hadoop安装
1 下载
地址http://hadoop.apache.org/releases.html

2 解压
tar -zxvf hadoop-2.6.5.tar.gz -C /opt/wsqt/core
mv hadoop-2.6.5/hadoop
3 修改HDFS配置文件
清空相关配置文件复制以下配置文件,或手动修改。
etc/hadoop/slaves
##此文件中hostname为所有的datanode数据节点,每个一行
hadoop003
hadoop004
hadoop005
etc/hadoop/core-site.xml
fs.defaultFS
hdfs://wsqt/
hadoop.tmp.dir
/opt/wsqt/data/namenode
ha.zookeeper.quorum
hadoop003:2181,hadoop004:2181,hadoop005:2181
io.file.buffer.size
131072
io.compression.codecs
org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec
fs.trash.interval
10080
Number of minutes between trash checkpoints.
If zero, the trash feature is disabled.
dfs.balance.bandwidthPerSec
104857600
Specifies themaximum bandwidth that each datanode can utilize for the balancing purpose interm of the number of bytes per second.
etc/hadoop/hdfs-site.xml
dfs.nameservices
wsqt
dfs.ha.namenodes.wsqt
nn1,nn2
dfs.namenode.rpc-address.wsqt.nn1
hadoop001:9000
dfs.namenode.http-address.wsqt.nn1
0.0.0.0:50070
dfs.namenode.rpc-address.wsqt.nn2
hadoop002:9000
dfs.namenode.http-address.wsqt.nn2
0.0.0.0:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/wsqt
dfs.journalnode.edits.dir
/opt/wsqt/data/journal
dfs.ha.automatic-failover.enabled.wsqt
true
dfs.client.failover.proxy.provider.wsqt
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.namenode.name.dir
/opt/wsqt/data/namenode/dfs/name
dfs.datanode.data.dir
/opt/wsqt/data/disk1/data
default:file://${hadoop.tmp.dir}/dfs/data. for example:/disk1/data,/disk2/data,/disk3/data
dfs.block.size
268435456
dfs.datanode.handler.count
20
dfs.namenode.handler.count
20
dfs.datanode.max.xcievers
131072
dfs.datanode.socket.write.timeout
0
dfs.socket.timeout
180000
dfs.replication
3
mapred.child.env
JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
etc/hadoop/hadoop-env.sh
export WSQT_HOME=/opt/wsqt
export JAVA_HOME=${WSQT_HOME}/core/java
export HADOOP_HOME=${WSQT_HOME}/core/hadoop
#配置文件目录
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
# The maximum amount of heap to use, in MB. Default is 1000.
#大型集群,或者集群扩容时需要适当增加这个参数,默认是1000MB.
#export HADOOP_HEAPSIZE=4096
#export HADOOP_NAMENODE_INIT_HEAPSIZE=1024
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
##namenode启动的java参数
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
##datanode启动的java参数
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_
SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
#集群过大的时候,某些错误可能比较慢,可以适当增加这个参数
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges.
# This **MUST** be uncommented to enable secure HDFS if using privileged ports
# to provide authentication of data transfer protocol. This **MUST NOT** be
# defined if SASL is configured for authentication of data transfer protocol
# using non-privileged ports.
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
# Where log files are stored. $HADOOP_HOME/logs by default.
export HADOOP_LOG_DIR=${WSQT_HOME}/logs/hadoop/$USER
# Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
# Where log files are stored in the secure data environment.
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
###
# HDFS Mover specific parameters
###
# Specify the JVM options to be used when starting the HDFS Mover.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HADOOP_MOVER_OPTS=""
###
# Advanced Users Only!
###
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
# The directory where pid files are stored. /tmp by default.
# /tmp目录里由于会系统设置默认清楚过期文件,所以pid文件时间一长就没了,在关闭集群的时候就会报错显示没有服务需要关闭。虽然服务仍然存在。
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${WSQT_HOME}/tmp
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native
修改YARN配置文件
etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop001:10020
mapreduce.jobhistory.webapp.address
hadoop001:19888
yarn.app.mapreduce.am.staging-dir
/opt/wsqt/data/yarn/staging
mapred.child.java.opts
-Xmx4g
io.sort.mb
512
io.sort.factor
20
mapred.job.reuse.jvm.num.tasks
-1
mapreduce.reduce.shuffle.parallelcopies
20
mapreduce.output.fileoutputformat.compress
true
mapreduce.output.fileoutputformat.compress.codec
org.apache.hadoop.io.compress.SnappyCodec
mapreduce.map.output.compress
true
mapreduce.map.output.compress.codec
org.apache.hadoop.io.compress.SnappyCodec
mapreduce.output.fileoutputformat.compress.type
BLOCK
mapreduce.cluster.local.dir
/opt/wsqt/data/disk1/tmp/mapred/local
The local directory where MapReduce stores intermediate data files. May be a comma-separated list of directories on different devices in order to spread disk i/o. Directories that do not exist are ignored. file://${hadoop.tmp.dir}/mapred/local
mapreduce.map.speculative
false
mapreduce.reduce.speculative
false
etc/hadoop/mapred-env.sh
##控制jobhistoryserver的jvm内存占用(MB)
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
##mapred日志
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
#export HADOOP_JOB_HISTORYSERVER_OPTS=
#export HADOOP_MAPRED_LOG_DIR="" # Where log files are stored. $HADOOP_MAPRED_HOME/logs by default.
#export HADOOP_JHS_LOGGER=INFO,RFA # Hadoop JobSummary logger.
#export HADOOP_MAPRED_PID_DIR= # The pid files are stored. /tmp by default.
#export HADOOP_MAPRED_IDENT_STRING= #A string representing this instance of hadoop. $USER by default
#export HADOOP_MAPRED_NICENESS= #The scheduling priority for daemons. Defaults to 0.
etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.local-dirs
/opt/wsqt/data/disk1/tmp/yarn/local
default:${hadoop.tmp.dir}/nm-local-dir.List of directories to store localized files in. An application's localized file directory will be found in: ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}. Individual containers' work directories, called container_${contid}, will be subdirectories of this.May be a comma-separated list of directories on different devices in order to spread disk i/o
yarn.nodemanager.log-dirs
/opt/wsqt/logs/yarn/userlogs
yarn.log-aggregation-enable
true
Where to aggregate logs
yarn.nodemanager.remote-app-log-dir
hdfs://wsqt/var/log/hadoop-yarn/apps
yarn.log-aggregation.retain-seconds
2592000
false
yarn.log-aggregation.retain-check-interval-seconds
3600
false
yarn.resourcemanager.connect.retry-interval.ms
2000
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.ha.automatic-failover.embedded
true
yarn.resourcemanager.cluster-id
wsqt
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.ha.id
rm1
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.resourcemanager.recovery.enabled
true
Enable RM to recover state after starting. If true, then yarn.resourcemanager.store.class must be specified.
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.zk.state-store.address
hadoop003:2181,hadoop004:2181, hadoop005:2181
yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms
5000
yarn.resourcemanager.address.rm1
hadoop001:23140
yarn.resourcemanager.scheduler.address.rm1
hadoop001:23130
yarn.resourcemanager.webapp.https.address.rm1
hadoop001:23189
yarn.resourcemanager.webapp.address.rm1
hadoop001:23188
yarn.resourcemanager.resource-tracker.address.rm1
hadoop001:23125
yarn.resourcemanager.admin.address.rm1
hadoop001:23141
yarn.resourcemanager.address.rm2
hadoop002:23140
yarn.resourcemanager.scheduler.address.rm2
hadoop002:23130
yarn.resourcemanager.webapp.https.address.rm2
hadoop002:23189
yarn.resourcemanager.webapp.address.rm2
hadoop002:23188
yarn.resourcemanager.resource-tracker.address.rm2
hadoop002:23125
yarn.resourcemanager.admin.address.rm2
hadoop002:23141
Address where the localizer IPC is.
yarn.nodemanager.localizer.address
0.0.0.0:23344
NM Webapp address.
yarn.nodemanager.webapp.address
0.0.0.0:23999
mapreduce.shuffle.port
23080
yarn.resourcemanager.zk-address
hadoop003:2181,hadoop004:2181,hadoop005:2181
yarn.nodemanager.resource.memory-mb
122880
yarn.scheduler.minimum-allocation-mb
4096
yarn.nodemanager.resource.cpu-vcores
24
number of all the cpu cores
yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms
5000
false
etc/hadoop/yarn-env.sh
export WSQT_HOME=/opt/wsqt
# User for YARN daemons
export HADOOP_YARN_USER=${HADOOP_YARN_USER:-yarn}
# resolve links - $0 may be a softlink
export YARN_CONF_DIR="${YARN_CONF_DIR:-$HADOOP_YARN_HOME/conf}"
export JAVA_HOME=${WSQT_HOME}/core/java
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi
if [ "$JAVA_HOME" = "" ]; then
echo "Error: JAVA_HOME is not set."
exit 1
fi
JAVA=$JAVA_HOME/bin/java
JAVA_HEAP_MAX=-Xmx1000m
# For setting YARN specific HEAP sizes please use this
# Parameter and set appropriately
# YARN_HEAPSIZE=1000
# check envvars which might override default args
if [ "$YARN_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_HEAPSIZE""m"
fi
# Resource Manager specific parameters
# Specify the max Heapsize for the ResourceManager using a numerical value
# in the scale of MB. For example, to specify an jvm option of -Xmx1000m, set
# the value to 1000.
# This value will be overridden by an Xmx setting specified in either YARN_OPTS
# and/or YARN_RESOURCEMANAGER_OPTS.
# If not specified, the default value will be picked from either YARN_HEAPMAX
# or JAVA_HEAP_MAX with YARN_HEAPMAX as the preferred option of the two.
#大型集群,或者集群扩容时需要适当增加这个参数,默认是1000MB.
#export YARN_RESOURCEMANAGER_HEAPSIZE=1000
#大型集群,或者集群扩容时需要适当增加这个参数,默认是1000MB.
#export YARN_NODEMANAGER_HEAPSIZE=1000
# so that filenames w/ spaces are handled correctly in loops below
IFS=
##控制yarn日志,包括resourcemanager和nodemanager,其余参数基本默认
export YARN_LOG_DIR=${WSQT_HOME}/logs/yarn
##控制yarn服务的pid文件位置
export YARN_PID_DIR=${WSQT_HOME}/tmp
# default log directory & file
if [ "$YARN_LOG_DIR" = "" ]; then
YARN_LOG_DIR="$HADOOP_YARN_HOME/logs"
fi
if [ "$YARN_LOGFILE" = "" ]; then
YARN_LOGFILE='yarn.log'
fi
# default policy file for service-level authorization
if [ "$YARN_POLICYFILE" = "" ]; then
YARN_POLICYFILE="hadoop-policy.xml"
fi
# restore ordinary wsqtaviour
unset IFS
YARN_OPTS="$YARN_OPTS -Dhadoop.log.dir=$YARN_LOG_DIR"
YARN_OPTS="$YARN_OPTS -Dyarn.log.dir=$YARN_LOG_DIR"
YARN_OPTS="$YARN_OPTS -Dhadoop.log.file=$YARN_LOGFILE"
YARN_OPTS="$YARN_OPTS -Dyarn.log.file=$YARN_LOGFILE"
YARN_OPTS="$YARN_OPTS -Dyarn.home.dir=$YARN_COMMON_HOME"
YARN_OPTS="$YARN_OPTS -Dyarn.id.str=$YARN_IDENT_STRING"
YARN_OPTS="$YARN_OPTS -Dhadoop.root.logger=${YARN_ROOT_LOGGER:-INFO,console}"
YARN_OPTS="$YARN_OPTS -Dyarn.root.logger=${YARN_ROOT_LOGGER:-INFO,console}"
if [ "x$JAVA_LIBRARY_PATH" != "x" ]; then
YARN_OPTS="$YARN_OPTS -Djava.library.path=$JAVA_LIBRARY_PATH"
fi
YARN_OPTS="$YARN_OPTS -Dyarn.policy.file=$YARN_POLICYFILE
分发到其他节点上
scp -r hadoop/ hadoop\@hadoop002:\$PWD
scp -r hadoop/ hadoop\@hadoop003:\$PWD
scp -r hadoop/ hadoop\@hadoop004:\$PWD
scp -r hadoop/ hadoop\@hadoop005:\$PWD
启动HDFS
格式化HDFS的Zookeeper存储目录
格式化操作的目的是在ZK集群中建立一个节点,用于保存集群中NameNode的状态数据
在hadoop003上执行(只需在一个zookeeper节点执行即可):hdfs zkfc -formatZK
验证:zkCli.sh 并执行 ls / 显示信息
再执行quit可推出交互
启动JournalNode集群
- 所有journalnode节点上分别执行:
/opt/wsqt/core/hadoop/sbin/hadoop-daemon.sh start journalnode
- 所有journalnode节点上执行jps检测是否存在服务
[hadoop@data1 ~]$ jps |grep JournalNode

格式化并启动第一个NameNode
- 任选一个 ,这里选择hadoop001,执行:
##格式化当前节点的namenode数据
hdfs namenode -format
##格式化journalnode的数据,这个是ha需要做的
hdfs namenode -initializeSharedEdits
##启动当前节点的namenode服务
hadoop-daemon.sh start namenode
- 在hadoop001执行jps验证namenode服务是否存在
[hadoop@name2 ~]$ jps |grep NameNode
54542 NameNode
格式化并启动第二个NameNode
- 在hadoop002执行:
##启hadoop001已经格式化过,然后同步至hadoop002
hdfs namenode -bootstrapStandby
##启动当前节点的namenode服务
hadoop-daemon.sh start namenode
- 在hadoop002执行jps验证namenode服务是否存在
[hadoop@name2 ~]$ jps |grep NameNode
54542 NameNode
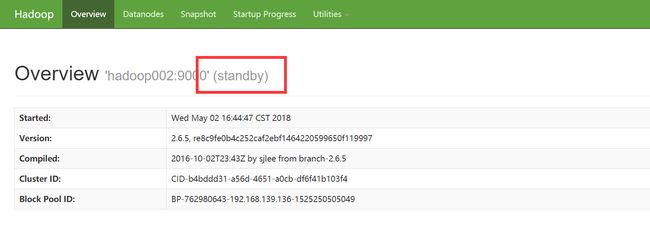
此时登陆http://hadoop001:50070与http://haoop001:50070皆显示standby状态
这里如果PC连接服务器使用浏览器需要输入IP_ADDRESS:50070来进行访问。

启动所有DataNode
- 在hadoop001执行:
##一次性启动全部DataNode节点
hadoop-daemons.sh start datanode

##或者在每个datanode上执行
hadoop-daemon.sh start datanode
- 在所有datanode节点上执行jps验证是否存在datanode服务
[hadoop@hadoop003 ~]$ jps |grep -i datanode
8439 DataNode
启动ZooKeeperFailoverController
- 所有namenode节点分别执行:
hadoop-daemon.sh start zkfc
- 验证:zkCli.sh 并执行 ls / 再执行quit可推出交互
[hadoop@hadoop001 ~]$ zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, zookeeper]
##这两个服务第一个是供hdfs的ha可用,第二个是zookeeper自己服务。
[zk: localhost:2181(CONNECTED) 8] ls /hadoop-ha
[wsqt]
##这个这hdfs的逻辑名称有参数dfs.nameservices设置
[zk: localhost:2181(CONNECTED) 9] ls /hadoop-ha/wsqt
[ActiveBreadCrumb, ActiveStandbyElectorLock]
登陆namenode服务器web端查看服务器状态
此时登陆http://hadoop001:50070与http://haoop002:50070
其中一个为active另一个为standby状态。
这里如果PC连接服务器使用浏览器需要输入IP_ADDRESS:50070来进行访问。


启动YARN
启动hdfs后,创建必要目录
创建hdfs下的history目录
hadoop fs -mkdir -p /user/history
hadoop fs -chmod -R 777 /user/history
hadoop fs -chown hadoop:hadoop /user/history
创建hdfs下的log目录
hadoop fs -mkdir -p /var/log/hadoop-yarn
hadoop fs -chown hadoop:hadoop /var/log/hadoop-yarn
创建hdfs下的/tmp
##如果不创建/tmp按照指定的权限,那么WSQT的其他组件将会有问题。尤其是,如果不创建的话,其他进程会以严格的权限自动创建这个目录,这样就会影响到其他程序适用。
hadoop fs -mkdir /tmp
hadoop fs -chmod -R 777 /tmp
在hadoop001上执行start-yarn.sh:
##此脚本将会启动hadoop001上的resourcemanager及所有的nodemanager节点
/opt/wsqt/core/hadoop/sbin/start-yarn.sh
##关于单独启动单个resourcemanager和nodemanager的命令如下
/opt/wsqt/core/hadoop/sbin/yarn-daemon.sh start resourcemanager
/opt/wsqt/core/hadoop/sbin/yarn-daemon.sh start nodemanager
在hadoop002上启动resourcemanager:
/opt/wsqt/core/hadoop/sbin/yarn-daemon.sh start resourcemanager
在hadoop001上启动jobhistory server
##启动jobhistoryserver主要作用是记录yarn执行任务之后的日志。需要在/opt/wsqt/core/hadoop/etc/hadoop/mapred-site.xml参数文件中设置参数mapreduce.jobhistory.address和mapreduce.jobhistory.webapp.address
目前我们选择hadoop001作为historyserver。
/opt/wsqt/core/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
登陆resourcemanager服务器web端查看服务器状态
此时登陆http://hadoop001:23188与http://haoop002:23188
其中一个为active另一个为standby状态。活跃节点可以正常访问,备用节点会自动跳转至活跃节点的web地址。
http://resourcemanager_ipaddress:23188
这里如果PC连接服务器使用浏览器需要输入IP_ADDRESS:23188来进行访问。
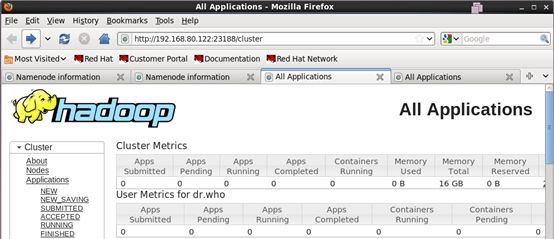
Active节点可访问正常。如下图:
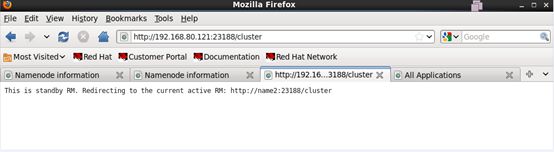
Standby节点web自动跳转至Active几点。如下图:
登jobhistory服务器web端查看job状态
我们通过参数设置了hadoop001为historyserver。
此时登陆http://hadoop001:19888查看web界面。可通过日志查看已执行完的job运行状况。
这里如果PC连接服务器使用浏览器需要输入IP_ADDRESS:19888来进行访问。
/
部署为三篇:
- 软件版本、系统环境、jdk、scala、zookeeper
https://www.jianshu.com/p/8a1f1b40073f - hadoop安装
https://www.jianshu.com/p/c88c208ba68c - Kafka Spark Flume安装
https://www.jianshu.com/p/ea8c2a4e0bf8