]
# 再次发送请求获取下一页数据
yield scrapy.Request("https://www.zhipin.com" + page_next, callback=self.parse)
并且,有许多网站具有反爬虫机制,那么就需要在爬虫中针对这些机制作出相应方案。