一.Kafka发送消息的整体流程:
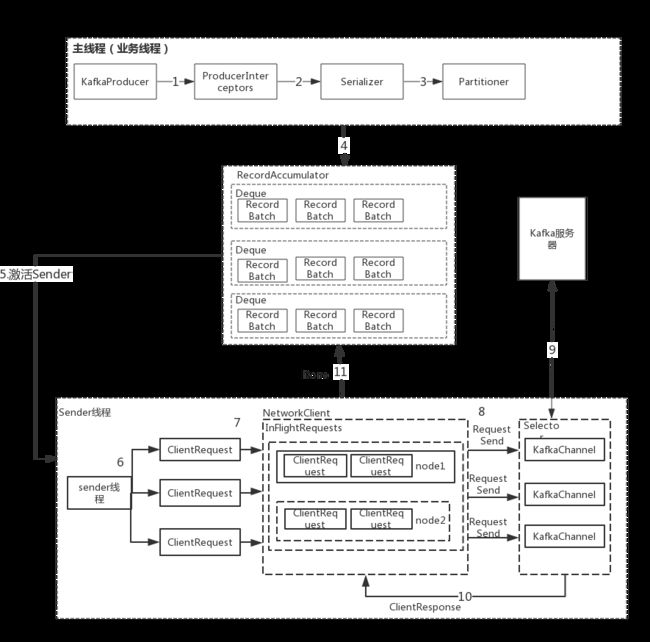
步骤:
1.ProducerInterceptors对消息进行拦截。
2.Serializer对消息的key和value进行序列化。
3.Partitioner为消息选择合适的Partition。
4.RecordAccumulator收集消息,实现批量发送。
5.Sender从RecordAccumulator获取消息。
6.构造ClientRequest。
7.将ClientRequest交给NetworkClient,准备发送。
8.NetworkClient将请求送入KafkaChannel的缓存。
9.执行网络I/O,发送请求。
10.收到响应,调用ClientRequest的回调函数。
11.调用RecordBatch的回调函数,最终调用每个消息上注册的回调函数。
消息发送过程中,涉及两个线程协同工作。主线程首先将业务数据封装成ProducerRecord对象,之后调用send()方法将消息放入RecordAccumulator(消息收集器,也是主线程和sender线程共享的缓冲区)中暂存。Sender线程负责将消息信息构成请求,最终执行网络I/O的线程,它从RecordAccumulator中取出消息并批量发送出去。KafkaProducer是线程安全的,多个线程可以共享使用一个KafkaProducer对象。
KafkaProducer实现了Producer接口,在Producer接口中定义了KafkaProducer对外提供的API,分为四类方法:
- send()方法:发送消息,实际上是将消息放入RecordAccumulator暂存,等待发送。
- flush()方法:刷新操作,等待RecordAccumulator所有信息发送完,在刷新完成前会阻塞调用线程。
- partitionFor()方法:在KafkaProducer中维护了一个Metadata对象用于存储Kafka集群的元数据,Metadata中的元素会定期更新。partitionFor()方法负责从Metadata中获取指定Topic分区信息。
- close()方法:关闭Producer对象,主要操作是设置close标志,等待RecordAccumulator中的消息清空,关闭Sender线程。
二.KafkaProducer分析:
KafkaProducer重要的字段:

- clientId:这个生产者的唯一标识。
- partitioner: 分区选择器,根据一定的策略,将消息路由到合适的分区。
- maxRequestSize:消息的最大长度,这个长度包括消息头,序列化后的key和序列化后的value的长度。
- totalMemorySize:发送单个消息的缓冲区大小。
- accumulator:RecordAccumulator,用于收集并缓存消息,等待Sender线程发送。
- sender: 发送消息的Sender任务,实现了Runnable接口,在ioThread线程中运行。
- ioThread:执行Sender任务发送消息的线程,称为“Sender线程”。
- compressionType:压缩算法,可选项有none,gzip,snappy,lz4。这是针对RecordAccumulator中多条消息进行的压缩,所以消息越多,压缩效果越好。
- keySerializer: key的序列化器。
- valueSerializer: value的序列化器。
- metadata :整个Kafka集群的元数据。
- maxBlockTimeMs: 等待更新Kafka集群元数据的最长时长。
- requestTimeoutMs: 消息的超时时间,也就是从消息发送到收到ACK响应的最长时长。
- interceptor: ProducerInterceptor集合,ProducerInterceptor可以在消息发送前堆其进行拦截或修改;也可以先于用户的Callback,对ACK响应进行预处理。
- producerConfig:配置对象,使用反射初始化KafkaProducer配置的相对对象。
KafkaProducer的构造函数:
KafkaProducer端配置加载
自定义属性
自定义属性,比如ProducerConfig.BOOTSTRAP_SERVERS_CONFIG:A list of host/port pairs。表示用于初始化连接Kafka cluster的ip:port,用来获得全部Kafka cluster的列表。所以不用全部写,但是最好多写几个,为了防止一个挂了。
props.put(ProducerConfig.CLIENT_ID_CONFIG, "testConstructorClose");
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG, MockMetricsReporter.class.getName());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.IntegerSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer=new KafkaProducer<>(props);
加载默认属性和自定义属性
实例化类ProducerConfig,类ProducerConfig里有个静态属性ConfigDef CONFIG = new ConfigDef()。
/**
* A producer is instantiated by providing a set of key-value pairs as configuration. Valid configuration strings
* are documented here.
* @param properties The producer configs
*/
public KafkaProducer(Properties properties) {
this(new ProducerConfig(properties), null, null);
}
加载默认属性:
static {
CONFIG = new ConfigDef().define(BOOTSTRAP_SERVERS_CONFIG, Type.LIST, Importance.HIGH, CommonClientConfigs.BOOSTRAP_SERVERS_DOC)
.define(BUFFER_MEMORY_CONFIG, Type.LONG, 32 * 1024 * 1024L, atLeast(0L), Importance.HIGH, BUFFER_MEMORY_DOC)
......
最后把自定义的属性value覆盖默认的属性value:
public Map parse(Map props) {
// Check all configurations are defined
List undefinedConfigKeys = undefinedDependentConfigs();
if (!undefinedConfigKeys.isEmpty()) {
String joined = Utils.join(undefinedConfigKeys, ",");
throw new ConfigException("Some configurations in are referred in the dependents, but not defined: " + joined);
}
// parse all known keys
Map values = new HashMap<>();
for (ConfigKey key : configKeys.values()) {
Object value;
// props map contains setting - assign ConfigKey value
if (props.containsKey(key.name)) {
value = parseType(key.name, props.get(key.name), key.type);
// props map doesn't contain setting, the key is required because no default value specified - its an error
} else if (key.defaultValue == NO_DEFAULT_VALUE) {
throw new ConfigException("Missing required configuration \"" + key.name + "\" which has no default value.");
} else {
// otherwise assign setting its default value
value = key.defaultValue;
}
if (key.validator != null) {
key.validator.ensureValid(key.name, value);
}
values.put(key.name, value);
}
return values;
}
KafkaProducer的构造函数开始
KafkaProducer的构造函数会初始化上面的字段,几个重要的字段介绍下。
private KafkaProducer(ProducerConfig config, Serializer keySerializer, Serializer valueSerializer) {
try {
log.trace("Starting the Kafka producer");
......
//通过反射机制实例化配置的partitioner类。
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
//创建并更新kafka集群的元数据
this.metadata = new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG));
List addresses = ClientUtils.parseAndValidateAddresses(config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
this.metadata.update(Cluster.bootstrap(addresses), time.milliseconds());
//创建RecordAccumulator
this.accumulator = new RecordAccumulator(config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.totalMemorySize,
this.compressionType,
config.getLong(ProducerConfig.LINGER_MS_CONFIG),
retryBackoffMs,
metrics,
time);
......
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config.values());
//创建NetworkClient,这个是KafkaProducer网络I/O的核心,后面会讲到。
NetworkClient client = new NetworkClient(
new Selector(config.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), this.metrics, time, "producer", channelBuilder),
this.metadata,
clientId,
config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION),
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
config.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
this.requestTimeoutMs, time);
this.sender = new Sender(client,
this.metadata,
this.accumulator,
config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION) == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
(short) parseAcks(config.getString(ProducerConfig.ACKS_CONFIG)),
config.getInt(ProducerConfig.RETRIES_CONFIG),
this.metrics,
new SystemTime(),
clientId,
this.requestTimeoutMs);
String ioThreadName = "kafka-producer-network-thread" + (clientId.length() > 0 ? " | " + clientId : "");
//启动Sender对应的线程
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
//通过反射机制实例化配置的keySerializer类,valueSerializer类
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.keySerializer.configure(config.originals(), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.valueSerializer.configure(config.originals(), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
// load interceptors and make sure they get clientId
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
List> interceptorList = (List) (new ProducerConfig(userProvidedConfigs)).getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptor.class);
this.interceptors = interceptorList.isEmpty() ? null : new ProducerInterceptors<>(interceptorList);
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId);
log.debug("Kafka producer started");
} catch (Throwable t) {
// call close methods if internal objects are already constructed
// this is to prevent resource leak. see KAFKA-2121
close(0, TimeUnit.MILLISECONDS, true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka producer", t);
}
}
KafkaProducer的send()方法:
KafkaProducer的send()方法的调用流程:
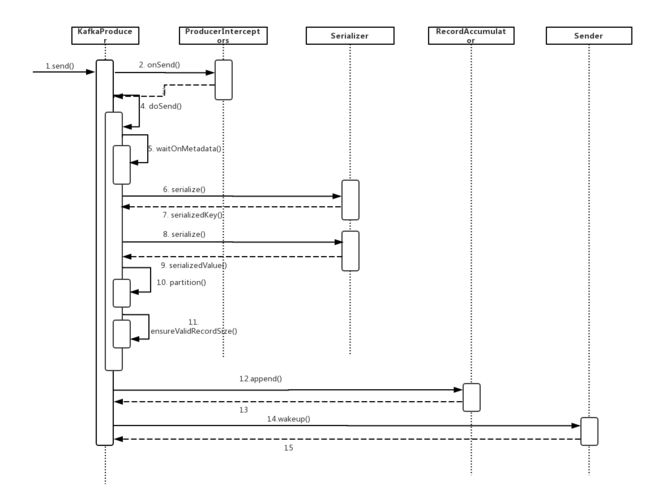
- 调用ProducerInterceptors.onSend()方法,通过ProducerInterceptor对消息进行拦截或修改。
- 调用waitOnMetadata()方法获取Kafka集群的信息,底层会唤醒Send线程更新Metadata中保存的Kafka集群元数据。
- 调用Serializer.serialize()方法序列化消息的key和value。
- 调用partition()为消息选择合适的分区。
- 调用RecordAccumulator.append()方法,将消息追加到RecordAccumulator中。
- 唤醒Sender线程,由Sender线程将RecordAccumulator中缓存的消息发出去。
三.ProducerInterceptors&ProducerInterceptor
ProducerInterceptors是一个ProducerInterceptor集合,方法onSend(),onAcknowledgement(),onSendError(),实际上是循环调用其封装的ProducerInterceptor集合的对应方法。
ProducerInterceptor对象可以在消息发送之前对其进行拦截或修改,也可以先于用户的Callback,对ACK响应进行预处理。可以把它想象成java web的filter。创建ProducerInterceptor类,只要实现ProducerInterceptor接口,创建其对象并添加到ProducerInterceptors中即可。
四.Kafka集群元数据
Leader副本的动态变化
在生产者的角度来看,分区的数量以及Leader副本的分布是动态变化的。比如:
- 在运行过程中,Leader副本随时都有可能出现故障而导致Leader副本的重新选举,新的Leader副本会在其他Broker上继续对外提供服务。
- 当需要提高某Topic的并行处理消息的能力时,我们可以通过增加其分区的数量来实现。
KafkaProducer发送消息时的路由方法:
KafkaProducer要将此消息追加到指定Topic的某个分区的Leader副本中,首先需要知道Topic的分区数量,经过路由后确定目标分区。然后KafkaProducer需要知道目标分区的Leader副本所在服务器的地址,端口等信息,才能建立连接,将消息发送到Kafka中。
KafkaProducer元数据:
在KafkaProducer维护了Kafka集群的元数据:包括某个topic中有哪几个分区,每个分区的Leader副本分配哪个节点上,Follower副本分配在哪些节点上,哪些副本在ISR集合中以及这些节点的网络地址,端口。
在KafkaProducer中,使用Node,TopicPartition,PartitionInfo这三个类封装了Kafka集群的相关数据。

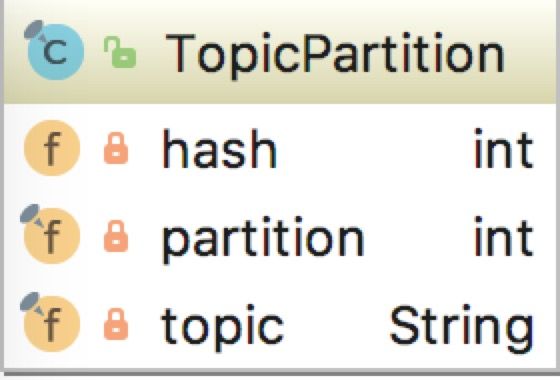

- Node表示集群中的一个节点。Node记录了这个节点的host,ip,port等信息。
- TopicPartition表示某Topic的一个分区,其中的topic字段是Topic的名称,partition字段是此分区在Topic中的分区编号(ID)。
- PartitionInfo表示一个分区的详细信息。其中topic字段和partition字段的含义与TopicPartition中的相同,除此之外,leader字段保持了Leader副本所在节点的id,replica字段记录了全部副本所在的节点信息,inSyncReplicas字段记录了ISR集合中所有副本所在的节点信息。
通过这三个类的组合,我们可以完整表示出KafkaProducer需要的集群元数据。这些元数据保存在了Cluster这个类中,并按照不同的映射方式进行存放,方便查询。Cluster类的核心字段如下:
 image.png
image.png - nodes: Kafka集群中节点信息列表。
- nodesById: BrokerId与Node节点之间的对于关系,方便按照BrokerId进行查询。
- partitionsByTopicPartition: 记录了TopicPartition与PartitionInfo的映射关系。
- partitionsByTopic: 记录了Topic名称和PartitionInfo的映射关系,可以按照Topic的名称查询全部的分区详细信息。
- availablePartitionsByTopic: 记录了Topic名称和PartitionInfo的映射关系,这里的List
中存放的分区必须是有Leader副本的Partition,而partitionsByTopic中记录的分区则不一定有Leader副本,因为有些中间状态,如Leader副本宕机而触发的选举过程中,分区不一定有Leader副本。 - partitionByNode:记录了Node与PartitionInfo的映射关系,可以按照节点id查询其分布的全部分区的详细信息。
Cluster的方法比较简单,主要是针对以上的操作,方便集群元数据的查询,例如partitionsForTopic方法:
/**
* Get the list of partitions for this topic
* @param topic The topic name
* @return A list of partitions
*/
public List partitionsForTopic(String topic) {
return this.partitionsByTopic.get(topic);
}
注意:Node,TopicPartition,PartitionInfo,Cluster的所有字段都是private final修饰的,且只提供了查询方法,并未提供任何修改方法,这就保证了这四个类的对象都是不可变性对象,它们就是线程安全的对象。
Metadata中封装了Cluster对象,并保存Cluster数据的最后更新时间,版本号(version),是否需要更新等待信息。
MetaData核心字段:
Metadata中封装了Cluster对象,并保存Cluster数据的最后更新时间,版本号(version),是否需要更新等待信息。

- topics:记录了当前已知的所有topic,在cluster字段中记录了Topic最新的元数据。
- version:表示Kafka集群元数据的版本号。Kafka集群元数据每更新成功一次,version的值加1。通过新旧版本号的比较,判断集群元数据是否更新完成。
- metadataExpireMs: 每隔多久,更新一次。默认是300*1000,也就是5分钟。
- refreshBackOffMs:两次发出更新Cluster保存的元数据信息的最小时间差,默认为100ms。这是为了防止更新操作过于频繁而造成网络阻塞和增加服务端的压力。在Kafka中与重试操作有关的操作中,都有“退避(backoff)时间”设计的身影。
- lastRefreshMs:记录上一次更新元数据的时间戳(也包含更新失败的情况)。
- lastSuccessfulRefreshMs: 上一次成功更新的时间戳。如果每次都成功,则lastSuccessfulRefreshMs,lastRefreshMs相等。否则,lastRefreshMs>lastSuccessfulRefreshMs。
- cluster:记录Kafka集群的元数据。
- needUpdate:标识是否强制更新Cluster,这是触发Sender线程更新集群元数据的条件之一。
- listeners: 监听Metadata更新的监听器集合。自定义Metadata监听实现Metadata.Listener.onMetadataUpdate()方法即可,在更新Metadata中的cluster字段之前,会通知listener集合中全部Listener对象。
- needMetadataForAllTopics:是否需要更新全部Topic的元数据,一般情况下,KafkaProducer只维护它用到的Topic元素,是集群中全部Topic的子集。
MetaData的方法比较简单,主要是操作上面的几个字段,主要介绍主线程用的requestUpdate()和awaitUpdate()。requestUpdate()方法将needUpdate字段修改为true,这样当Sender线程运行时会更新Metadata记录的集群元数据,然后返回version字段的值。awaitUpdate()是通过version来判断元数据是否更新完成,更新未完成则阻塞等待:
/**
* Request an update of the current cluster metadata info, return the current version before the update
*/
public synchronized int requestUpdate() {
//needUpdate设置为true,表示需要强制更新Cluster
this.needUpdate = true;
//返回当前Kafka集群元数据的版本号
return this.version;
}
/**
* Wait for metadata update until the current version is larger than the last version we know of
*/
public synchronized void awaitUpdate(final int lastVersion, final long maxWaitMs) throws InterruptedException {
if (maxWaitMs < 0) {
throw new IllegalArgumentException("Max time to wait for metadata updates should not be < 0 milli seconds");
}
long begin = System.currentTimeMillis();
long remainingWaitMs = maxWaitMs;
while (this.version <= lastVersion) {
if (remainingWaitMs != 0)
wait(remainingWaitMs);
long elapsed = System.currentTimeMillis() - begin;
if (elapsed >= maxWaitMs)
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
remainingWaitMs = maxWaitMs - elapsed;
}
}
解释:
maxWaitMs:更新metadata版本需要的最长时间。
remainingWaitMs:wait需要等待的时间。
elapsed = System.currentTimeMillis() - begin:本次循环更新消耗的时间。
Metadata中的字段可以由主线程读,Sender线程更新,因此它必须是线程安全的,所以上面的方法都使用synchronized同步。Sender线程的内存会在后面介绍。
KafkaProducer.waitOnMetadata()方法分析:
这个方法触发了Kafka元数据的更新,并阻塞主线程等待更新完毕。步骤:
/**
* Wait for cluster metadata including partitions for the given topic to be available.
* @param topic The topic we want metadata for
* @param maxWaitMs The maximum time in ms for waiting on the metadata
* @return The amount of time we waited in ms
*/
private long waitOnMetadata(String topic, long maxWaitMs) throws InterruptedException {
// 查看Metadata中是否包含指定Topic的元数据,若不包含,则将Topic添加到topics集合中。
if (!this.metadata.containsTopic(topic))
this.metadata.add(topic);
//成功获取分区的详细信息
if (metadata.fetch().partitionsForTopic(topic) != null)
return 0;
long begin = time.milliseconds();
long remainingWaitMs = maxWaitMs;
while (metadata.fetch().partitionsForTopic(topic) == null) {
log.trace("Requesting metadata update for topic {}.", topic);
//设置needupdate,获取当前元数据版本号
int version = metadata.requestUpdate();
sender.wakeup();//唤醒Sender线程
//阻塞等待元数据更新完毕
metadata.awaitUpdate(version, remainingWaitMs);
long elapsed = time.milliseconds() - begin;
if (elapsed >= maxWaitMs)//超时检验
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
//权限检验
if (metadata.fetch().unauthorizedTopics().contains(topic))
throw new TopicAuthorizationException(topic);
remainingWaitMs = maxWaitMs - elapsed;
}
return time.milliseconds() - begin;
}
1.查看Metadata中是否包含指定Topic的元数据,若不包含,则将Topic添加到topics集合中,下次更新时会从服务端获得指定Topic元数据。
2.尝试获取Topic中分区的详细信息,失败后会调用requestUpdate()方法设置Metadata.needUpdate字段,并得到当前元数据版本号。
3.唤醒Sender线程,由Sender线程更新Metadata中保存的Kafka集群元数据。
4.主线程调用awaitUpdate()方法,等待Sender线程完成更新。
5.从Metadata中获取指定Topic分区的详细信息(即PartitionInfo集合)。若失败,回到步骤2继续尝试,若等待时间超时,则抛出异常。
主线程唤醒的Sender线程会调用update()去服务端拉取Cluster信息:
/**
* Update the cluster metadata
*/
public synchronized void update(Cluster cluster, long now) {
this.needUpdate = false;
this.lastRefreshMs = now;
this.lastSuccessfulRefreshMs = now;
this.version += 1;
for (Listener listener: listeners)
listener.onMetadataUpdate(cluster);
// Do this after notifying listeners as subscribed topics' list can be changed by listeners
this.cluster = this.needMetadataForAllTopics ? getClusterForCurrentTopics(cluster) : cluster;
notifyAll();
log.debug("Updated cluster metadata version {} to {}", this.version, this.cluster);
}
五.Serializer&Deserializer:

Kafka已经提供了java基本类型的Serializer实现和Deserializer实现,我们也可以自定义Serializer实现和Deserializer实现,只要实现Serializer接口和Deserializer接口。介绍下Serializer,Deserializer是逆操作。
configure()方法是序列化之前的配置,如StringSerializer.configure()方法内会选择合适的的编码类型(encoding),默认是UTF-8; serializer()方法是真正进行序列化的地方,将传入的java对象序列化成byte[]。
六.Partitioner:
Partitioner是为消息选择分区的分区器。
业务逻辑可以控制消息路由到哪个分区,也可以不用关心分区的选择。
先调用KafkaProducer.partition()方法:
/**
* computes partition for given record.
* if the record has partition returns the value otherwise
* calls configured partitioner class to compute the partition.
*/
private int partition(ProducerRecord record, byte[] serializedKey , byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
if (partition != null) {
List partitions = cluster.partitionsForTopic(record.topic());
int lastPartition = partitions.size() - 1;
// they have given us a partition, use it
if (partition < 0 || partition > lastPartition) {
throw new IllegalArgumentException(String.format("Invalid partition given with record: %d is not in the range [0...%d].", partition, lastPartition));
}
return partition;
}
return this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue,
cluster);
}
如果业务代码没有定义消息路由到哪个partition,那么调用Partitioner接口的默认实现DefaultPartitioner。
当创建KafkaProducer时传入的key/value配置项会保存到AbstractConfig的originals字段中。AbstractConfig的核心方法是getConfiguredInstance()方法,功能是通过反射的机制实例化originals字段中指定的类。
获取分区对象partitioner,通过反射加载默认配置。默认配置在ProducerConfig类的静态属性Config里:
.define(PARTITIONER_CLASS_CONFIG,
Type.CLASS,
DefaultPartitioner.class.getName(),
Importance.MEDIUM, PARTITIONER_CLASS_DOC)
反射获取对象:
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
设计Configurable接口的目的是统一反射后的初始化过程,对外提供统一的初始化接口。在AbstractConfig.getConfiguredInstance方法中通过发射构造出来的对象,都是通过无参构造函数构造的,需要初始化的字段个数和类型各种各样,Configurable接口的configure()方法封装了对象初始化过程且只有一个参数(originals字段),这样对外接口实现了统一。**这个设计注意积累。**
KafkaProducer.partition()方法负责在ProduceRecord中没有明确指定分区编号的时候,围棋选择合适的分区:如果消息没有key,会根据counter与Partition个数取模来确定分区编号,counter不断递增,确保消息不会都发到一个partition里;如果有key就对key进行hash。
private final AtomicInteger counter = new AtomicInteger(new Random().nextInt());
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = counter.getAndIncrement();
List
if (availablePartitions.size() > 0) {
int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return DefaultPartitioner.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
counter用不用int而用