什么是编码?
对于普通人来说,编码总是与一些秘密的东西相关联(加密与解密);对于程序员们来说,编码大多数是指一种用来在机器与人之间传递信息的方式.
但从广义上来讲,编码是从一种信息格式转换为另一种信息格式的过程,解码则是编码的逆向过程.接下来举几个使用到编码的例子:
当我们要把想表达的意思通过一种语言表达出来,其实就是在脑海中对信息进行了一次编码,而对方如果也懂得这门语言,那么就可以用这门语言的解码方法(语法规则)来获得信息(日常的说话交流其实就是在编码与解码).
程序员写程序时,其实就是在将自己的想法通过计算机语言进行编码,而编译器则通过生成抽象语法树,词义分析等操作进行解码,最终交给计算机执行程序(编译器产生的解码结果并不是最终结果,一般为汇编语言,但汇编语言只是CPU指令集的助记符,还需要再进行解码).
- 计算机只有两种状态(0和1),要想存储和传输多媒体信息,就需要用到编码和解码.
- 对数据进行压缩,其本质就是以减少自身占用的空间为前提进行重新编码.
了解了编码的含义,我们接下来重点探究Java中的字符编码.
本文作者为: SylvanasSun.转载请务必将下面这段话置于文章开头处(保留超链接).
本文首发自SylvanasSun Blog,原文链接: https://sylvanassun.github.io/2017/08/20/2017-08-20-Encode/
常见的字符集
字符集就是字符与二进制的映射表,每一个字符集都有自己的编码规则,每个字符所占用的字节也不同(支持的字符越多每个字符占用的字节也就越多).
-
ASCII : 美国信息交换标准码(American Standard Code for Information Interchange).学过计算机的都知道大名鼎鼎的
ASCII码,它是基于拉丁字母的字符集,总共记有128个字符,主要目的是显示英语.其中每个字符占用一个字节(只用到了低7位).
-
ISO-8859-1 : 它是由国际标准化组织(International Standardization Organization)在
ASCII基础上制定的8位字符集(仍然是单字节编码).它在ASCII空置的0xA0-0xFF范围内加入了96个字母与符号,支持了欧洲部分国家的语言.
-
GBK : 如果我们想要让电脑上显示汉字就必须要有支持汉字的字符集,GBK就是这样一个支持汉字的字符集,全称为<<汉字内码扩展规范>>,它的编码方式分为单字节与双字节:
00–7F范围内是第一个字节,与ASCII保持一致,之后的双字节中,前一字节是双字节的第一位(范围在81–FE,不包含80和FF),第二字节的一部分在40–7E,其他部分在80–FE.(这里不再介绍GB2313与GB18030,它们都是互相兼容的.)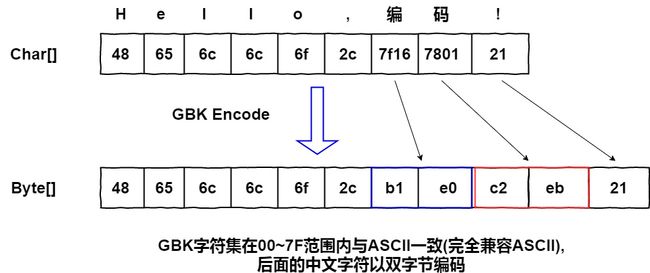
-
UTF-16 :
UTF-16是Unicode(统一码,一种以支持世界上多国语言为目的的通用字符集)的一种实现方式,它把Unicode的抽象码位映射为2~4个字节来表示,UTF-16是变长编码(UTF-32是真正的定长编码),但在最开始以前UTF-16是用来配合UCS-2(UTF-16的子集,它是定长编码,用2个字节表示所有Unicode字符)使用的,主要原因还是因为当时Unicode只有不到65536个字符,2个字节就足以应对一切了.后来,Unicode支持的字符不断膨胀,2个字节已经不够用了,导致一些只支持UCS-2当做内码的产品很尴尬(Java就是其中之一).
-
UTF-8 :
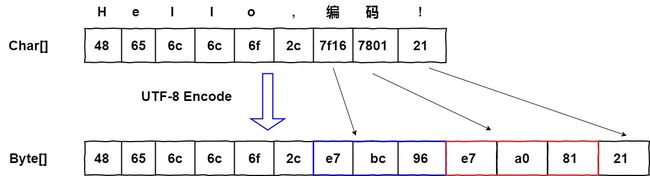
UTF-8也是基于Unicode的变长编码表,它使用1~6个字节来为每个字符进行编码(RFC 3629对UTF-8进行了重新规范,只能使用原来Unicode定义的区域,U+0000~U+10FFFF,也就是说最多只有4个字节),UTF-8完全兼容ASCII,它的编码规则如下:在
U+0000~U+007F范围内,只需要一个字节(也就是ASCII字符集中的字符).在
U+0080~U+07FF范围内,需要两个字节(希腊文、阿拉伯文、希伯来文等).在
U+0800~U+FFFF范围内,需要三个字节(亚洲汉字等).其他的字符使用四个字节.
Java中字符的编解码
Java提供了Charset类来完成对字符的编码与解码,主要使用以下函数:
-
public static Charset forName(String charsetName): 这是一个静态工厂函数,它根据传入的字符集名称来返回对应字符集的Charset类.
-
public final ByteBuffer encode(CharBuffer cb) / public final ByteBuffer encode(String str): 编码函数,它将传入的字符串或者字符序列进行编码,返回的ByteBuffer是一个字节缓冲区.
-
public final CharBuffer decode(ByteBuffer bb): 解码函数,将传入的字节序列解码为字符序列.
示例代码
private static final String text = "Hello,编码!";
private static final Charset ASCII = Charset.forName("ASCII");
private static final Charset ISO_8859_1 = Charset.forName("ISO-8859-1");
private static final Charset GBK = Charset.forName("GBK");
private static final Charset UTF_16 = Charset.forName("UTF-16");
private static final Charset UTF_8 = Charset.forName("UTF-8");
private static void encodeAndPrint(Charset charset) {
System.out.println(charset.name() + ": ");
printHex(text.toCharArray(), charset);
System.out.println("----------------------------------");
}
private static void printHex(char[] chars, Charset charset) {
System.out.println("ForEach: ");
ByteBuffer byteBuffer;
byte[] bytes;
if (chars != null) {
for (char c : chars) {
System.out.print("char: " + Integer.toHexString(c) + " ");
// 打印出字符编码后对应的字节
byteBuffer = charset.encode(String.valueOf(c));
bytes = byteBuffer.array();
System.out.print("byte: ");
if (bytes != null) {
for (byte b : bytes)
System.out.print(Integer.toHexString(b & 0xFF) + " ");
}
System.out.println();
}
}
System.out.println();
}
有的读者可能会对以上代码中的b & 0xFF产生疑惑,这是为了解决符号扩展问题.在Java中,如果一个窄类型强转为一个宽类型时,会对多出来的空位进行符号扩展(如果符号位为1,就补1,为0则补0).只有char类型除外,char是没有符号位的,所以它永远都是补0.
代码中调用了函数Integer.toHexString(),变量b在运算之前就已经被强转为了int类型,为了让数值不受到破坏,我们让b对0xFF进行了与运算,0xFF是一个低八位都为1的值(其他位都为0),而byte的有效范围只在低八位,所以结果为前24位(除符号位)都变为了0,低八位保留了原有的值.
如果不做这项操作,那么b又恰好是个负数的话,那这个强转后的int的前24位都会变为1,这个结果显然已经破坏了原有的值.
IO中的字符编码
Reader与Writer是Java中负责字符输入与输出的抽象基类,它们的子类实现了在各种场景中的字符输入输出功能.
在使用Reader与Writer进行IO操作时,需要指定字符集,如果不显式指定的话会默认使用当前环境的字符集,但我还是推荐显式指定一致的字符集,这样才不会出现乱码问题(Reader与Writer指定的字符集不一致或更改了环境导致字符集不一致等).
public static void writeChar(String content, String filename, String charset) {
OutputStreamWriter writer = null;
try {
FileOutputStream outputStream = new FileOutputStream(filename);
writer = new OutputStreamWriter(outputStream, charset);
writer.write(content);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (writer != null)
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static String readChar(String filename, String charset) {
InputStreamReader reader = null;
StringBuilder sb = null;
try {
FileInputStream inputStream = new FileInputStream(filename);
reader = new InputStreamReader(inputStream, charset);
char[] buf = new char[64];
int count = 0;
sb = new StringBuilder();
while ((count = reader.read(buf)) != -1)
sb.append(buf, 0, count);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (reader != null)
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return sb.toString();
}
Web中的字符编码
在Web开发中,乱码也是经常存在的一个问题,主要体现在请求的参数和返回的响应结果,最头疼的是不同的浏览器的默认编码甚至还不一致.
Java以Http的请求与响应抽象出了Request和Response两个对象,只要保持请求与响应的编码一致就能避免乱码问题.
Request提供了setCharacterEncoding(String encode)函数来改变请求体的编码,一般通过写一个过滤器来统一对所有请求设置编码.
request.setCharacterEncoding("UTF-8");
Response提供了setCharacterEncoding(String encode)与setHeader(String name,String value)两个函数,它们都可以设置响应的编码.
response.setCharacterEncoding("UTF-8");
// 设置响应头的编码信息,同时也告知了浏览器该如何解码
response.setHeader("Content-Type","text/html;charset=UTF-8");
还有一种更简便的方式,直接使用Spring提供的CharacterEncodingFilter,该过滤器就是用来统一编码的.
charsetFilter
org.springframework.web.filter.CharacterEncodingFilter
encoding
UTF-8
forceEncoding
true
charsetFilter
*
CharacterEncodingFilter的实现如下:
public class CharacterEncodingFilter extends OncePerRequestFilter {
private String encoding;
private boolean forceEncoding = false;
public CharacterEncodingFilter() {
}
public void setEncoding(String encoding) {
this.encoding = encoding;
}
public void setForceEncoding(boolean forceEncoding) {
this.forceEncoding = forceEncoding;
}
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
if(this.encoding != null && (this.forceEncoding || request.getCharacterEncoding() == null)) {
request.setCharacterEncoding(this.encoding);
if(this.forceEncoding) {
response.setCharacterEncoding(this.encoding);
}
}
filterChain.doFilter(request, response);
}
}
为什么Char在Java中占用两个字节?
众所周知,在Java中一个char类型占用两个字节,那么这是为什么呢?这是因为Java使用了UTF-16当作内码.
内码(Internal Encoding)就是程序内部所使用的编码,主要在于编程语言实现其char和String类型在内存中使用的内部编码.与之相对的就是外码(External Encoding),它是程序与外部交互时使用的字符编码.
值得一提的是,当初UTF-16是配合UCS-2使用的,后来Unicode支持的字符不断增多,UTF-16也不再只当作一个定长的2字节编码使用了,也就是说,Java中的一个char其实并不一定能代表一个完整的UTF-16字符.
String.getBytes()可以将该String的内码转换为指定的外码并返回这个编完码的字节数组(无参数版使用当前平台的默认编码).
public static void main(String[] args) throws UnsupportedEncodingException {
String text = "码";
byte[] bytes = text.getBytes("UTF-8");
System.out.println(bytes.length); // 输出3
}
Java还规定char与String类型的序列化是使用UTF-8当作外码的,Java中的Class文件中的字符串常量与符号名也都规定使用UTF-8.这种设计是为了平衡运行时的时间效率与外部存储的空间效率所做的取舍.
在SUN JDK6中,有一条命令-XX:+UseCompressedString.该命令可以让String内部存储字符内容可能用byte[]也可能用char[]: 当整个字符串所有字符处于ASCII字符集范围内时,就使用byte[](使用了ASCII编码)来存储,如果有任一字符超过了ASCII的范围,就退回到使用char[](UTF-16编码)来存储.但是这个功能实现的并不理想,所以没有包含在Open JDK6/Open JDK7/Oracle JDK7等后续版本中.
JavaScript也使用了UTF-16作为内码,其实现也广泛应用了CompressedString的思想,主流的JavaScript引擎中都会尽可能使用ASCII内码的字符串,不过这些细节都是对外隐藏的..
参考文献
ASCII - Wikipedia
ISO/IEC 8859-1 - Wikipedia
- GBK - Wikipedia
- UTF-16 - Wikipedia
- UTF-8 - Wikipedia
- Java 语言中一个字符占几个字节? - RednaxelaFX的回答