香农熵
变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。例如,在一个数据集dataset中,dataset = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],][0,1,'no'],[0,1,'no']],在数据集dataset中随机挑一个实例,挑出标签值为'yes'的概率为0.4,挑出标签值为‘no’的概率为0.6,这个数据集的熵值计算为
-0.6*log(0.6,2)-0.4*log(0.4,2) = 0.9709505944546687
下面有个函数可以用于计算给定数据集的香农熵:

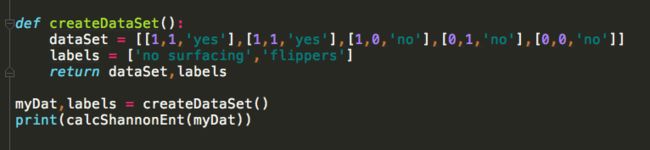
香农熵主要是作为一个指标用于指导划分数据集,以下函数用于按照特定特征划分数据集

信息增益(ID3)
基于香农熵的概念和以上两个函数,我们可以再写一个函数用于计算如何给一个数据集进行划分,通过对数据集的每一个特征属性进行划分,然后计算划分后的所有数据集熵值与其概率的乘积之和,并与数据集划分前原始数据集的熵值相比较,计算降低的熵值。这部分降低的熵值就被成为‘信息增益’(用ID3表示),通过比较各特征属性的信息增益后,可以推算出按照哪种特征属性分类信息增益最大,就用这种方式进行分类。

这种分类方法看似很厉害,但是仍存在一个BUG:例如,你给每个值标一个ID,然后将ID作为一个特征项划分数据集后得出的熵值是零,而对应的信息增益则最大,这显然是不对的,为了规避在个问题,我们引入了另一个概率,信息增益率(C4.5)。
信息增益率(C4.5)
信息增益率 = 信息增益值/数据集本身的熵值
例如:接着上面的例子,数据集dataset = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],][0,1,'no'],[0,1,'no']]的熵值为
-0.6*log(0.6,2)-0.4*log(0.4,2) = 0.9709505944546687
然后给数据集每个实例添加一个特征属性ID,dataset = [[1,1,1,'yes'],[2,1,1,'yes'],[3,1,0,'no'],][4,0,1,'no'],[5,0,1,'no']],如果按照ID划分数据集得出的熵值增益是0.97095059445466870 - 0 = 0.9709505944546687
但是数据集本身按照ID作为标签计算的熵值则是-1/5log(1/5,2)*5 = log(5,2),所以信息增益率为
0.9709505944546687/log(5,2) = 0.41816566007905165
决策树
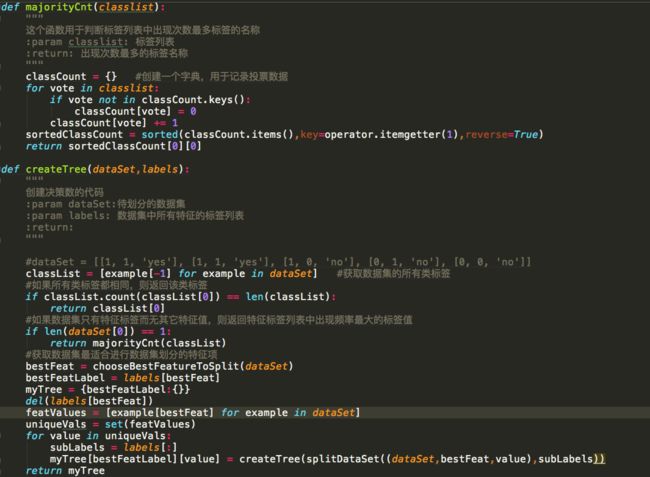
决策树的基本逻辑就是基于以上算法的:得到原始数据集后,基于各种特征属性的信息增益(ID3)的判断下一步通过哪个属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。经过一次划分之后,数据将被向下传递到树分支的下一个节点,这个节点上,我们可以再次划分数据。我们利用这个逻辑,递归的处理数据集,直到程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。
连续值的处理逻辑
我们在前面处理的数值都是离散了,但是如果我们需要处理连续值又该怎样处理呢
随机森林
好了,在引入决策树算法以后,我们可以扩展出一个新概念,叫“随机森林”