Reference:
第二周:网络爬虫之提取
单元4:Beautiful Soup库入门
4-1 Beautiful Soup库的安装
使用原理:能办你给它的任何文档当做一锅汤,然后煲制这锅汤。
演示html页面上地址:http://python123.io/ws/demo.html
如何获得页面的源代码:
方法1:右键点击查看源代码
方法2:用request库来自动获取页面的源代码
>>>from bs4 import BeautifulSoup
>>>
4-2 Beautiful Soup库的基本元素
Beautiful Soup库是解析、遍历、维护“标签树”的功能库。只要你提供的文件是标签类型,那么Beautiful Soup库都可以对它做很好的解析。
Beautiful Soup对应一个
Beautiful Soup库解析器:
Beautiful Soup类的基本元素:

4-3 基于bs4库的HTML内容遍历方法
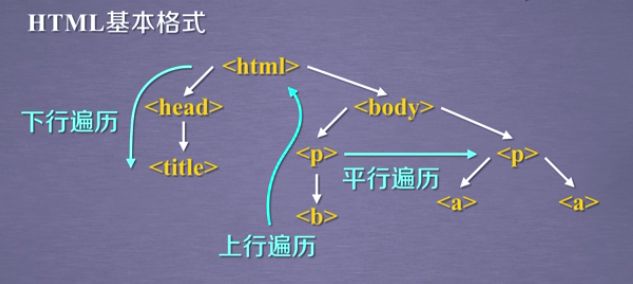

4-4 基于bs4库的HTML格式化和编码
单元5:信息组织与提取方法
5-1 信息标记的三种方式
信息的标记:
***一个信息:北京理工大学
***一组信息:
需要对信息做一定的标记,使得我们能够理解信息所返回的真实含义。
比如:信息标记 ‘name’,‘北京理工大学’ 给它标记一个name,表明它是一个名字
‘addr’,‘北京市海淀区中关村’ 给它标记一个address,表明它是一个地址
信息的标记:
(1)标记后的信息可形成信息组织结构,增加了信息维度。
(2)标记后的信息可用于通信、存储或展示。
(3)标记的结构与信息一样具有重要价值。
(4) 标记后的信息更有利于程序的理解和运用,也更有利于人对信息的深入的认识和理解。
HTML的信息标记 = Hyper Text Markup Language 超文本标记语言
html是www的信息组织方式。能够将声音、图像、视频等超文本的信息嵌入到文本当中。
HTML的信息标记
HTML通过预定义的<>...标签形式组织不同类型的信息。示例如图:
信息标记有哪些种类呢?
信息标记的三种形式:XML,JSON和YMAL
XML = eXtensible Markup Language 扩展标记语言
是一种与HTML接近的标记语言。
示例:
JSON = JavaScript Object Notation
有类型的键值对构建的信息表达方式 key:value
什么是键值对?就是给出一个信息,并对这个信息的类型做一个定义。
比如:
在JSON类型中要注意:无论是键还是值都需要通过增加双引号来表达它是字符串的形式。如果是数字,比如:1990,1911,就直接写数字即可。这种类型反应在键值对上,说明它是一个有数据类型的键值对。
值的部分有多个名字的时候:
键值对之间可以嵌套使用:
总结:JSON使用有类型的键值对将信息组织起来
好处:
YAML=YAML Ain't Markup Language
无类型键值对标记信息的表达形式
5-2 三种信息标记形式的比较
XML实例:
JSON实例:
YAML实例:
比较:
(1)XML 格式是最早的通用信息标记语言,可扩展性好,但繁琐。 应用:Internet上的信息交互与传递
(2)JSON 信息有类型,适合程序处理(js),较XML 简洁。应用:移动应用云端和节点的信息通信(一般用在程序对接口处理的地方)。
但是JSON有一个缺点:无注释。
(3)YAML 信息无类型,文本信息比例最好,可读性好。应用:各类系统的配置文件,有注释易读。因为既适合人类阅读,又适合程序分析。
5-3 信息提取的一般方法
信息提取指从标记后的信息中提取所关注的内容。
无论哪种形式,都包含“信息”和“标记”两部分。
信息提取的一般方法:
方法一:完整解析信息的标记形式,再提取关键信息。
XML JSON YMAL 需要标记解析器 例如:bs4库的标签树遍历
优点:信息解析准确
缺点:提取过程繁琐,速度慢,需要对整个文本的信息组织形式有清楚的理解。
方法二:无视标记形式,直接搜索获取关键信息。
搜索 对信息的文本查找函数即可
优点:提取过程简洁,速度较快。
缺点:提取结果准确性与信息内容相关。
融合方法:结合形式解析与搜索方法,提取关键信息。
XML JSON YAML 搜索 ---》需要标记解析器及文本查找函数
实例:提取HTML中所有URL链接
思路:(1)搜索到所有的标签
(2)解析标签格式,提取href后的链接内容
<>.find_all(name,attrs,recursive,string,)
扩展方法
5-4 基于bs4库的HTML内容查找方法
单元6:实例1:中国大学排名爬虫
最好大学网:http://zuihaodaxue.cn/zuihaodaxuepaiming2016.html
功能描述:
输入:大学排名URL链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:requests-bs4
定向爬虫:仅对输入URL进行爬取,不扩展爬取。
(PS:从一个URL爬取其他更多的URL信息,这个就不是定向爬虫了)
STEP1. 查看信息是否写在html代码中?还是动态生成的?
STEP2. 查看该网站是否提供了robots的协定
程序的结构设计
步骤1:从网络上获取大学排名网页内容 getHTMLText()
步骤2:提取网页内容中信息到合适的数据结构 fillUnivList()
步骤3:利用数据结构展示并输出结果printUnivList()