大数据概述
大数据的定义
大数据,指无法在可承受的时间范围内用常规软件进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
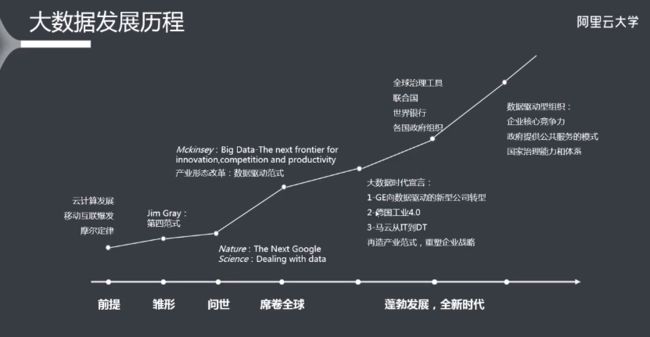
《第三次浪潮》-托夫勒>>大数据应用-麦肯锡>>《大数据时代》-舍恩伯格>>计算助理-谷歌>>国内规模化-阿里云
发展历程及特点
主要特征:4V
- Volume 体积大
- Variety 类型多
- Value 有价值
- Velocity 变化快
换个角度
- 大:数据体量大
- 杂:数据类型杂
- 全:数据完备性
- 多:来源维度多
- 快:增长变化快
- 久:积累时间长
- 活:在线随时用
- 简:简单易处理
- 稀:价值密度地
- 联:数据相关性
如何产生的?
为什么会有大数据?
- 移动互联网带来爆炸式的增长
- 数据作为资产其价值得到认可
- 存储和计算能力的飞速发展
大数据从哪来?
媒体数据、网络日志、公共设施、单位组织、大型设备、工业领域、地理位置、基因图谱
大数据的价值
解决四种问题
- 坐井观天
- 一叶障目
- 盲人摸象
- 城门鱼殃
提示两种能力
- 一叶知秋
- 运筹帷幄
大数据核心价值
- 洞察insight
- 预测predict
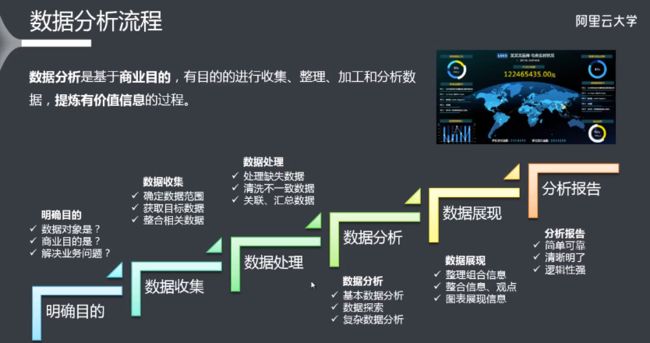
存储、计算与分析
分布式存储
分布式计算
数据分析
- 数据采集与处理
- 数据质量与管理
- 机器学习
- 数据可视化
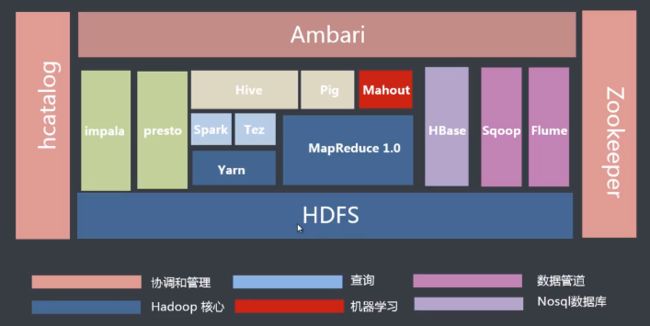
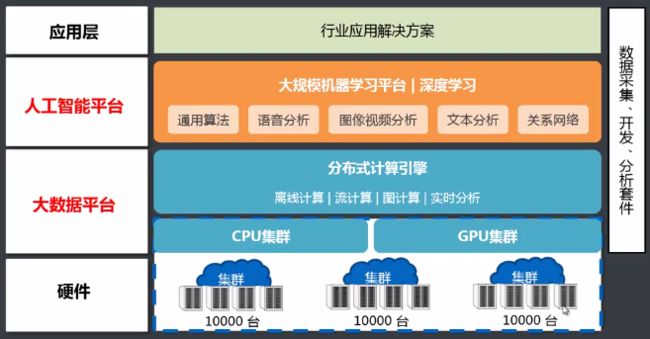
大数据流行技术
Hadoop生态圈
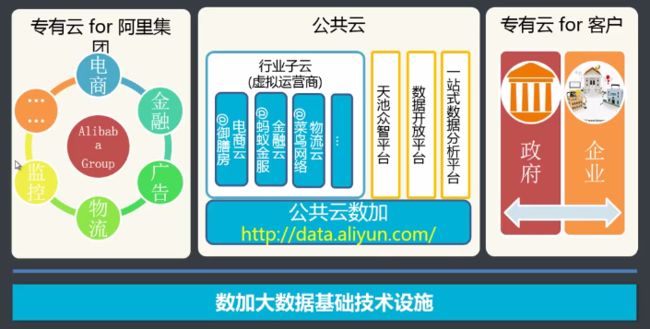
阿里云体系
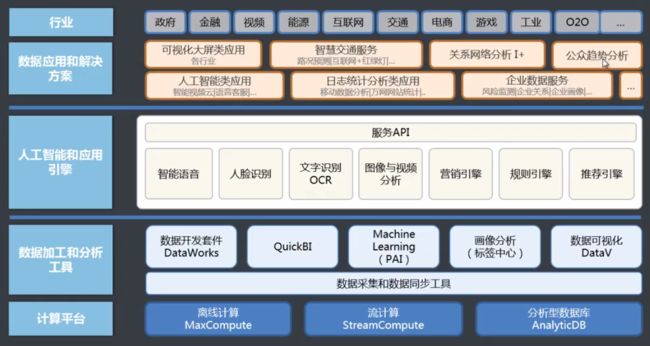
数加平台介绍
数加定位

计算引擎:离线计算 流式计算 在线计算
数加业务范围
分析型数据库
AnalyticDB产品介绍
OLAP:在线分析处理,以分析为主
OLTP:在线业务系统,以业务支撑为主
OLAP(On-Line Analytical Processing)是数据仓库的主要的应用,专门设计用于支持复杂的分析操作
主要概念:
- 维度:观察事物的角度(属性),即从哪些方面来观察
- 度量:也称为事实,即记录了一次实际的测量、购买等发生的事实,包含维度和测量值
MPP数据库
MMP(Massive Parallel Processing,大规模并行处理):由多个耦合处理单元组成,每个单元拥有自己的CPU、内存、存储等,每个单元内部都有操作系统和管理数据库的实例副本,最大特点在于不共享资源
- 私有资源
- 分布式存储
- 分布式计算
- 任务并行执行
- Share-nothing
- 横向扩展
分析型数据库AnalyticDB
产品特点
- 分档存储
- 自由查询
- 智能优化 (基于历史的优化)
- 方便接口
- 分层安全
- 弹性多租户
基本概念
表组:是一系列可以发生关联的表的集合,是一个逻辑的概念。可分为普通表组和维度表组
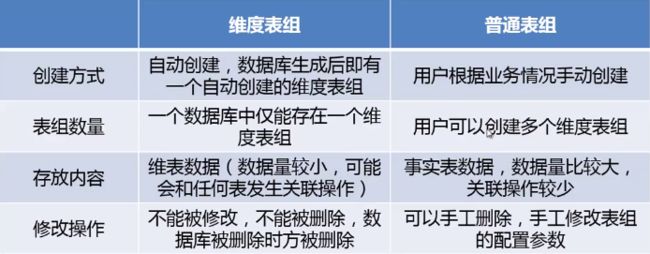
表组特点:
- 表组是数据物理分配的最小单元
- 同表组内的表才可以快速hash join
- 同一个表组内的表共享一些配置
- 建议同表组中的表一级分区一致
MaxCompute
目标:
- 了解MaxCompute特点
- 掌握客户端工具的使用
- 掌握MaxCompute SQL
- 了解权限管理与项目空间保护
产品介绍
大数据计算服务(MaxCompute,原ODPS)提供针对TB/PB级数据、实时性要求不高的分布式处理能力,应用于数据分析、挖掘、商业智能等领域。
MaxCompute对象:

分区表指的是在创建表时指定分区键,即指定表内的某几个字段作为分区列。

在使用数据时如果指定了需要访问的分区名称,则只会读取相应的分区,避免全表扫描,提高处理效率,降低费用
其他概念:
任务(Task):MaxCompute基本计算单元,SQL即MR都是通过任务完成的
实例(Instance):任务的一个具体实例,表示实际运行的task
沙箱(SandBox):按照安全策略限制程序行为的执行环境
- 不允许直接访问本地文件
- 不允许直接访问分布式文件系统
- 不允许JNI调用机制
- 不允许起子进程执行Linux命令
- 不允许获取本地IP地址
- Java反射限制
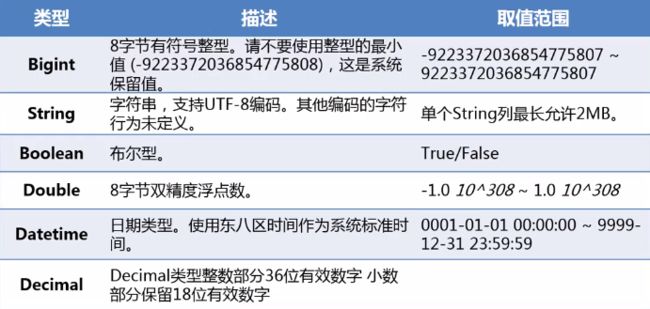
数据类型:
架构介绍

连接使用
- 自带命令行工具MaxCompute Console
- 可视化客户端工具:Intelij Studio
- Eclipse
- 管理控制台
数据上传和下载
主要方式有:
- Tunnel 命令
- Tunnel SDK
- 管理控制台
- 数据同步工具
这里主要介绍 Tunnel 命令
Tunnel 基本语法:tunnel
数据上传:tunnel upload [options]
数据下载:tunnel download [options] <[project.]table[/partition]>
几个重要参数:

关于分隔符:
- 支持多个字符的列分隔符和行分隔符
- 支持控制字符等不可见字符做分隔符
- 列分隔符不能包含行分隔符
- 转义字符分隔符,在命令行模式下只支持\r,\n和\t
sql组成:
DDL:数据库模式定义语言,关键字:create
DML:数据操纵语言,关键字:Insert、delete、update
DCL:数据库控制语言 ,关键字:grant、remove
DQL:数据库查询语言,关键字:select
DDL 介绍
基本语法:
建表:create table [if not exists] table_name
删表:drop table [if exists] table_name;
修改表名:alter table table_name rename to new_table_name;
表的生命周期:
生命周期(LifeCycle):MaxCompute 表中的数据,从最后一次更新的时间算起,在经过指定的时间后没有变动,则此表将 MaxCompute 自动回收(删除)。此指定时间就是该MaxCompute 表的生命周期。
快捷建表 CTAS
两种谓语动词 like 和 as
CREATE TABLE < table_name> AS SELECT FROM WHERE...;
CREATE TABLE < table_name> LIKE ;
like 和 as 的区别:
- 数据
- as可以带入数据,可以依赖于多张表
- like只能复制单张表的表结构,不能带入数据
- 属性
- as不能带入LIFECYCLE、分区键信息、注释等
- LIKE不能带入LIFECYCLE、可以带入分区键信息、注释等
分区操作:
添加分区:alter table table_name add [if not exists] partition partition_spec
删除分区:alter table table_name drop [if exists] partition_spec
修改表属性:
添加列:alter table table_name add colums (col_name1 type1, col_name2 type2 ...)
改列名:alter table table_name change column old_col_name rename to new_col_name;
表注释:alter table table_name set comment 'tbl comment';
列注释:alter table table_name change column col_name comment 'comment';
生命周期:alter table table_name set lifecycle days;
修改时间:alter table table_name touch [partition(partition_col='partition_col_value', ...
视图操作:
创建视图:CREATE [OR REPLACE] VIEW [IF NOT EXISTS] view_name
删除视图:DROP VIEW [IF NOT EXISTS] view_name;
重命名视图:ALTER VIEW view_name RENAME TO new_view_name;
DML介绍
查询 SELECT
select [all | distinct] select_expr, select_expr, ...
from table_reference
[where where_condition]
[group by col_list]
[order by order_condition]
[distribute by distribute_condition [sort by sort_condition] ]
[limit number]
更新数据 INSERT INTO/OVERWEITE
输出到普通表或静态分区
insert overwrite | into table tablename [partition (partcol1=val1, partcol2=val2 ...)]
select_statement
from from_statement;
输出到动态分区
insert overwrite table tablename partition (partcol1, partcol2 ...)
select_statement from from_statement;
注:
如果目有多级分区,在运行insert语句时允许指定部分分区为静态,但是静态分区必须是高级分区
动态生成的分区值不可以为null
多路输出 MULTI INSERT
from from_statement
insert overwrite | into table tablename1
[partition (partcol1=val1, partcol2=val2 ...)]
select_statement1
[insert overwrite | into table tablename2 [partition ...]
select_statement2]
多路输出的限制:
单个SQL里最多可以写出256路输出
对于分区表,同一个目标分区不可以出现多次
对于未分区表,该表不能作为目标表多次出现
对于同一张分区表的不同分区,不能同时有insert overwrite 和 insert into 操作
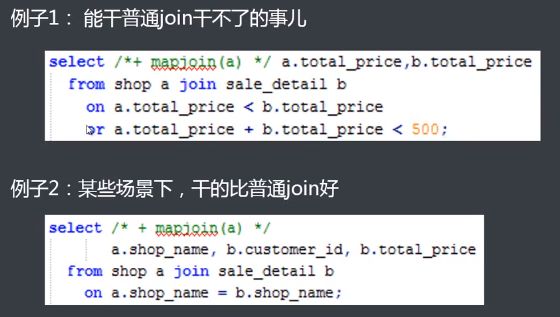
表关联 JOIN

MAPJOIN
使用情景:一个大表和一个或多个小表做join
基本原理:将用户指定的小表全部加载到执行join操作的程序的内存中,从而加快join的执行速度
分支表达式 CASE WHEN
两种 CASE WHEN 语法
CASE
WHEN then
WHEN then
...
else
END
CASE
WHEN then
WHEN then
...
else
END
内置函数
- 值函数:数学运算函数、字符串处理函数、日期处理函数
- 窗口函数:常见统计量类、排名类、偏移定位类、分组抽样类
- 聚合函数:常见统计量类、字符串类
- 其他函数:类型转换函数、分支判断函数、其他
其它使用方式
用户自定函数(User Defined Function , UDF)
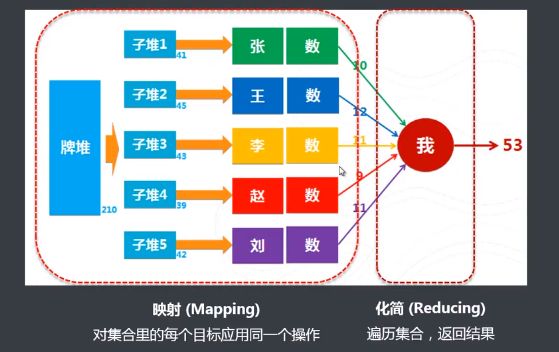
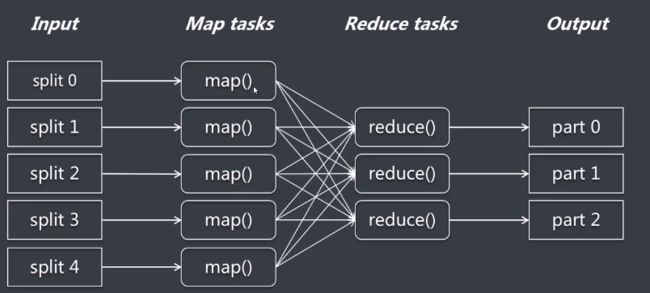
MapReduce
Graph

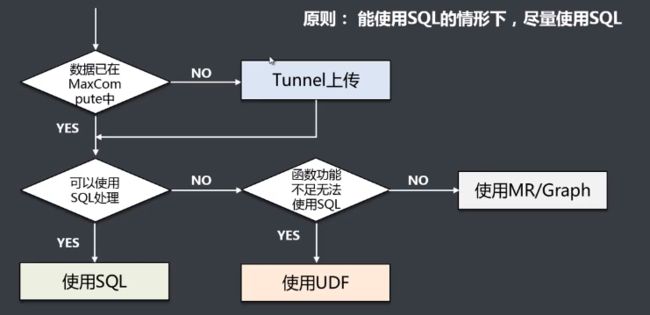
选择流程
大数据开发套件DataIDE
DataIDE 产品概述
大数据开发套件(DataIDE) 是阿里云数加重要的Paas平台产品,基于MaxCompute作为核心的计算、存储引擎,提供了海量数据的离线加工分析、数据挖掘的能力。提供全面托管的工作流服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
- 全面托管的调度
- 多种任务类型
- 可视化开发
- 监控告警
数据开发流程
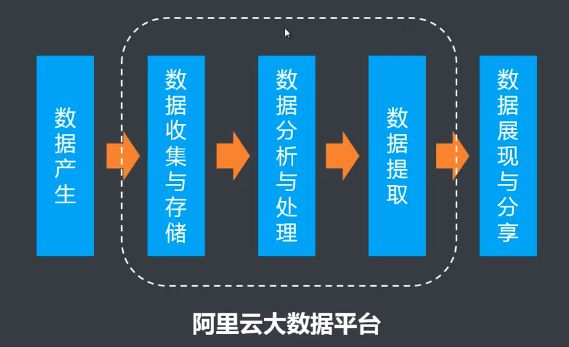

DataIDE应用场景
- 将业务系统产生的数据轻松上云,构建大型数据仓库和BI应用,利用MaxCompute强大的海量存储与数据处理能力
- 基于大数据开发套件快速使用和分析数据,将大数据加工结果导出后直接应用于业务系统,实现数据化运营
- 针对作业调度与运维的复杂性,大数据开发套件提供统一友好的调度系统和可视化调度运维界面,解决运维管理不便等问题
DataIDE基本概念
任务(Task):对数据执行的操作,通常每个任务使用0或0个以上数据表(数据集)作为输入,生成一个或多个数据表(数据集)作为输出。DataIDE中任务主要分为三种:节点任务、工作流任务以及内部节点。
实例(Instance):代表了某个任务在某时某刻执行的一个快照,包含任务的运行时间、运行状态运行日志等信息。在调度系统中的任务经过调度系统、手动触发运行后会生成一个实例。在DataIDE的调度系统自动调度的任务,会提前生成对应的实例。
提交(Submit):提交指开发的节点任务、工作流任务从开发IDE环境发布到调度系统的过程。完成提交以后,相应的代码、调度配置全部合并到调度系统中,调度系统按照相关配置进行调度操作。未提交的节点任务、工作流任务不会进入到调度系统。
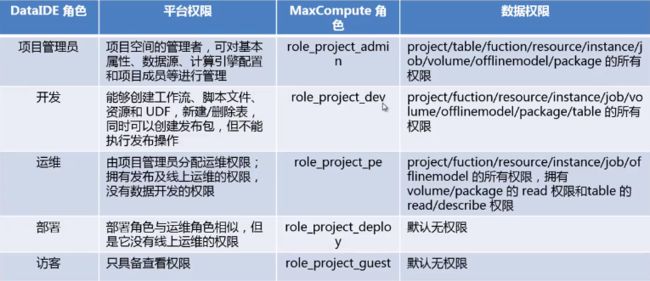
DataIDE中的角色
多环境
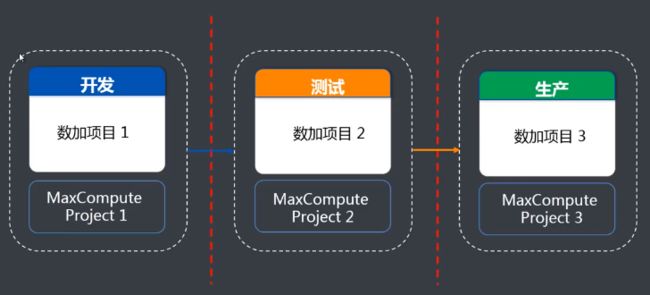
分为开发、测试、生产环境
DataIDE操作演示
- 服务开通
- 控制台介绍
- 项目管理
- 数据集成
- 数据开发
- 数据管理
- 运维中心
配套实验:DataIDE基本操作
- 创建项目
- 数据同步
- SQL任务
- 调度依赖
- 任务运维
推荐引擎RecEng
推荐系统介绍
什么是推荐系统?
利用电子商务网站向客户提供商品信息和建议,帮助用户觉得购买什么产品,模拟销售人员帮助客户完成购买过程
什么是个性化推荐系统?
个性化推荐系统是根据用户的兴趣特点和购买行为,向用户推荐感兴趣的信息和商品。
个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。

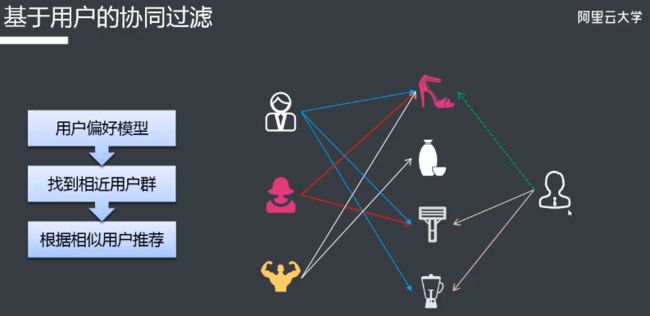
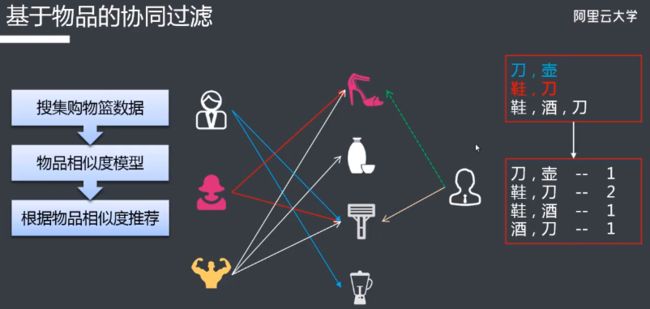
推荐引擎RecEng介绍
阿里云推荐引擎(Recommendation Engine,RecEng)是在阿里云公有云环境下建立的一套推荐服务框架,目标是让广大中小企业能够使用这套框架快速搭建满足自身业务需求的推荐服务。
- 简单便捷
- 使用门槛低
- 算法开放

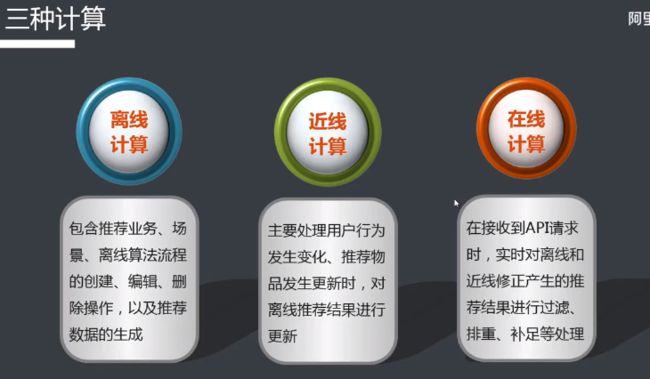
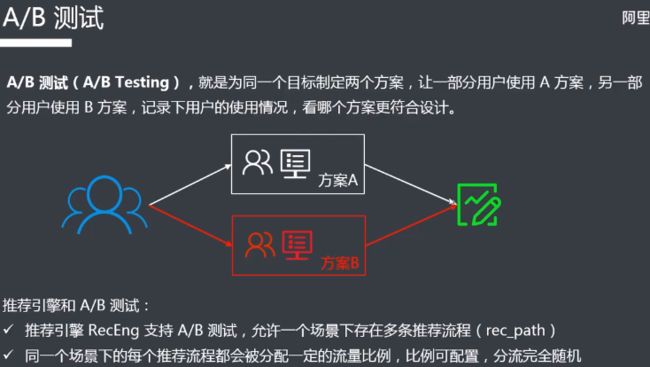
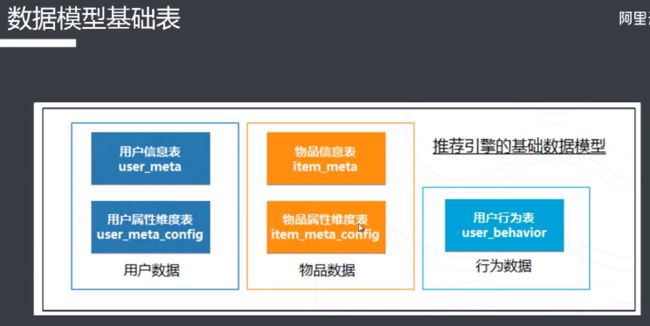
推荐引擎RecEng使用


配套实验
- 开通云资源
- 数据上传加工
- 推荐引擎配置
- 启动任务
- 获取推荐结果
Quick BI数据可视化(静态)
目标:
- 了解DataV的产品特点
- 了解可视化大屏的使用场景
- 使用DataV模板制作可视化大屏
DataV 产品介绍
DataV是阿里云提供的数据可视化在线工具。通过拖拽式的操作,使用数据连接、可视化组件库、行业设计模板库、多终端适配与发布运维等功能,让非专业人员也可以快速的将数据的价值通过视觉进行传达
- 多种场景模板
- 丰富开放的图标库
- 支持多种数据源
- 零门槛图形化界面
- 支持数据交互分析
- 多种适配与发布方式
DataV 大屏介绍



大屏设计原则:
DataV数据可视化(动态)
目标:
- 了解DataV的产品特点
- 了解可视化大屏的使用场景
- 使用DataV模板制作可视化大屏
DataV 产品介绍
DataV是阿里云提供的数据可视化在线工具。通过拖拽式的操作,使用数据连接、可视化组件库、行业设计模板库、多终端适配与发布运维等功能,让非专业人员也可以快速的将数据的价值通过视觉进行传达
- 多种场景模板
- 丰富开放的图标库
- 支持多种数据源
- 零门槛图形化界面
- 支持数据交互分析
- 多种适配与发布方式
DataV 大屏介绍
大屏设计原则:
机器学习
目标:
- 了解机器学习及阿里云PAI
- 了解简单的聚类算法和分类算法
- 了解机器学习的基本使用流程
- 使用PAI进行聚类/分类分析
机器学习介绍

分类

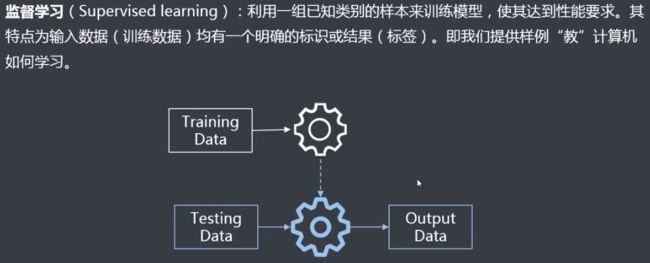


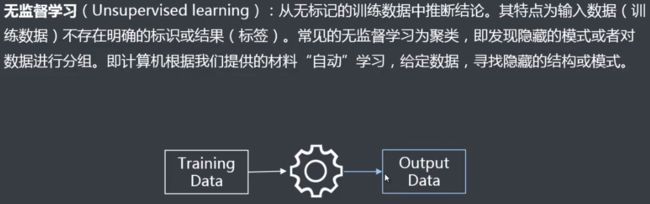
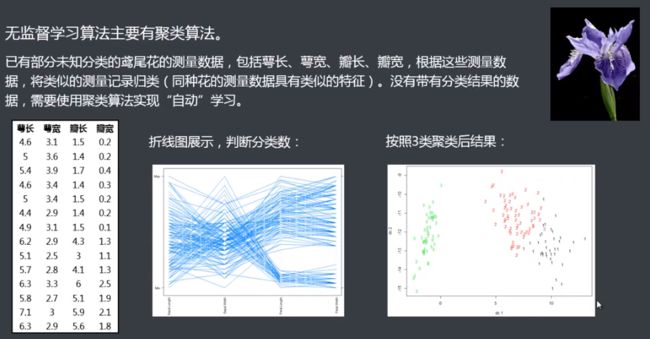
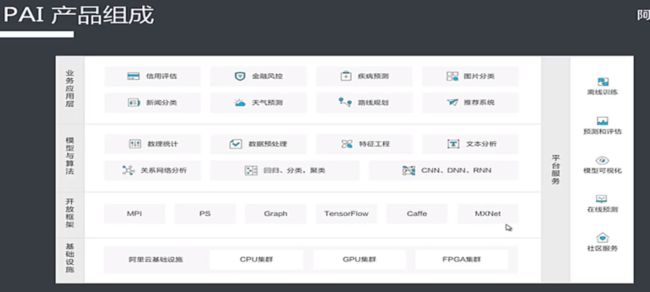
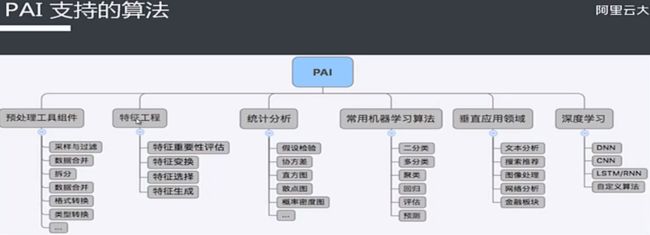
阿里云机器学习PAI介绍


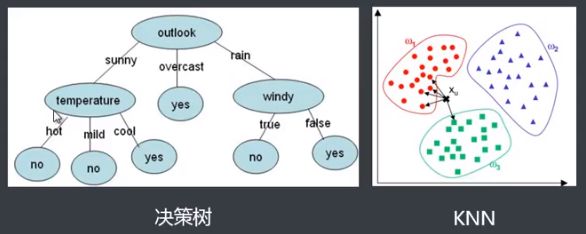
分类算法KNN介绍
分类算法通过对已知类别训练集的分析,从中发现分类规则,以此预测新数据的类别。分类算法的应用十分广泛,银行风险评估、客户类别分类、文本检索和搜索引擎分类、安全领域中的入侵检测以及软件项目中的应用等。
按原理分类:
- 基于统计的:如贝叶斯分类
- 基于规则的:如决策树算法
- 基于神经网络的:神经网络算法
-
基于距离的:KNN(K最近邻)
常用评估指标:
- 精确率:预测结果与实际结果的比例
- 召回率(查勤率):预测结果中某类结果的正确覆盖率
- F1-Score:统计量,综合评估分类模型,取值在0-1之间





KNN优缺点
优点
- 原理简单,容易理解,容易实现
- 重新训练代价较低
- 时间、空间复杂度取决于训练集(一般不算太大)
缺点
- KNN属于lazy-learning算法,得到结果的及时性差
- k值对结果影响大(试想k=1和k=N的极端情况)
- 不同类记录相差较大时容易误判
- 样本点多时,计算量较大
- 相对于决策树,结果可解释性不强
聚类算法K-Means介绍
聚类:就是将相似的事物聚集在一起,而将不相似的事物划分到不同的类别的过程。它是一种探索性的分析,不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。
常见算法:层次聚类、划分聚类、基于密度的聚类
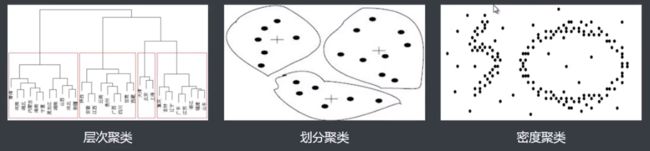

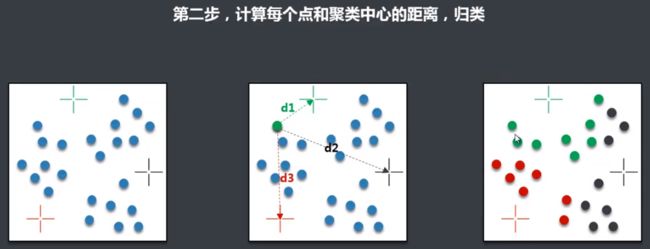
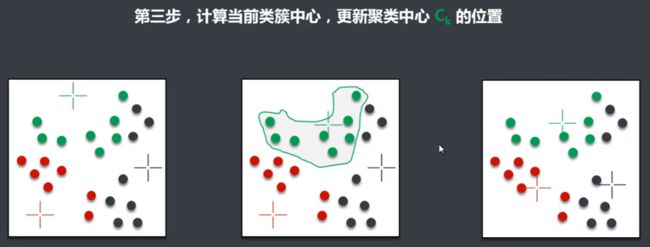
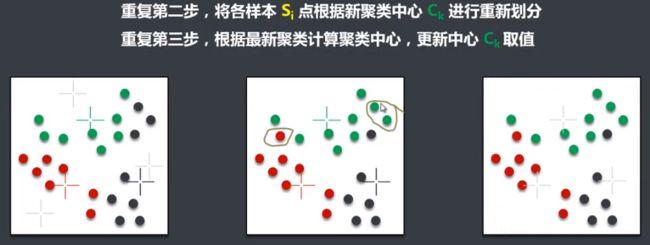


K-Means优缺点
优点:
- 原理简单,容易理解,容易实现
- 聚类结果容易解释
- 聚类结果相对较好
缺点:
- 分类个数k需要事先指定,且指定的k值不同,聚类结果相差较大
- 初始的k个类簇中心对最终结果有影响,选择不同,结果可能不同
- 能识别的类簇仅为球状,非球状的聚类效果很差
- 样本点多时,计算量较大
- 对异常值敏感,对离散值需要特殊处理
机器学习常见流程介绍
数据挖掘方法论




