
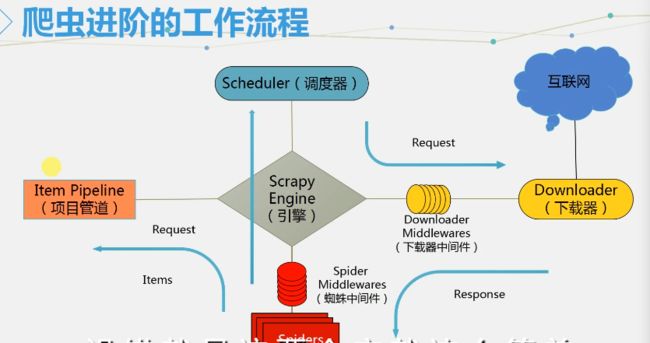
这些组件最重要的思路就是拦截,即过滤
item管道:作用一:入库
校验:一是可以在管道,但主要是在item定义字段校验
管道是什么
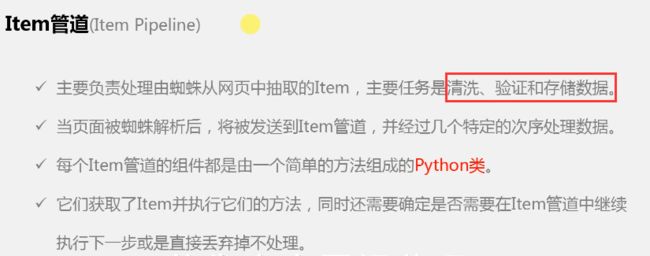
Item管道(Item Pipeline):
- 主要负责处理有蜘蛛从网页中抽取的Item,主要任务是清洗、验证和存储数据。
- 当页面被蜘蛛解析后,将被发送到Item管道,并经过几个特定的次序处理数据。
- 每个Item管道的组件都是有一个简单的方法组成的Python类。
- 它们获取了Item并执行它们的方法,同时还需要确定是否需要在Item管道中继续执行下一步或是直接丢弃掉不处理。
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。

数据去重在管道里面做是下策。在管道里面去重只是预防。好的去重是在请求url和解析url时候就去重,清洗html建议在spider里面做。

每一个管道都是一个类,每个类里面都有这几种方法。
一个管道一个管道,一层滤网一层滤网
最后一个方法少修改初始化。

必须return item 不然下面的管道就接不上了。给价格增加增值税。

item去重,见到粗暴,不推荐。要么抛异常,要么返回item,不要别的。
set集合是不重复的。

打开一个文件名。
序列号,写进去一系列字符串
加入了mongodb的两个参数,并且用init初始化。mongouri和数据库名两个参数。

向mongodb里面插入数据。
Item管道主要函数:
1. process_item(self, item, spider) —— 必须实现(也是用的最多的方法);
每个 Item Pipeline 组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的 item 将不会被之后的 pipeline 组件所处理
需要传入的参数为:
- item (Item 对象) : 被爬取的 item
- spider (Spider 对象) : 爬取该 item 的 spider
该方法会被每一个 item pipeline 组件所调用,process_item 必须返回以下其中的任意一个对象:
- 一个 dict
- 一个 Item 对象或者它的子类对象
- 一个 Twisted Deferred 对象
- 一个 DropItem exception;如果返回此异常,则该 item 将不会被后续的 item pipeline 所继续访问
注意:该方法是Item Pipeline必须实现的方法,其它三个方法(open_spider/close_spider/from_crawler)是可选的方法
举例说明1
以下假设的管道,它调整 price那些不包括增值税(price_excludes_vat属性)的项目的价格,并删除那些不包含价格的项目
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']: #是否有价格
if item['price_excludes_vat']: #如果价格不包括增值税,则把价格乘上一个增值税系数
item['price'] = item['price'] * self.vat_factor
return item
else: #如果没有价格,则抛弃这个item
raise DropItem("Missing price in %s" % item)
举例说明2
此例主要是用于查找重复Item并删除已处理的Item的过滤器。假设我们的Item具有唯一的ID,但是我们的Spider会返回具有相同id的多个Item:
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def init(self):
self.ids_seen = set() #初始化中,创建一个空集合
def process_item(self, item, spider):
查看id是否在ids_seen中,如果在,就抛弃该Item,如果不在就添加到ids_seen中,下一次其它Item有相同的id就抛弃那个Item
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item #记住一定要返回Item
2.open_spider(self, spider) —— 非必需,为爬虫启动的时候调用;
当 spider 被开启时,这个方法被调用。可以实现在爬虫开启时需要进行的操作,比如说打开一个待写入的文件,或者连接数据库等
需要传入的参数:
- spider (Spider 对象) : 被开启的 spider
3. close_spider(self, spider) —— 非必需, 为爬虫关闭的时候调用;
当 spider 被关闭时,这个方法被调用。可以实现在爬虫关闭时需要进行的操作,比如说关闭已经写好的文件,或者关闭与数据库的连接
需要传入的参数:
- spider (Spider 对象) : 被关闭的 spider
举例说明:
将项目写入JSON文件
以下管道将所有抓取的Item(来自所有蜘蛛)存储到单个items.json文件中,每行包含一个项目,以JSON格式序列化:
import json
class JsonWriterPipeline(object):
def open_spider(self, spider):
在爬虫开始时打开文件
self.file = open('items.json', 'w')
def close_spider(self, spider):
在爬虫结束时关闭文件
self.file.close()
def process_item(self, item, spider):
把爬取到的item转换为json格式,保存进文件
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item #注意要返回item
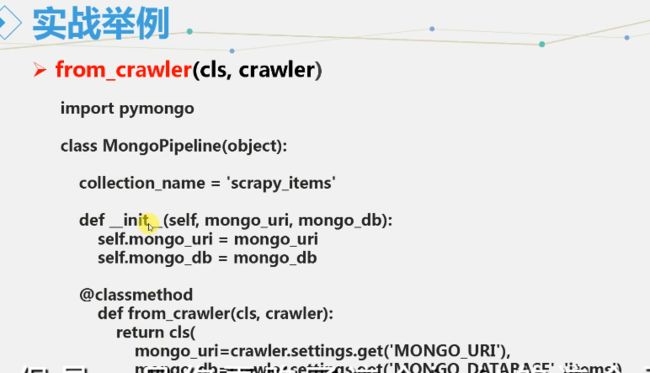
4. from_crawler(cls, crawler) —— 非必需,也是在启动的时候调用,比 open_spider早。
该类方法用来从 Crawler 中初始化得到一个 pipeline 实例;它必须返回一个新的 pipeline 实例;Crawler 对象提供了访问所有 Scrapy 核心组件的接口,包括 settings 和 signals
需要传入的参数:
- crawler (Crawler 对象) : 使用该管道的crawler
举例说明:
此例主要使用pymongo将项目写入MongoDB。MongoDB地址和数据库名称在Scrapy设置中指定; MongoDB集合以item类命名
from_crawler()方法是创建通往Crawler的pipeline,返回一个新的pipeline实例
这个例子的要点是显示如何使用from_crawler()方法和如何正确清理资源
通过类方法 from_crawler() 在内部初始化得到了一个 pipeline 实例,初始化的过程中,使用了 mongo_uri 以及 mongo_db 作为构造参数
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def init(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(dict(item))
return item