服务器环境:Ubuntu15.04、jdk1.7、Hadoop2.7.1
1. 创建spark用户####
为了隔离Hadoop和其它软件, 创建了可以登陆的 spark 用户,并使用 /bin/bash 作为 shell:
sudo useradd -m spark-s /bin/bash
设置spark用户密码:
sudo passwd spark
可为 spark用户增加管理员权限,避免部署时候遇到一些奇怪的权限问题:
sudo adduser hadoop sudo
添加完用户后,用户spark账户登录服务器,进行服务器配置。
2. SSH登录配置#####
集群、单节点模式都需要用到 SSH登陆 ,并且配置ssh的免密码登录,在集群启动时候可以免去输入密码的麻烦。Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
测试使用ssh登录本机:
ssh localhost
登录成功后可以输入exit退出

设置ssh无密码登录
设置免密码登录,生成私钥和公钥,利用 ssh-keygen 生成密钥,并将密钥加入到授权中。
生成公钥/私钥对:
ssh-keygen -t rsa -P ""
-P表示密码,-P '' 就表示空密码,也可以不用-P参数,这样就要三车回车,用-P就一次回车。它在/home/spark下生成.ssh目录,.ssh下有id_rsa和id_rsa.pub,前者为私钥,后者为公钥。
下面我们将公钥追加到authorized_keys中,它用户保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
再次使用ssh登陆localhost,就不再需要输入密码:
ssh localhost
记得退出登录,继续进行配置exit

3. 安装Java环境####
安装JDK:
sudo apt-get update
sudo apt-get install openjdk-7-jdk
安装成功后,使用java -version java版本

配置Java环境变量,如果使用上面的方法安装jdk,那么Java的安装路径应该是/usr/lib/jvm/java-7-openjdk-amd64,但是如果不能确定,可以使用如下命令:
update-alternatives - -config java
输入结果:/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
我们只取前面的部分 /usr/lib/jvm/java-7-openjdk-amd64
配置.bashrc文件:
sudo vim ~/.bashrc #如果没有vim 请另行安装vim
在文件末尾追加下面内容,然后保存
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
执行下面命,使添加的环境变量生效:
source ~/.bashrc
测试Java环境变量结果:
echo $JAVA_HOME
如果输出/usr/lib/jvm/java-7-openjdk-amd64 则表示配置成功
4. 配置Hadoop####
4.1 下载安装Hadoop
Hadoop 2 可以通过 http://mirror.bit.edu.cn/apache/hadoop/common/ 下载,一般选择下载最新的稳定版本,即下载 “stable” 下的 hadoop-2.x.y.tar.gz 这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
我直接下载编译好的压缩包:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
解压缩:
tar xfz hadoop-2.7.1.tar.gz
将安装包移动到usr/local/hadoop
sudo mv hadoop-2.6.0 /usr/local/hadoop
更改hadoop文件夹的所有者为spark用户
sudo chown -R spark /usr/local/hadoop
测试hadoop是否可用
/usr/local/hadoop/bin/hadoop version
正确显示hadoop版本表示可用
4.2 Hadoop相关环境变量配置
打开./bashrc文件:
sudo vim ~/.bashrc
在.bashrc文件末尾添加相关环境变量:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
应用环境变量:
source ~/.bashrc
4.3 hadoop相关配置文件的配置
-
配置hadoop-env.sh
sudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh更改JAVA_HOME为
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 -
配置core-site.xml
sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml在
fs.default.name
hdfs://localhost:9000
-
配置yarn-site.xml
sudo vim $HADOOP_HOME/etc/hadoop/yarn-site.xml在
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
-
配置mapred-site.xml
HADOOP_HOME目录下有一个配置模板$HADOOP_HOME/etc/hadoop/mapred-site.xml.template,先拷贝到$HADOOP_HOME/etc/hadoop/mapred-site.xml。cp $HADOOP_HOME/etc/hadoop/mapred-site.xml{.template,}
编辑$HADOOP_HOME/etc/hadoop/mapred-site.xml文件:
sudo vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
在`
mapreduce.framework.name
yarn
4.3 配置HDFS文件目录
1. 创建文件目录
假设准备将数据存放在/mnt/hdfs,方便起见,现将其设为一个环境变量:
export HADOOP_DATA_DIR=/mnt/hdfs
创建DataNode和NameNode的存储目录,同时将这两个文件夹的所有者修改为spark:
sudo mkdir -p $HADOOP_DATA_DIR/namenode
sudo mkdir -p $HADOOP_DATA_DIR/datanode
sudo chown -R spark $HADOOP_DATA_DIR
2. 配置hdfs-site.xml文件
sudo vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
在
dfs.replication
1
dfs.namenode.name.dir
file:/mnt/hdfs/namenode
dfs.datanode.data.dir
file:/mnt/hdfs/datanode
3. 格式化HDFS文件系统
使用下列命令格式化HDFS文件系统:
hdfs namenode -format
5. 启动Hadoop####
启动HDFS:
$HADOOP_HOME/sbin/start-dfs.sh
启动yarn:
$HADOOP_HOME/sbin/start-yarn.sh
HDFS和yarn的web控制台默认监听端口分别为50070和8088。可以通过浏览放访问查看运行情况。
停止命令:
$HADOOP_HOME/sbin/stop-dfs.sh
$HADOOP_HOME/sbin/stop-yarn.sh
如果一切正常,使用jps可以查看到正在运行的Hadoop服务,在我机器上的显示结果为:
5003 SecondaryNameNode
5341 NodeManager
4798 DataNode
5182 ResourceManager
7311 Jps
4639 NameNode
6. 运行WordCount测试####
单机模式安装完成,下面通过执行hadoop自带实例WordCount验证是否安装成功。
查看HDFS根目录下的文件:
hdfs dfs -ls /
在HDFS上创建input目录:
hdfs dfs -mkdir /input
将Hadoop路径下的README.txt传到HDFS:
hdfs dfs -put $HADOOP_HOME/README.txt /input/
完成后运行如下命令,进行Word Count操作:
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.1-sources.jar org.apache.hadoop.examples.WordCount /input /output

查看计算结果:
hdfs dfs -cat /output/*
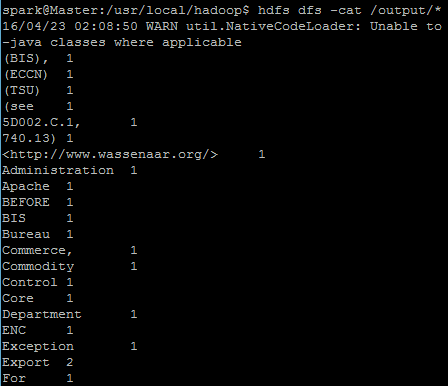
最后Hadoop单节点的配置就完成了。如有什么问题,希望大家批评指正。
7. 参考资料####
1. Hadoop单节点安装
2. Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
3. Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04