老司机教你看妹子——你的第一个知乎爬虫(1)

序
你看着知乎上一个个的爆照贴,想着怎样能把这些图片都保存下来呢。
“啊,老师啊,有没有什么可以批量保存小姐姐的功能啊”
少年你听说过爬虫么,会写python么
“emmmm,老师我python装好了,3.6”
孺子可教,
走着
把大象放进冰箱里
“老师我知道,第一步打开冰箱门,第二第把大象放进去,第三步关上冰箱门”,这个冷笑话你已经听了无数遍了,已经学会抢答了。
保存小姐姐也只需要三步:
1.打开网页
2.找到图片
3.保存
你默默的打开了搜索引擎:“如何用python打开网页”,然后一堆urllib之类的内容宛如天书,你又默默的关闭了网页。
“老师,有没有什么人类也能懂得方法来打来网页啊”
Requests: HTTP for Humans
“老师,他们还有中文版文档诶”
STEP 1
安装了库,读了一会文档后,你写出了第一步需要的代码:
Python 代码(python3):
import requests
url='https://www.zhihu.com/question/20399991'
r = requests.get(url)
text= r.text
你心怀期待的跑了一下:
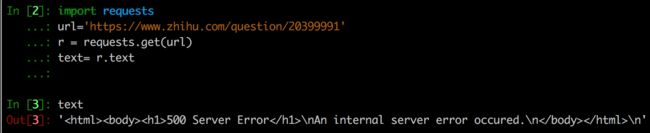
“老师,我把知乎的服务器搞挂了,你看500了!”
真的这样么,刚刚不好好的么?你换了浏览器结果发现浏览器里还好好的啊。
很明显,知乎服务器把你给骗了,而且它还很恶意的把你的连接挂了很久,刚刚那段代码会很久很久才跑出结果。
“难道说,它发现我是爬虫了?!”
对的
“怎么发现的呢?”
浏览器在发送请求的时候,通常会带上一个User-Agent,这个字符串里通常会包含操作系统信息和浏览器的一些信息。
所以网站才会知道你用的是Android还是iOS,Windows还是Mac,iPad还是iPhone,Chrome还是IE。
“哦,那我们现在的user-agent是啥呢”
默认的是"python-requests/1.2.0"
你打开了Chrome,找到了开发者工具,在Network一栏里,点开一条网络请求,从Request Headers里找到自己浏览器的UA
import requests
header = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
url='https://www.zhihu.com/question/20399991'
r = requests.get(url,headers=header)
text= r.text
这样看起来就是一个正常的Chrome浏览器在访问页面了
这下就拿到结果了。
STEP 2
你轻轻的在交互式窗口里输入了 print text,结果涌现出来的东西把你吓了一跳。
“这一坨HTML要怎么办啊,哪些是图片呢?我要去怎么解析他们啊”
“python how to parse html” 你在搜索栏里打下这行字
你熟练的点开了 Stack Overflow的那个连接,准备复制黏贴,高票回答让你去用一个Beautiful Soup之类的东西。
你默默的打开了煤气灶,准备煲汤...

“我只想下载个图片啊,老师能不能简单点,你说话的方式简单点...”
你当然可以用类似Beautiful Soup 之类的库去解析HTML的页面结构,但是我们需求没那么复杂(等汤煲好天都亮了),我们就简单的写个正则来匹配下吧。
一个典型的图片链接地址是这样的,https://pic1.zhimg.com/v2-dfad0e20695394c5fe79bfa5ec9dd170_b.jpg(贴心的知乎做了全站https),观察下发现,用https://开头以.jpg结尾,中间任意字符,同时,为了避免匹配到类似https://a/c.jpghttps://d/f.jpg这样的结果,我们需做最短匹配。
最后拿到就拿到了这样一个式子https://[^\s]*?\.jpg
“那只有jpg,还有png\jpeg\gif呢?”
多匹配几次喽...
jpg = re.compile(r'https://[^\s]*?\.jpg')
jpeg = re.compile(r'https://[^\s]*?\.jpeg')
gif = re.compile(r'https://[^\s]*?\.gif')
png = re.compile(r'https://[^\s]*?\.png')
imgs=[]
imgs+=jpg.findall(text)
imgs+=jpeg.findall(text)
imgs+=gif.findall(text)
imgs+=png.findall(text)
STEP 3
“下载图片我会!把图片链接写到txt文件里,然后用迅雷下载!”
放过迅雷吧,写一个花不了多久的。
def download(url):
req = requests.get(url)
if req.status_code == requests.codes.ok:
name = url.split('/')[-1]
f = open("./"+name,'wb')
f.write(req.content)
f.close()
return True
else:
return False
“然后是一个for循环,挨个下载,然后还能记录下哪些连接出错了”,你已经轻车熟路了。
errors = []
for img_url in imgs:
if download(img_url):
print("download :"+img_url)
else:
errors.append(img_url)
print("ERROR URLS:")
print(errors)
让我们运行一下,有图片了!
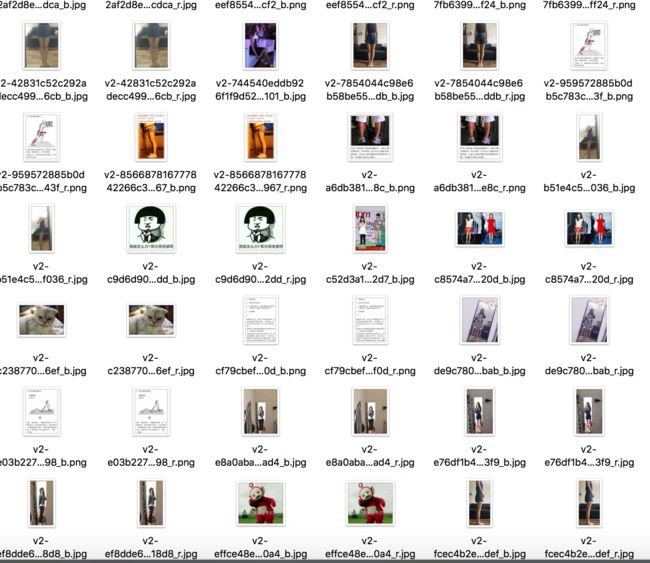
以及一坨错误的URL:
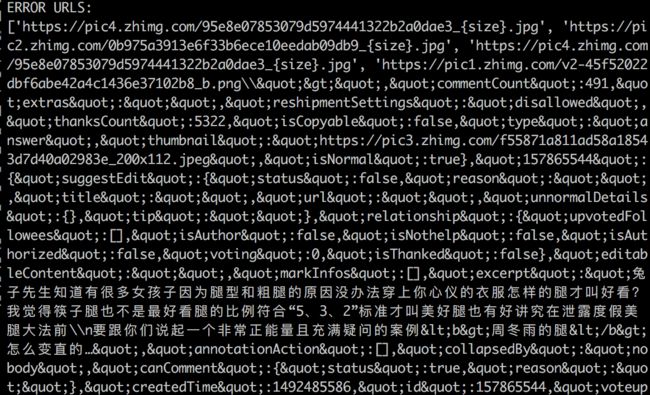
STEP 5 检查
“为什么有两份呢,还有些莫名其妙的小图片。”
你把这些图快速的撸了一遍,啊不,浏览了一遍,发现重复的图片基本以_r和_b结尾,而_r是原图,而以_l,_xs,_is,结尾的都是头像,这些没啥好看的。
“老师我发现了,错误的url除了https://pic4.zhimg.com/***_{size}.jpg之类以外,还有带转义符的,转义符导致我们的正则匹配出了问题,不是一个合法的url.”
“还有啊,这个图是不是少了点,这个问题可是有一个有700个回答呢”
***_{size}.jpg和一些转义符都是因为这些内容本来是要经过JS在浏览器渲染的,图少的原因则是因为,答案的加载是有分页的,网页上拉倒后面能看到“更多”的按钮。
稍稍修改下正则表达式,我们只要原图。
jpg = re.compile(r'https://[^\s]*?_r\.jpg')
jpeg = re.compile(r'https://[^\s]*?_r\.jpeg')
gif = re.compile(r'https://[^\s]*?_r\.gif')
png = re.compile(r'https://[^\s]*?_r\.png')
给download函数加一个文件夹的参数,把图片存在文件夹里,然后封装一个函数,就可以一次批量下载多个URL了。
urls=['https://www.zhihu.com/question/22212644','https://www.zhihu.com/question/22212644',
'https://www.zhihu.com/question/31983868','https://www.zhihu.com/question/20399991']
for url in urls :
fetch(url)
“具体要怎么写啊老师,诶老师你干嘛去啊...”
自己写,爆照贴有新回复了,我看图去...
Final
import os
import re
import requests
def download(folder,url):
if not os.path.exists(folder):
os.makedirs(folder)
req = requests.get(url)
if req.status_code == requests.codes.ok:
name = url.split('/')[-1]
f = open("./"+folder+'/'+name,'wb')
f.write(req.content)
f.close()
return True
else:
return False
header = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
errs=[]
def fetch(url):
r = requests.get(url,headers=header)
text= r.text
imgs=[]
jpg = re.compile(r'https://[^\s]*?_r\.jpg')
jpeg = re.compile(r'https://[^\s]*?_r\.jpeg')
gif = re.compile(r'https://[^\s]*?_r\.gif')
png = re.compile(r'https://[^\s]*?_r\.png')
imgs+=jpg.findall(text)
imgs+=jpeg.findall(text)
imgs+=gif.findall(text)
imgs+=png.findall(text)
errors = []
folder = url.split('/')[-1]
for img_url in imgs:
if download(folder,img_url):
print("download :"+img_url)
else:
errors.append(img_url)
return errors
urls=['https://www.zhihu.com/question/22212644','https://www.zhihu.com/question/29814297',
'https://www.zhihu.com/question/31983868','https://www.zhihu.com/question/20399991']
for url in urls :
print(url)
errs+=fetch(url)
print("ERROR URLS:")
print(errs)
End
“老师,那我们要怎样才能获取到完整的回答啊,以及怎么把小姐姐们和照片对应起来啊”
那是下次的内容啦
“那老师下次去哪里找你啊”
关注我就好啦。我的知乎,或者我的: