同步更新在个人网站: http://www.wangpengcufe.com/machinelearning/python-python1/
一、案例背景
在产品迭代过程中,通常需要根据用户的属性进行归类,也就是通过分析数据,对用户进行归类,以便于在推送及转化过程中获得更大的收益。
本案例是基于某互联网公司的实际用户购票数据为研究对象,对用户购票的时间,购买的金额进行了采集,每个用户用手机号来区别唯一性。数据分析人员根据用户购买的时间和金额,通过建立RFM模型,来计算出用户最近最近一次购买的打分,用户购买频率的打分,用户购买金额的打分,然后根据三个分数进行一个加权打分,和综合打分。业务人员可以根据用户的打分情况,对不同的用户进行个性化营销和精准营销,例如给不同的用户推送定制的营销短信,不同优惠额度的打折券等等。
通过RFM方法,可以根据用户的属性数据分析,对用户进行了归类。在推送、转化等很多过程中,可以更加精准化,不至于出现用户反感的情景,更重要的是,对产品转化等商业价值也有很大的帮助。
二、RFM概念
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。该机械模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。
RFM分析 就是根据客户活跃程度和交易金额的贡献,进行客户价值细分的一种方法。其中:
R(Recency):客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
F(Frequency):客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
M(Monetary):客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
R打分:基于最近一次交易日期计算的得分,距离当前日期越近,得分越高。例如5分制。
F打分:基于交易频率计算的得分,交易频率越高,得分越高。如5分制。
M打分:基于交易金额计算的得分,交易金额越高,得分越高。如5分制。
RFM总分值:RFM=Rx100+Fx10+Mx1
RFM分析的主要作用:
识别优质客户。可以指定个性化的沟通和营销服务,为更多的营销决策提供有力支持。
能够衡量客户价值和客户利润创收能力。
三、代码实现
3.1、引包
首先我们引入需要用的包,数据分析常用的numpy包,pandas包,等。
import time
import numpy as np
import pandas as pd
import mysql.connector
3.2、读取数据
接下来我们开始用pd.read_csv方法读取用户的数据
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))+':读取数据...')
config = {
'host' : '127.0.0.1',
'user' : 'root',
'password' : 'test123',
'port' : 3306,
'database' : 'user',
'charset' : 'gb2312'
}
cnn = mysql.connector.connect(**config) # 建立MySQL连接
cursor = cnn.cursor() # 获得游标
sql = "SELECT phoneNo AS PHONENO,create_date AS ORDERDATE,order_no AS ORDERNO,ROUND(pay_amount/100,2) AS PAYAMOUNT " \
"FROM user.`event_record_order`" # SQL语句
raw_data = pd.read_sql(sql,cnn,index_col='PHONENO')
cursor.close() # 关闭游标
cnn.close() # 关闭连接
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))+':读取数据完毕!')
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))+':开始建立RFM模型...')
介绍一下config 里的参数信息:host是数据库的ip信息,本案例用的是本地数据库,实际部署生产服务器时,改成生产的ip地址即可。user 是数据库的用户名,password是密码,port是数据库的端口号,database是连接的数据库名 (schema),charset是字符集编码。
购票时间(ORDERDATE),订单号(ORDERID)是object类型,订单金额(AMOUNTINFO)是浮点类型。index_col指定了数据中用户的唯一性用 USERID来表示。
time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())打印了当前的系统时间,用来记录日志信息。
3.3、数据审查
print('Data Overview :')
print(raw_data.head(4)) #打印原始数据前4条
print('-' * 30)
print('Data DESC:')
print(raw_data.describe()) #打印原始数据基本描述性信息
我们用raw_data.head(n)来指定取出数据的前几条,'-'*30是用来输出打印分隔线,下文再出现时不再重复解释,用raw_data.describe()来获得数据的基本描述性信息。输出结果:
Data Overview:
ORDERDATE ORDERNO PAYAMOUNT
PHONENO
135****0930 2019-10-02 13:37:36 01201910021336227979 7.0
183****1153 2019-09-30 06:22:29 0120190930062149F9AF 4.5
150****6073 2019-10-30 18:21:45 01201910301821065CFD 2.0
173****7295 2019-10-21 15:13:23 01201910211512498153 7.0
------------------------------
Data DESC:
PAYAMOUNT
count 96323.000000
mean 4.212409
std 3.049499
min 0.000000
25% 2.600000
50% 3.600000
75% 5.000000
max 80.000000
我们看到结果中的 count表示总共的记录条数,mean表示了均值,std表示标准差,min表示最小值,25%表示下四分位,也叫第一四分位,50%表示中位值,也叫第二四分位,75%表示上四分位,也叫第三四分位。
na_cols = raw_data.isnull().any(axis=0) #查看每一列是否具有缺失值
print('NA Cols:')
print(na_cols)
print('-' * 30)
na_lines = raw_data.isnull().any(axis=1) #查看每一行是否具有缺失值
print('NA Records:')
print('Total number of NA lines is :{0}'.format(na_lines.sum())) #查看具有缺失值的行总记录数
print(raw_data[na_lines]) #只查看具有缺失值的行信息
我们用raw_data.isnull()来判断是否有缺失值,其中参数axis=0表示的是列,axis=1表示的是行,用:{0}'.format()的方式在字符串中传入参数。输出结果:
NA Cols:
ORDERDATE False
ORDERNO False
PAYAMOUNT False
dtype: bool
------------------------------
NA Records:
Total number of NA lines is :0
Empty DataFrame
Columns: [ORDERDATE, ORDERNO, PAYAMOUNT]
Index: []
通过结果可以看到,实际的交易用户数据还是比较完整的,没有缺失数据的情况,可能这批数据被技术人员采集过来已经处理过了,不讨论了。如果数据有缺失的情况怎么办?那就要对缺失的数据进行一个预处理。
3.4、数据预处理
数据预处理,包括数据异常,格式转换,单位转化(如果有单位不统一的情况)等。
我们先来看异常值处理:
sales_data = raw_data.dropna() #丢弃带有缺失值的行记录
sales_data = sales_data[sales_data['PAYAMOUNT'] > 1]
这里,我用代码去除了小于1元的订单,正常出行连1块钱都不用,那应该是测试数据了,现在谁出门做个公交还不得1元起步。对于用户有缺失值的记录进行了丢弃,当然也可以用其他的方法,例如平均值补全法。
然后看日期格式转换:
sales_data['ORDERDATE'] = pd.to_datetime(sales_data['ORDERDATE'])
print('Raw Dtype:')
print(sales_data.dtypes)
用pd.to_datetime()方法对用户的订单日期进行了格式化转换。输出结果:
Raw Dtype:
ORDERDATE datetime64[ns]
ORDERNO object
PAYAMOUNT float64
dtype: object
最后看数据转换:
recency_value = sales_data['ORDERDATE'].groupby(sales_data.index).max() #计算原始最近一次购买时间
frequency_value = sales_data['ORDERDATE'].groupby(sales_data.index).count() #计算原始订单数
monetray_value = sales_data['PAYAMOUNT'].groupby(sales_data.index).sum() #计算原始订单总金额
这里根据订单日期的聚合运算得到了用户的最近一次购买时间,用户总的购买数,和购买金额,max()得到了购买时间,count()得到了购买数量,sum()得到了购买金额。
3.5、计算RFM得分
得到了最近的购买时间,购买数,和购买金额,下面就可以开始计算RFM得分了。
deadline_date = pd.datetime(2019,11,15)
r_interval = (deadline_date - recency_value).dt.days
r_score = pd.cut(r_interval,5,labels=[5,4,3,2,1])
f_score = pd.cut(frequency_value,5,labels=[1,2,3,4,5])
m_score = pd.cut(monetray_value,5,labels=[1,2,3,4,5])
我们又把客户分成五等分,这个五等分分析相当于是一个“忠诚度的阶梯”(loyalty ladder),如购买一次的客户为新客户,购买两次的客户为潜力客户,购买三次的客户为老客户,购买四次的客户为成熟客户,购买五次及以上则为忠实客户。其诀窍在于让消费者一直顺着阶梯往上爬,把销售想象成是要将两次购买的顾客往上推成三次购买的顾客,把一次购买者变成两次的。
我们用deadline_date来表示分析的截止日期,那么统计用户的时间范围就是从数据中最早开始的购买时间到deadline_date。
用pandas.series.dt.days可以对操作后的datatime直接进行取数。pandas.cut用来把一组数据分割成离散的区间。
简单介绍一下pandas.cut的用法:
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise')
- x:被切分的类数组(array-like)数据,必须是1维的(不能用DataFrame);
- bins:bins是被切割后的区间(或者叫“桶”、“箱”、“面元”),有3中形式:一个int型的标量、标量序列(数组)或者pandas.IntervalIndex 。
- 一个int型的标量,当bins为一个int型的标量时,代表将x平分成bins份。x的范围在每侧扩展0.1%,以包括x的最大值和最小值。
- 标量序列,标量序列定义了被分割后每一个bin的区间边缘,此时x没有扩展。
- pandas.IntervalIndex,定义要使用的精确区间。
- right:bool型参数,默认为True,表示是否包含区间右部。比如如果bins=[1,2,3],right=True,则区间为(1,2],(2,3];right=False,则区间为(1,2),(2,3)。
- labels:给分割后的bins打标签,比如把年龄x分割成年龄段bins后,可以给年龄段打上诸如青年、中年的标签。labels的长度必须和划分后的区间长度相等,比如bins=[1,2,3],划分后有2个区间(1,2],(2,3],则labels的长度必须为2。如果指定labels=False,则返回x中的数据在第几个bin中(从0开始)。
- retbins:bool型的参数,表示是否将分割后的bins返回,当bins为一个int型的标量时比较有用,这样可以得到划分后的区间,默认为False。
- precision:保留区间小数点的位数,默认为3.
- include_lowest:bool型的参数,表示区间的左边是开还是闭的,默认为false,也就是不包含区间左部(闭)。
- duplicates:是否允许重复区间。有两种选择:raise:不允许,drop:允许。
重点理解我标粗的几个参数,其他参数有需要用到时查阅。
RFM数据合并
rfm_list = [r_score,f_score,m_score] #将r、f、m三个维度组成列表
rfm_cols = ['r_score','f_score','m_score'] #设置r、f、m 三个维度列名
rfm_pd = pd.DataFrame(np.array(rfm_list).transpose(),dtype=np.int32,columns=rfm_cols,index=frequency_value.index) #建立r、f、m数据框
我们把RFM的数据进行了合并,首先是将r、f、m三个维度组成一个列表,然后取了三个列名,把数据,列名组装成一个数据框DataFrame.
print('RFM Score Overview:')
print(rfm_pd.head(4))
输出结果:
RFM Score Overview:
r_score f_score m_score
PHONENO
13001055088 4 1 1
13001061903 4 1 1
13001066446 5 1 1
13001123218 4 1 1
rfm_pd['rfm_wscore'] = rfm_pd['r_score'] * 0.6 + rfm_pd['f_score'] * 0.3 + rfm_pd['m_score'] * 0.1
rfm_pd_tmp = rfm_pd.copy()
rfm_pd_tmp['r_score'] = rfm_pd_tmp['r_score'].astype('str')
rfm_pd_tmp['f_score'] = rfm_pd_tmp['f_score'].astype('str')
rfm_pd_tmp['m_score'] = rfm_pd_tmp['m_score'].astype('str')
rfm_pd['rfm_comb'] = rfm_pd_tmp['r_score'].str.cat(rfm_pd_tmp['f_score']).str.cat(rfm_pd_tmp['m_score'])
理论上,上一次消费时间越近的顾客应该是比较好的顾客,对提供即时的商品或是服务也最有可能会有反应。营销人员若想业绩有所成长,只能靠偷取竞争对手的市场占有率,而如果要密切地注意消费者的购买行为,那么最近的一次消费就是营销人员第一个要利用的工具。历史显示,如果我们能让消费者购买,他们就会持续购买。这也就是为什么,0至3个月的顾客收到营销人员的沟通信息多于3至6个月的顾客。
这里,对RFM进行了加权打分,R占60%,F占30%,M占10%,当然也可以根据业务的实际情况进行相应的权重调整。综合打分是根据RFM=R100+F10+M*1。
3.6、保存结果
print('Final RFM Score Overview:')
print(rfm_pd.head(4))
print('-'*30)
print('Final RFM Score DESC:')
print(rfm_pd.describe())
rfm_pd.to_csv('sales_rfm_score.csv')
输出结果:
Final RFM Score Overview:
r_score f_score m_score rfm_wscore rfm_comb
PHONENO
13001055088 4 1 1 2.8 411
13001061903 4 1 1 2.8 411
13001066446 5 1 1 3.4 511
13001123218 4 1 1 2.8 411
------------------------------
Final RFM Score DESC:
r_score f_score m_score rfm_wscore
count 53064.000000 53064.000000 53064.000000 53064.000000
mean 3.732172 1.006407 1.002148 2.641441
std 0.944452 0.113022 0.055212 0.570417
min 1.000000 1.000000 1.000000 1.000000
25% 3.000000 1.000000 1.000000 2.200000
50% 4.000000 1.000000 1.000000 2.800000
75% 5.000000 1.000000 1.000000 3.400000
3.7、写入数据库
建立数据库连接
table_name = 'sale_rfm_score'
#数据框基本信息
config = {
'host' : '172.0.0.1',
'user' : 'root',
'password' : 'test123',
'port' : 3306,
'database' : 'skpda',
'charset' : 'gb2312'
}
con = mysql.connector.connect(**config)
cursor = con.cursor()
cursor.execute("show tables") #
table_object = cursor.fetchall() # 通过fetchall方法获得所有数据
table_list = [] # 创建库列表
for t in table_object: # 循环读出所有库
table_list.append(t[0]) # 每个每个库追加到列表
if not table_name in table_list: # 如果目标表没有创建
cursor.execute('''
CREATE TABLE %s (
phone_no VARCHAR(20),
r_score int(2),
f_score int(2),
m_score int(2),
rfm_wscore DECIMAL(10,2),
rfm_comb VARCHAR(10),
create_date VARCHAR(20)
)ENGINE=InnoDB DEFAULT CHARSET=gb2312
''' % table_name) # 创建新表
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))+ ':开始清除 table {0}的历史数据...'.format(table_name)) # 输出开始清历史数据的提示信息
delete_sql = 'truncate table {0}'.format(table_name)
cursor.execute(delete_sql)
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))+ ':清除 table {0}的历史数据完毕!'.format(table_name)) # 输出清除历史数据完毕的提示信息
连接的参数不再介绍,上文已经介绍过。通过fetchall方法获得所有数据,读出所有的表,如果没有表则创建。用cursor.execute先执行truncate语句,把表中的信息先清除,然后重新写入数据。
将数据写入数据库
phone_no = rfm_pd.index # 索引列
rfm_wscore = rfm_pd['rfm_wscore'] #RFM 加权得分列
rfm_comb = rfm_pd['rfm_comb'] #RFM组合得分列
timestamp = time.strftime('%Y-%m-%d',time.localtime(time.time())) # 写库日期
print('开始写入数据库表 {0}'.format(table_name)) # 输出开始写库的提示信息
for i in range(rfm_pd.shape[0]):
insert_sql = "INSERT INTO `%s` VALUES ('%s',%s,%s,%s,%s,%s,'%s')" % \
(table_name, phone_no[i], r_score.iloc[i], f_score.iloc[i], m_score.iloc[i], rfm_wscore.iloc[i],
rfm_comb.iloc[i], timestamp) # 写库SQL依据
cursor.execute(insert_sql)
con.commit()
cursor.close()
con.close()
print('写入数据库结束,总记录条数为: %d' %(i+1))
先从数据集合 rfm_pd (rfm_pd 是一个DataFrame)中获取到rfm的每个字段, ’....{0}'.format(table_name)表示的是在字符串中拼接参数,{0}代表一个字符串占位符。
四、案例结果分析
根据RFM模型的建立,我们在数据库里生成了数据。

然后前段工程师根据数据库里的数据得到了用户RFM的价值打分页面,如图(后台展示页面)。
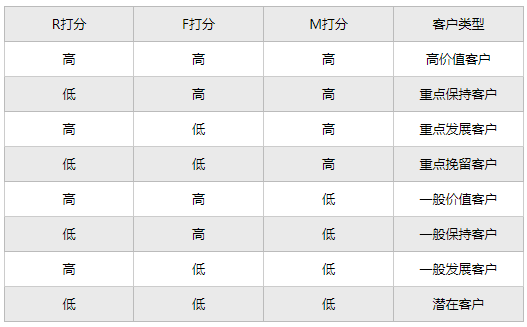
运营人员根据页面的打分情况来衡量客户价值和客户创利能力,了解客户差异。将客户分别按照R、F、M参数分组后,假设某个客户同时属于R5、F4、M3三个组,则可以得到该客户的RFM代码543。同理,我们可以推测,有一些客户刚刚成功交易、且交易频率高、总采购金额大,其RFM代码是555,还有一些客户的RFM代码是554、545……每一个RFM代码都对应着一小组客户,开展市场营销活动的时候可以从中挑选出若干组进行。
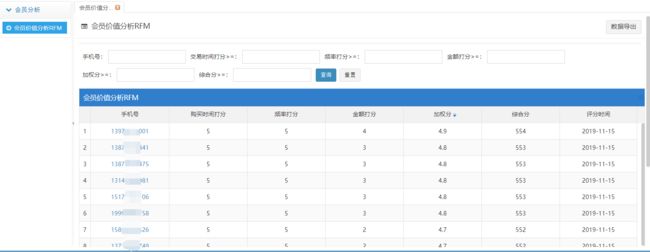
用户是根据RFM的打分倒序排列,可以直接找到重点客户的信息,点开手机号,查看客户的详细信息(这一步由前端开发人员实现),针对重点客户展开各种个性化营销。
RFM三个指标每个维度再细分出5份,这样就能够细分出5x5x5=125类用户,再根据每类用户精准营销……显然125类用户已超出普通人脑的计算范畴了,更别说针对125类用户量体定制营销策略。实际运用上,我们只需要把每个维度做一次两分即可,这样在3个维度上我们依然得到了8组用户。
这样,就可以得到以下解读(编号次序RFM,1代表高,0代表低)
重要价值客户(111):最近消费时间近、消费频次和消费金额都很高,必须是VIP啊!
重要保持客户(011):最近消费时间较远,但消费频次和金额都很高,说明这是个一段时间没来的忠诚客户,我们需要主动和他保持联系。
重要发展客户(101):最近消费时间较近、消费金额高,但频次不高,忠诚度不高,很有潜力的用户,必须重点发展。
重要挽留客户(001):最近消费时间较远、消费频次不高,但消费金额高的用户,可能是将要流失或者已经要流失的用户,应当基于挽留措施。
案例结论:
- 表现处于一般水平以上的用户的比例太小,低于1%(R、F、M三个维度得分均在3以上的用户数),VIP客户太少。
- 会员中99%以上的客户消费状态都不容乐观,主要体现在消费频率低R、消费总金额低M。这可能跟公司的地铁出行的业务有关系,公司的业务分布在全国中小城市,大部分用户都是使用一次的用户。
- 低价值客户有262个,占总比例的 0.4%,运营人员可以导出下载这批用户。
下一节,讲一下在linux服务器上部署python应用。