一、概念
归一化(Normlization)
数据归一化就是将训练集中某一列数值特征的值缩放到0和1之间。
1、把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
2、把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
主要算法有:
(1)线性转换,即min-max归一化(常用方法)
y=(x-min)/(max-min)
(2) 对数函数转换
y=log10(x)
(3)反余切函数转换
y=atan(x)*2/PI
标准化(standardization)
数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。由于信用指标体系的各个指标度量单位是不同的,为了能够将指标参与评价计算,需要对指标进行规范化处理,通过函数变换将其数值映射到某个数值区间。
最常见的就是将训练集中某一列数值特征的值缩放成均值为0,方差为1的状态。
主要方法:
(1) z-score标准化,即零-均值标准化(常用方法)
y=(x-μ)/σ
二、标准化/归一化的好处
1、 提升模型精度
在机器学习算法的目标函数(例如SVM的RBF内核或线性模型的l1和l2正则化),许多学习算法中目标函数的基础都是假设所有的特征都是零均值并且具有同一阶数上的方差。如果某个特征的方差比其他特征大几个数量级,那么它就会在学习算法中占据主导位置,导致学习器并不能像我们说期望的那样,从其他特征中学习。
例如在KNN中,我们需要计算待分类点与所有实例点的距离。假设每个实例点(instance)由n个features构成。如果我们选用的距离度量为欧式距离,如果数据预先没有经过归一化,那么那些绝对值大的features在欧式距离计算的时候起了决定性作用。
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
2、 提升收敛速度
对于线性model来说,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
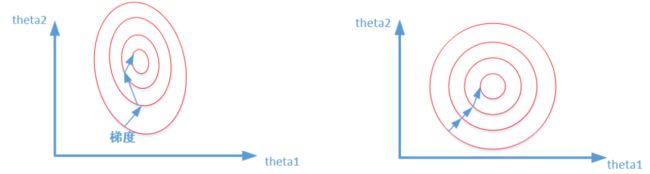
比较这两个图,前者是没有经过归一化的,在梯度下降的过程中,走的路径更加的曲折,而第二个图明显路径更加平缓,收敛速度更快。 对于神经网络模型,避免饱和是一个需要考虑的因素,通常参数的选择决定于input数据的大小范围。
三、标准化/归一化的对比分析
首先明确,在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的。原因有两点:
1、标准化更好保持了样本间距。当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。如果不幸的是1和2的分类标签还是相反的,那么,当我们用梯度下降来做分类模型训练时,模型会需要更长的时间收敛,因为将样本分开需要更大的努力!而标准化在这方面就做得很好,至少它不会将样本“挤到一起”。
2、标准化更符合统计学假设
对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是略施小技,将这个正态分布调整为均值为0,方差为1的标准正态分布而已。
四、什么时候不需要标准化/归一化
Tree-based models doesn’t depend on scaling
Non-tree-based models hugely depend on scaling
有时候,我们必须要特征在0到1之间,此时就只能用归一化。当然,也不是所有的模型都需要做归一的,比如模型算法里面有没关于对距离的衡量,没有关于对变量间标准差的衡量。比如decision tree 决策树,他采用算法里面没有涉及到任何和距离等有关的,所以在做决策树模型时,通常是不需要将变量做标准化的。
五、sklearn代码实现
python三方包sklearn提供了方便的接口来进行数据的预处理——标准化和归一化。
1、标准化
函数 scale 为数组形状的数据集的标准化提供了一个快捷实现:
>>> from sklearn import preprocessing
>>> import numpy as np
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
>>> X_scaled = preprocessing.scale(X_train)
>>> X_scaled
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])
经过缩放后的数据具有零均值以及标准方差:
array([ 0., 0., 0.])
>>> X_scaled.std(axis=0)
array([ 1., 1., 1.])
preprocessing 模块还提供了一个实用类 StandardScaler ,它实现了转化器的API来计算训练集上的平均值和标准偏差,以便以后能够在测试集上重新应用相同的变换:
>>> scaler = preprocessing.StandardScaler().fit(X_train)
>>> scaler
StandardScaler(copy=True, with_mean=True, with_std=True)
>>> scaler.mean_
array([ 1. ..., 0. ..., 0.33...])
>>> scaler.scale_
array([ 0.81..., 0.81..., 1.24...])
>>> scaler.transform(X_train)
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])
缩放类对象可以在新的数据上实现和训练集相同缩放操作:
>>>
>>> X_test = [[-1., 1., 0.]]
>>> scaler.transform(X_test)
array([[-2.44..., 1.22..., -0.26...]])
fit、fit_transform和transform的用法区别:
fit函数直接对数据集进行标准化,而fit_transform则是不仅对数据集进行处理(fit),还会存储fit的参数,然后transform使用储存好的相同参数对别的数据进行处理。
2、归一化
使用 MinMaxScaler 和 MaxAbsScaler 可以方便的实现归一化。
使用这种缩放的目的包括实现特征极小方差的鲁棒性以及在稀疏矩阵中保留零元素。
以下是一个将简单的数据矩阵缩放到[0, 1]的例子:
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
同样的转换实例可以被用与在训练过程中不可见的测试数据:实现和训练数据一致的缩放和移位操作:
>>> X_test = np.array([[ -3., -1., 4.]])
>>> X_test_minmax = min_max_scaler.transform(X_test)
>>> X_test_minmax
array([[-1.5 , 0. , 1.66666667]])
类 MaxAbsScaler 的工作原理非常相似,但是它只通过除以每个特征的最大值将训练数据特征缩放至 [-1, 1] 范围内,这就意味着,训练数据应该是已经零中心化或者是稀疏数据。 例子::用先前例子的数据实现最大绝对值缩放操作。
3、 缩放单个样本以具有单位范数
函数 normalize 提供了一个快速简单的方法在类似数组的数据集上执行操作。
这个目前还不太懂,以后再进行补充。
参考:
Sklearn官方文档
[机器学习] 数据特征 标准化和归一化你了解多少?